

✔️ Supporting enterprise-scale document processing
✔️ Enabling more accurate retrieval for AI-generated responses
Kudos to @nohtow.bsky.social for this new SOTA achievement!
🔗 Read the full blog article: www.lighton.ai/lighton-blog...
✔️ Supporting enterprise-scale document processing
✔️ Enabling more accurate retrieval for AI-generated responses
Kudos to @nohtow.bsky.social for this new SOTA achievement!
🔗 Read the full blog article: www.lighton.ai/lighton-blog...

ColBERT (a.k.a. multi-vector, late-interaction) models are extremely strong search models, often outperforming dense embedding models. And @lightonai.bsky.social just released a new state-of-the-art one: GTE-ModernColBERT-v1!
Details in 🧵
I'm a big fan of the PyLate project for ColBERT models, and I'm glad to see these strong models coming out. Very nice work by the @lightonai.bsky.social folks, especially @nohtow.bsky.social.
Learn more about PyLate here: lightonai.github.io/pylate/
As per usual, thanks to my dear co-maintainer @raphaelsty.bsky.social for helping me make PyLate what it is 🫶
30.04.2025 14:42 — 👍 1 🔁 0 💬 0 📌 0In addition to knowledge distillation, we recently added features to allow large-scale contrastive pre-training, and this model has been released upon popular demand, but we are currently doing heavier training so stay tuned!
30.04.2025 14:42 — 👍 1 🔁 0 💬 1 📌 0

PyLate makes downstream usage easy, but also facilitate training!
You can reproduce this SOTA training with <80 LoC and 2 hours of training and it'll run NanoBEIR during training, report it to W&B and create an informative model card!
Link to the gist: gist.github.com/NohTow/3030f...
Besides, it also comes with the 8k context window of ModernBERT, which is very useful given that late interaction models generalize very well to longer context as highlighted in the ModernBERT paper
It is thus very suited to handle your very long documents!

It is also the first model to outperform ColBERT-small on BEIR
While it is bigger, it is still a very lightweight model and benefits from the efficiency of ModernBERT!
Also, it has only been trained on MS MARCO (for late interaction) and should thus generalize pretty well!

Model link: huggingface.co/lightonai/GT...
GTE-ModernColBERT is trained on top of the GTE-ColBERT model using knowledge distillation on the MS MARCO dataset and is the first SOTA model trained using PyLate!
Get started with PyLate using the documentation:
lightonai.github.io/pylate/

Among all those LLM releases, here is an important retrieval release:
To overcome limitations of awesome ModernBERT-based dense models, today @lightonai.bsky.social is releasing GTE-ModernColBERT, the very first state-of-the-art late-interaction (multi-vectors) model trained using PyLate 🚀

ModernBERT-embed-large is released under Apache 2.0 and is available on Hugging Face:
huggingface.co/lightonai/mo...
Congrats to @nohtow.bsky.social for this great work!
When I saw the release of ModernBERT-embed during the holidays, I knew I had to build the large variant, so I wanted to thank Zach Nussbaum from Nomic AI for building and sharing it (as well as all the nomic-embed tools and data) and bearing with me during the training!
14.01.2025 15:32 — 👍 2 🔁 0 💬 0 📌 0ModernBERT-embed-large not only enables usage of ModernBERT-large out-of-the-box, but it should also be a very good starting point for strong fine-tunings on various tasks, so I can't wait to see what the community will build on top of it!
14.01.2025 15:32 — 👍 1 🔁 0 💬 1 📌 0
Obviously, it comes at a slightly higher cost, but it is also trained with Matryoshka capabilities to reduce the footprint of embeddings
Notably, the performance with dimension 256 is only slightly worse than the base version with full dimension 768

Model link: huggingface.co/lightonai/mo...
ModernBERT-embed-large is trained using the same (two-stage training) recipe as its smaller sibling and expectedly increases the performance, reaching +1.22 in MTEB average
ModernBERT-embed-base is awesome because it allows to use ModernBERT-base for various tasks out-of-the-box
But the large variant of ModernBERT is also awesome...
So today, @lightonai.bsky.social is releasing ModernBERT-embed-large, the larger and more capable iteration of ModernBERT-embed!

The multilingual version is not planned yet, there have been a work on adapting ModernBERT to other languages:
www.linkedin.com/posts/fremyc...
In the mean time, you could have a shot with mGTE (using xformers) or recent language-specific iteration of BERT such as CamemBERTv2!

Today, LightOn releases ModernBERT, a SOTA model for retrieval and classification.
This work was performed in collaboration with Answer.ai and the model was trained on Orange Business Cloud Avenue infrastructure.
www.lighton.ai/lighton-blog...
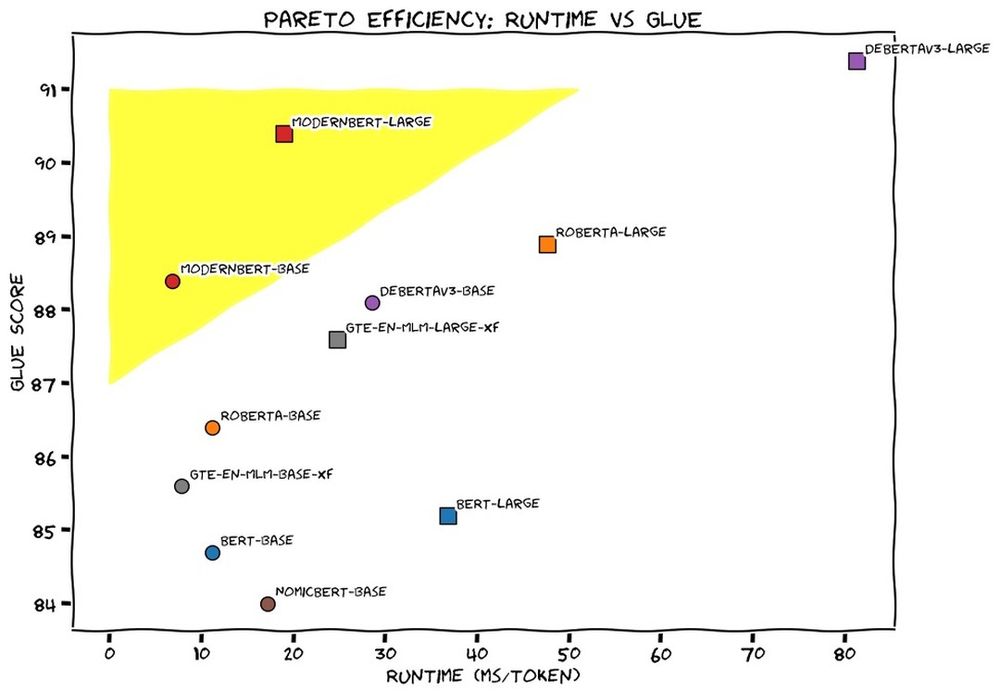
This week we released ModernBERT, the first encoder to reach SOTA on most common benchmarks across language understanding, retrieval, and code, while running twice as fast as DeBERTaV3 on short context and three times faster than NomicBERT & GTE on long context.
22.12.2024 06:12 — 👍 74 🔁 15 💬 2 📌 2When one evaluates log-likelihood of a sequence of length L via the chain rule of probability, the first term has missingness fraction of 1, the second has missingness of (L-1)/L, etc. So the inference-time masking rate is ~ Uniform[0, 1].
20.12.2024 19:52 — 👍 1 🔁 1 💬 2 📌 0
Oh, I see!
Having also worked a lot on causal models, I never thought of this kind of modelling because I always opposed MLM to open ended generation
I guess with papers such as this one arxiv.org/pdf/2406.04823, I should more!
Very interesting perspective, thanks!
Could you elaborate?
Or give me pointers?
Is it because having a fixed value bias the learning w.r.t the way we will sample downstream? (Like not mask 30% of the target?)
But there is definitely some diggings to be made to find an optimal strategy in this regard
To me the logic would be to ramp up to have a kick off signal and make it harder and harder but papers seems to say otherwise
Maybe random is the optimal solution!
Not really, we considered ramping up/down the masking ratio, but the findings from the literature (at least what we read at time) seemed counter-intuitive/not consensual
We ended up not really digging much into this particular aspect, again because we had so much to explore
Definitely!
Again, the original goal of the project (besides cool models) was to convince some researchers to spend a bit of their GPUs hours on encoders pre-training again!
Hopefully we nailed it and will have the answers to a lot of questions in the future!
As you can see in the paper, we did _a lot_ of ablations (with even more not making it into the paper actually), but there is still so much to be explored, we hope ModernBERT will encourage people exploring these avenues!
19.12.2024 21:12 — 👍 1 🔁 0 💬 1 📌 0
We did not try to go beyond this vocab size because:
First, for small encoders, this is a non negligible part of the total params count
Second, we discussed training our own tokenizer but at some point lacked time and I am not sure we had discussed existing tokenizer with bigger vocab size
Thanks!
As mentioned in the paper, we tested the tokenizers from OLMo, BERT RoBERTa and Llama
They were all pretty much equivalent except Llama that was underperforming. We went for OLMo because of the distribution it was trained on and code tokens
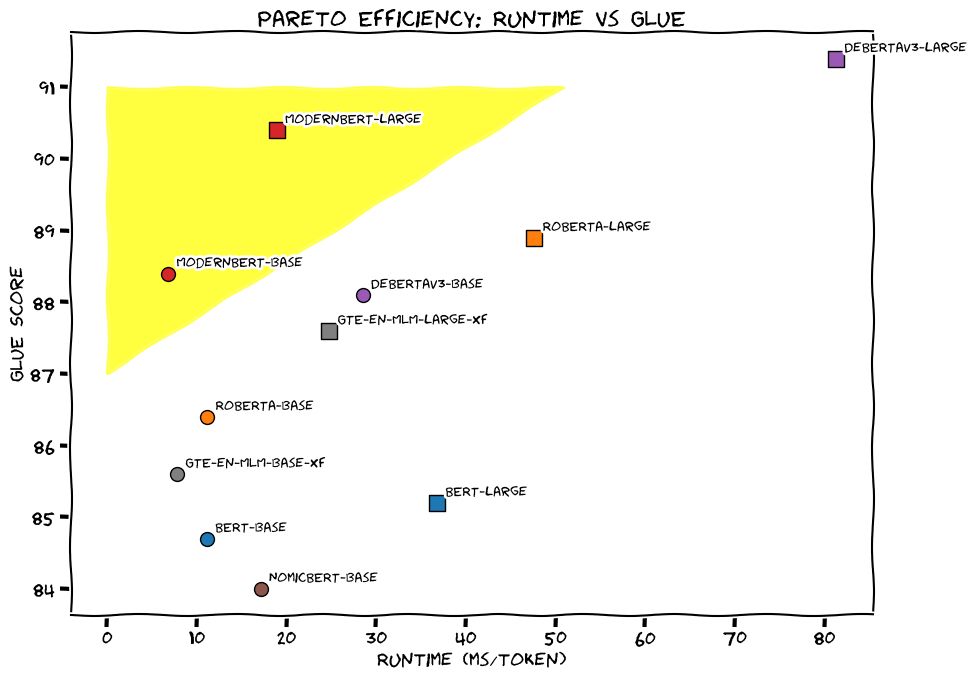
BERT is BACK! I joined a collaboration with AnswerAI and LightOn to bring you the next iteration of BERT.
Introducing ModernBERT: 16x larger sequence length, better downstream performance (classification, retrieval), the fastest & most memory efficient encoder on the market.
🧵
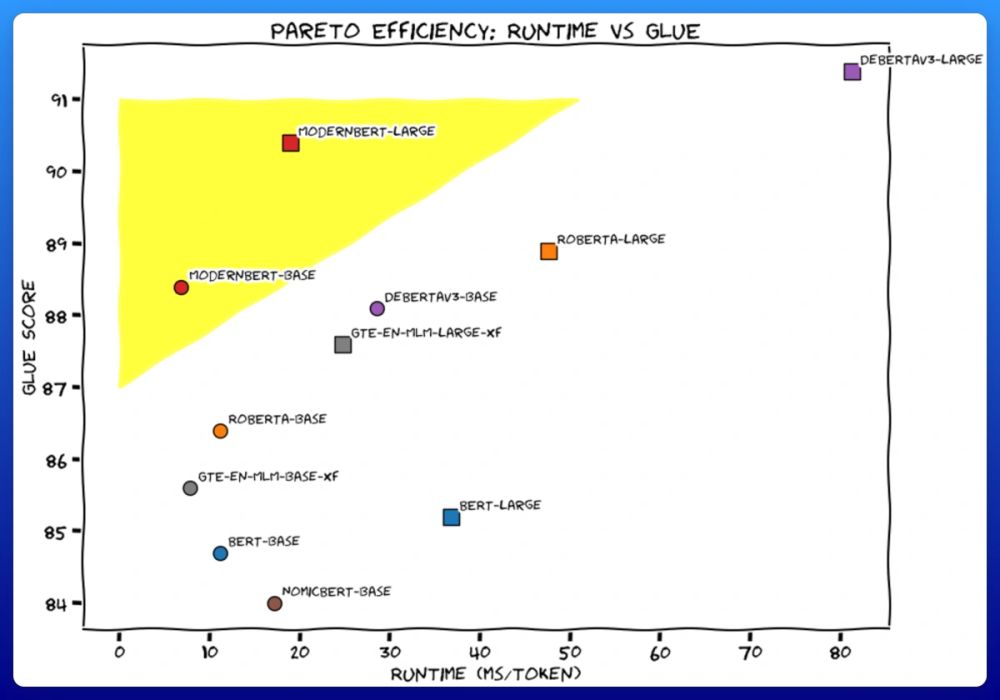
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵