Stay tuned – R package coming soon!
20.10.2025 17:20 —
👍 6
🔁 1
💬 1
📌 0

In our theory, we show how the estimator’s bias depends on product of imbalance across units, time and bias of the regression adjustment, so that effectively only one of these three needs to be small. This gives flexibility in the choice of unit, time weights and outcome model.
20.10.2025 17:20 —
👍 0
🔁 0
💬 1
📌 0
This isn't surprising if it’s common that heterogeneity across units can be approximated with a few unobserved factors and the impact of each factor varies over time. This implies that we shouldn't assign the same weights to units far in time and we should accurately model interactive fixed effects.
20.10.2025 17:20 —
👍 0
🔁 0
💬 1
📌 0
We find substantial heterogeneity in performance of common methods. TROP outperforms all competitors in 20 of 21 simulation designs. Empirically additive time and unit effects rarely capture all of the predictable patterns. Instead interactive latent factor structures often fit the data much better
20.10.2025 17:20 —
👍 0
🔁 0
💬 1
📌 0

In contrast, TROP embeds all these estimators as special cases, while it learns which components of such estimators are most relevant to accurately predict the counterfactual. We evaluate TROP through a large set of simulation studies calibrated to match real-world applications.
20.10.2025 17:20 —
👍 0
🔁 0
💬 1
📌 0

Why this matters: TROP learns the combination of time, unit weights and regression adjustments that most accurately predict the counterfactual as below. Common estimators of causal effects in panel data (DID/TWFE, SC, MC, SDID) rest on different assumptions, but all can fail in applications.
20.10.2025 17:20 —
👍 0
🔁 0
💬 1
📌 0
TROP is “triply robust” – error is the product of the errors in the three components: imbalance betw/ treated and control periods, betw/ treated and control units and and misspecification of the regression adjustment (only one needs to perform well)
20.10.2025 17:20 —
👍 0
🔁 0
💬 1
📌 0
TROP estimates causal effects in panel models by combining (i) a flexible outcome model (regularized low-rank factors + FE), (ii) unit weights, and (iii) time weights.
20.10.2025 17:20 —
👍 0
🔁 0
💬 1
📌 0

New paper: Triply Robust Panel Estimators (TROP) by @susanathey.bsky.social @guidoimbens.bsky.social Zhaonan Qu @vivianodavide.bsky.social.
arxiv.org/pdf/2508.21536
20.10.2025 17:20 —
👍 25
🔁 5
💬 1
📌 8
New Paper Alert! Read the thread below for key takeaways from “Does Q&A Boost Engagement? Health Messaging Experiments in the United States and Ghana” by @erikakirgios.bsky.social @susanathey.bsky.social @angeladuckworth.bsky.social et al.
07.10.2025 16:48 —
👍 0
🔁 0
💬 0
📌 0

A Century of Impact
In 1925, Herbert Hoover, a Stanford alum and future U.S. president, had an idea. “A graduate School of Business Administration is urgently needed upon the Pacific Coast,” he wrote.
During the @gsb.stanford.edu 100 Faculty Celebration of Scholarship @susanathey.bsky.social highlighted the GSB’s proud tradition of synergy between business and practice during her presentation. Listen to her thoughts and more in the podcast: stanford.io/3K8mcrz
03.10.2025 17:32 —
👍 0
🔁 0
💬 0
📌 0

Earlier this month @susanathey.bsky.social joined Stanford University President Levin, @siepr.bsky.social Director @nealemahoney.bsky.social and other distinguished faculty to connect over cutting-edge research developments at Stanford Open Minds New York.
24.09.2025 18:15 —
👍 5
🔁 2
💬 1
📌 0

Listen to Raj Chetty talk about how surrogate indices make it possible to make decisions more quickly using multiple short-term outcomes to predict long-term effects with @nber.org
www.nber.org/research/vid...
27.08.2025 18:33 —
👍 5
🔁 1
💬 1
📌 0

Service Quality on Online Platforms: Empirical Evidence about Driving Quality at Uber
Founded in 1920, the NBER is a private, non-profit, non-partisan organization dedicated to conducting economic research and to disseminating research findings among academics, public policy makers, an...
Learn more about how ratings, measurement, nudges, and dashboards are used to support service quality on online platforms in the paper by @susanathey.bsky.social, Juan Camilo Castillo, & Bharat Chandar
www.nber.org/papers/w33087
22.08.2025 19:09 —
👍 0
🔁 0
💬 0
📌 0

How Uber Steers Its Drivers Toward Better Performance
Check out @susanathey.bsky.social’s interview on how AI-powered after-the-fact quality checks boost driver performance at Uber—and what it means when AI can track compliance. Insights via @StanfordGSB.
www.gsb.stanford.edu/insights/how...
22.08.2025 19:08 —
👍 3
🔁 3
💬 1
📌 0
YouTube video by SAReserveBank
#G20SouthAfrica Side event — The implications of Al on the organisation of industry and work
Watch @Susan_Athey’s talk on the implications of AI on the organisation of industry and work at #G20SouthAfrica
www.youtube.com/watch?v=okDG...
18.07.2025 13:06 —
👍 1
🔁 2
💬 0
📌 1
“Governments will play a key role…in whether we actually develop the technology that will help lower-skilled workers become more productive by using AI to augment them with expertise that previously was difficult to acquire.”
18.07.2025 13:06 —
👍 3
🔁 2
💬 1
📌 0
The talk will cover:
✔️How AI is altering industry dynamics & structures
✔️How these shifts will impact public services such as health and education
✔️How AI market concentration could tax the global economy
✔️Why govt policy will be crucial in shaping AI competition and innovation
15.07.2025 13:42 —
👍 0
🔁 0
💬 0
📌 0

AI & digitisation are rapidly reshaping the way we work.
Policymakers need to understand how, and what to do about it.
Watch @Susan_Athey speak to G20 leaders about these issues tomorrow 16 July @ 13:30 CET. #G20SouthAfrica
bit.ly/3GyMFgm or bit.ly/44PTXFP
15.07.2025 13:42 —
👍 0
🔁 0
💬 1
📌 0
Beyond predictions, @keyonv.bsky.social also worked with @gsbsilab.bsky.social to show how these models can be used to make better estimations of important problems, such as the gender wage gap among men and women with the same career histories. Learn more here: bsky.app/profile/gsbs...
30.06.2025 15:39 —
👍 0
🔁 0
💬 0
📌 0
Keyon Vafa: Predicting Workers’ Career Trajectories to Better Understand Labor Markets
If we know someone’s career history, how well can we predict which job they’ll have next?
If we know someone’s career history, how well can we predict which jobs they’ll have next? Read our profile of @keyonv.bsky.social to learn how ML models can be used to predict workers’ career trajectories & better understand labor markets.
medium.com/@gsb_silab/k...
30.06.2025 15:39 —
👍 9
🔁 2
💬 1
📌 0
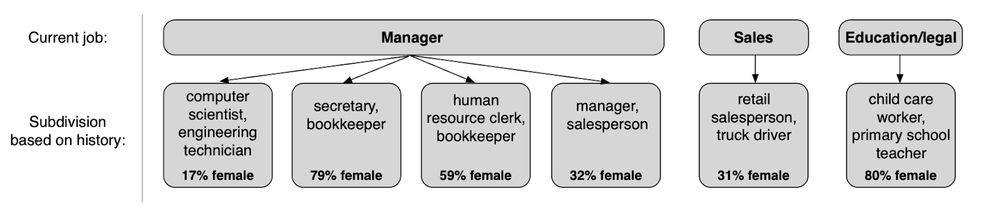
Analyzing representations tells us where history explains the gap.
Ex: there are two kinds of managers: those who used to be engineers and those who didn’t. The first group gets paid more and has more males than the second.
Models that don’t use history omit this distinction.
30.06.2025 12:15 —
👍 0
🔁 0
💬 1
📌 0
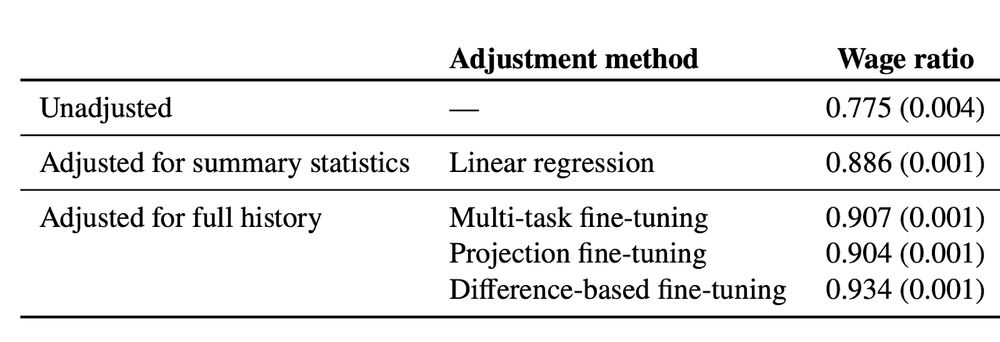
We use these methods to estimate wage gaps adjusted for full job history, following the literature on gender wage gaps.
History explains a substantial fraction of the remaining wage gap when compared to simpler methods. But there’s still a lot that history can’t account for.
30.06.2025 12:15 —
👍 0
🔁 0
💬 1
📌 0
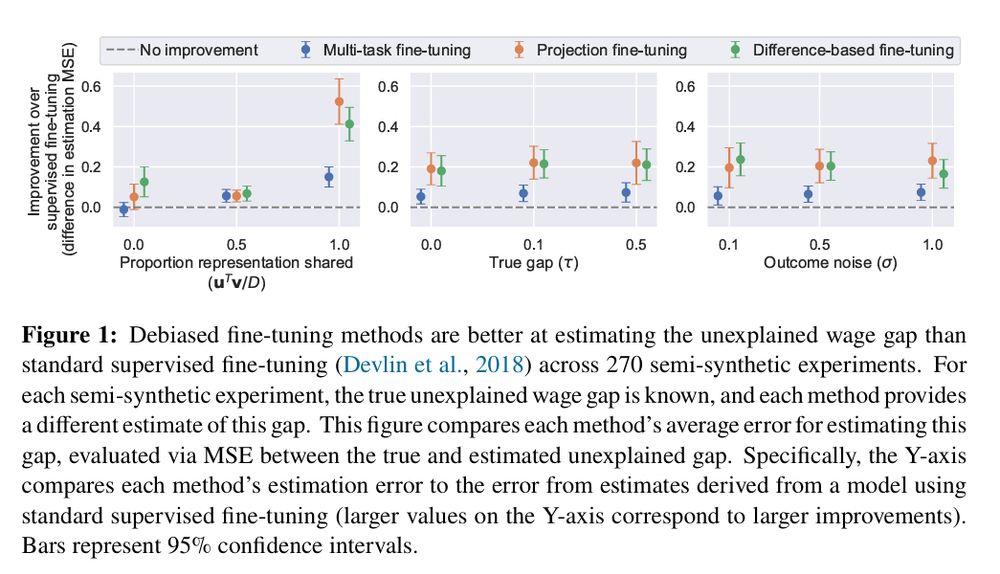
This result motivates new fine-tuning strategies.
We consider 3 strategies similar to methods from the causal estimation literature. E.g. optimize representations to predict the *difference* in male-female wages instead of individual wages.
All perform well on synthetic data.
30.06.2025 12:15 —
👍 0
🔁 0
💬 1
📌 0
Two extremes:
A representation that's just the identity function meets condition (1) trivially but not (2).
A representation that uses a very simple summary of history (e.g. # of years worked) should meet (2) but fails (1)
30.06.2025 12:15 —
👍 0
🔁 0
💬 1
📌 0

New result: Fast + consistent estimates are possible even if a representation drops info
Two main fine-tuning conditions:
1. Representation only drops info that isn't correlated w/ both wage & gender
2. Representation is simple enough that it’s easy to model wage & gender from it
30.06.2025 12:15 —
👍 0
🔁 0
💬 1
📌 0
Intuition: If working in job X at some point has a small effect on wages, but men are much likelier to have worked in job X than women, it may be omitted by a model optimized to predict wage.
30.06.2025 12:15 —
👍 0
🔁 0
💬 1
📌 0

Foundation models are usually fine-tuned to make predictions (like wages).
But representations fine-tuned this way can induce omitted variable bias: the gap adjusted for full history can be different from the gap adjusted for the representation of job history.
30.06.2025 12:15 —
👍 0
🔁 0
💬 1
📌 0


