
I mean, it makes sense. If sky-net rules over everything, then Prince Harry will not be prince anymore.
22.10.2025 22:33 — 👍 2 🔁 0 💬 0 📌 0I mean, it makes sense. If sky-net rules over everything, then Prince Harry will not be prince anymore.
22.10.2025 22:33 — 👍 2 🔁 0 💬 0 📌 0Yes
19.10.2025 01:17 — 👍 1 🔁 0 💬 0 📌 0
3. This allows us to compute the eigenvalues of the Fourier transform exactly, and hence its spectral norm.
Furthermore, we show that the mixing time of the random walk for our family is tight.
2. Remarkably, this Fourier transform is governed entirely by the standard representation of the group. Using tools from group and representation theory, the entire analysis collapses to that single representation.
18.10.2025 21:38 — 👍 1 🔁 0 💬 2 📌 0
Main proof technique.
We couple two machines from this family as a random walk on the group S_n x S_n and show that, with high probability, they are indistinguishable. How?
1. Indistinguishability is controlled by the spectral norm of the Fourier transform of the walk’s single-step distribution.

We construct a large randomized family of shuffling machines. Each machine shuffles its input using only transpositions. By flipping a random coin to decide whether to apply or ignore each transposition, we obtain a randomized family with the desired properties.
18.10.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0We show that SQ hardness can be established when both the alphabet size and input length are polynomial in the number of states.
18.10.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0We prove the first SQ hardness result for learning semiautomata under the uniform distribution over input words and initial states, without relying on parity gadgets or adversarial inputs. The hardness is structural, it arises purely from the transition structure, not from hard languages.
18.10.2025 21:38 — 👍 1 🔁 0 💬 1 📌 0
On the Statistical Query Complexity of Learning Semiautomata: a Random Walk Approach
Link to the paper: arxiv.org/abs/2510.04115
Done.
09.06.2025 15:11 — 👍 0 🔁 0 💬 0 📌 0
I wrote a blog post about it.
Link: medium.com/@kimon.fount...
2) Can a neural network discover instructions for performing multiplication itself?
The answer to the first question is yes, with high probability and up to some arbitrary, predetermined precision (see the quoted post).

Link to the paper: arxiv.org/abs/2502.16763
Link to the repository: github.com/opallab/bina...
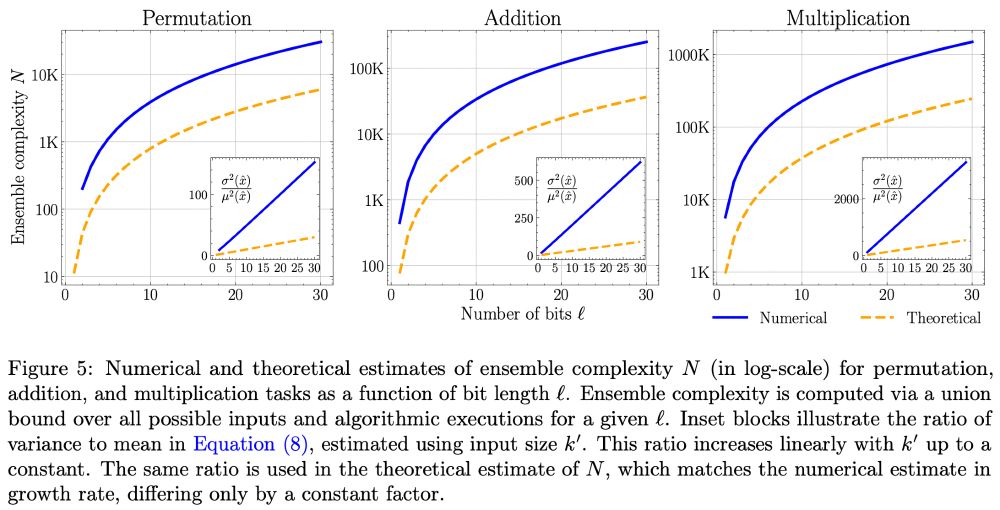
Learning to execute arithmetic exactly, with high probability, can be quite expensive. In the plot, 'ensemble complexity' refers to the number of independently trained models required to achieve exact learning with high probability. ell is the number of bits per number in the input.
26.05.2025 03:21 — 👍 0 🔁 0 💬 1 📌 0
New paper: Learning to Add, Multiply, and Execute Algorithmic Instructions Exactly with Neural Networks
26.05.2025 03:21 — 👍 5 🔁 1 💬 1 📌 1
Learning to execute arithmetic exactly, with high probability, can be quite expensive. In the plot, 'ensemble complexity' refers to the number of independently trained models required to achieve exact learning with high probability. ell is the number of bits per number in the input.
26.05.2025 03:19 — 👍 0 🔁 0 💬 0 📌 0I never understood the point of trams. They're slow and expensive. I've been to two cities that built them while I was there, Edinburgh and Athens, and in both cases, the projects were born out of corruption. Especially in Edinburgh, it was a disaster. en.wikipedia.org/wiki/Edinbur...
21.05.2025 14:39 — 👍 0 🔁 0 💬 1 📌 0Thanks, the connection to formal languages is quite interesting. I have a section in the repo regarding formal languages but it's small mainly because it's not a topic that I am familiar with. I will add them!
17.05.2025 11:49 — 👍 0 🔁 0 💬 0 📌 0Update, 14 empirical papers added!
16.05.2025 17:26 — 👍 3 🔁 0 💬 0 📌 0
The SIAM Conference on Optimization 2026 will be in Edinburgh! I don’t really work on optimization anymore (at least not directly), but it’s cool to see a major optimization conference taking place where I did my PhD.
15.05.2025 13:32 — 👍 1 🔁 0 💬 0 📌 0
Currently NeurIPS has 21390 submissions. The final number last year was 15671.
Observation made by my student George Giapitzakis.


Got a pin this morning
Einstein problem: en.wikipedia.org/wiki/Einstei...
Our new work on scaling laws that includes compute, model size, and number of samples. The analysis involves an extremely fine-grained analysis of online sgd built up over the last 8 years of understanding sgd on simple toy models (tensors, single index models, multi index model)
05.05.2025 17:08 — 👍 5 🔁 1 💬 0 📌 0
Hey, I definitely predicted this correctly.
01.05.2025 20:42 — 👍 0 🔁 0 💬 0 📌 0ChatGPT gives me the ability to expand my search capabilities on topics that I can only roughly describe, or even illustrate with a figure, when I don’t know the exact keywords to use in a Google search.
01.05.2025 17:58 — 👍 0 🔁 0 💬 0 📌 0
That's a comprehensive study on the expressivity for parallel algorithms, their in- and out-of-distribution learnability, and it includes a lot of experiments.
link: arxiv.org/abs/2410.01686
Positional Attention is accepted at ICML 2025! Thanks to all co-authors for the hard work (64 pages). If you’d like to read the paper, check the quoted post.
01.05.2025 13:22 — 👍 7 🔁 1 💬 1 📌 0
NeurIPS 2026 in the Cyclades. Just saying.
29.04.2025 18:12 — 👍 4 🔁 0 💬 0 📌 0