In summary, this work provides a novel flexible framework for studying learning in linear RNNs, allowing us to generate new insights into their learning process and the solutions they find, and progress our understanding of cognition in dynamic task settings.
20.06.2025 17:28 — 👍 2 🔁 0 💬 0 📌 0
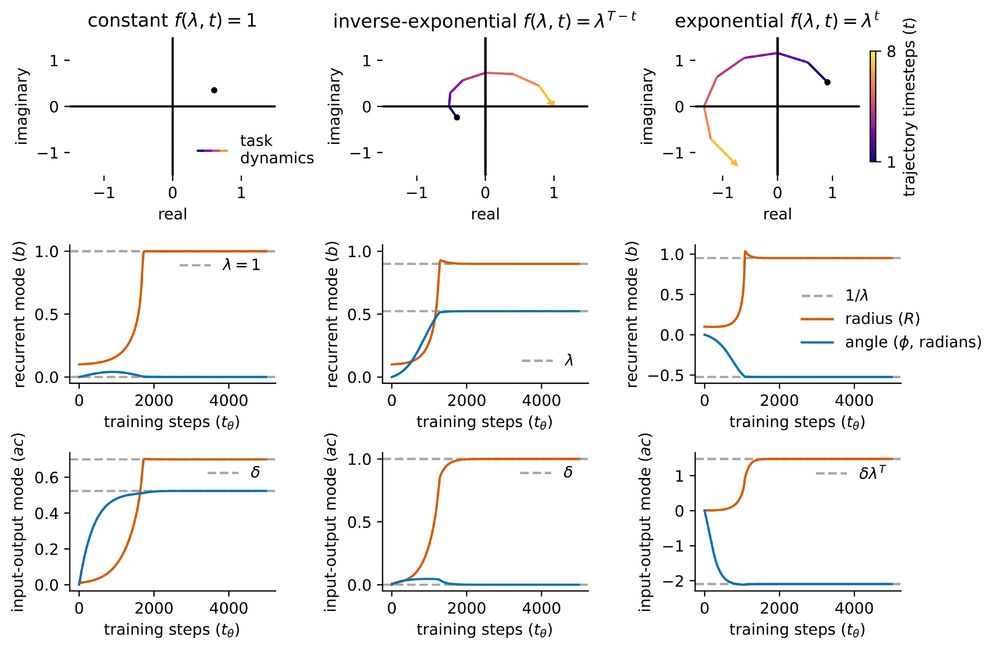
Finally, although many results we present are based on SVD, we also derive a form based on an eigendecomposition, allowing for rotational dynamics and to which our framework naturally extends to. We use this to study learning in terms of polar coordinates in the complex plane.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
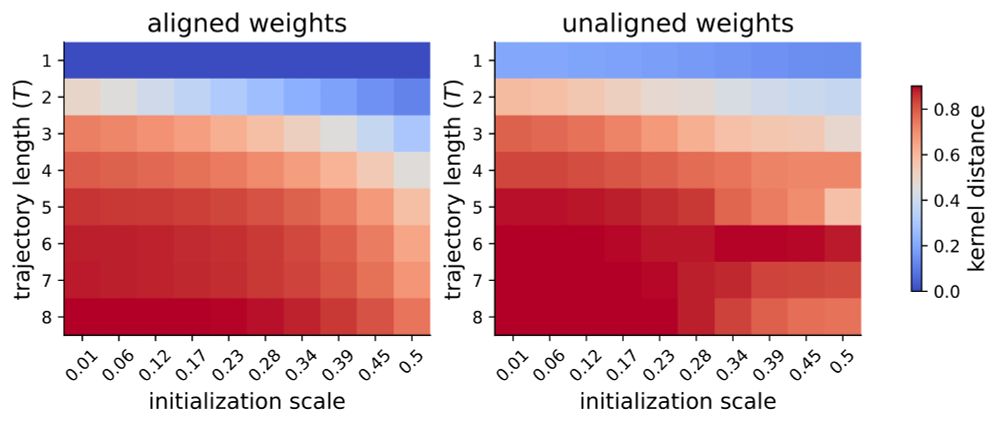
To study how recurrence might impact feature learning, we derive the NTK for finite-width LRNNs and evaluate its movement during training. We find that recurrence appears to facilitate kernel movement across many settings, suggesting a bias towards rich learning.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
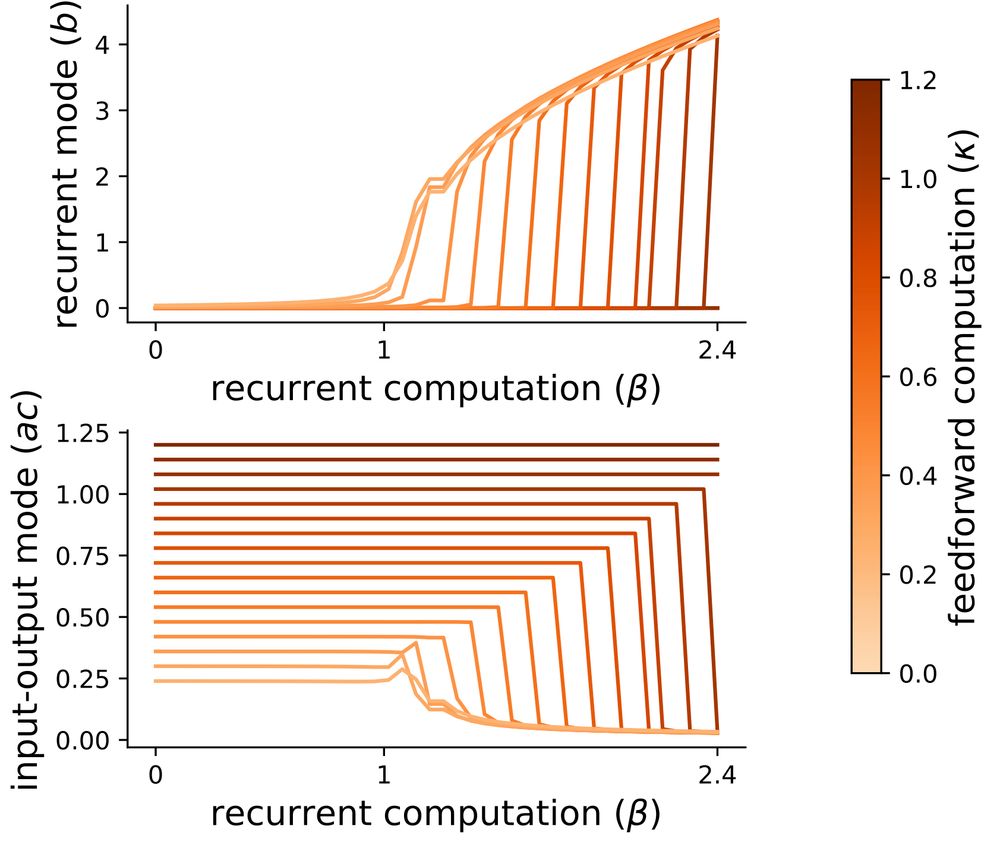
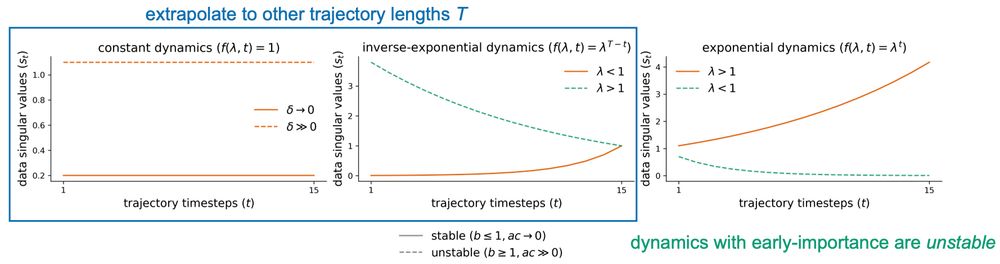
Motivated by this, we study task dynamics without zero-loss solutions and find that there exists a tradeoff between recurrent and feedforward computations that is characterized by a phase transition and leads to low-rank connectivity.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
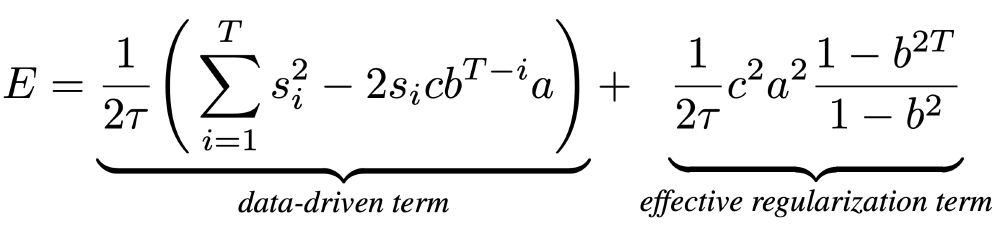
By analyzing the energy function, we identify an effective regularization term that incentivizes small weights, especially when task dynamics are not perfectly learnable.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
Additionally, these results predict behavior in networks performing integration tasks, where we relax our theoretical assumptions.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
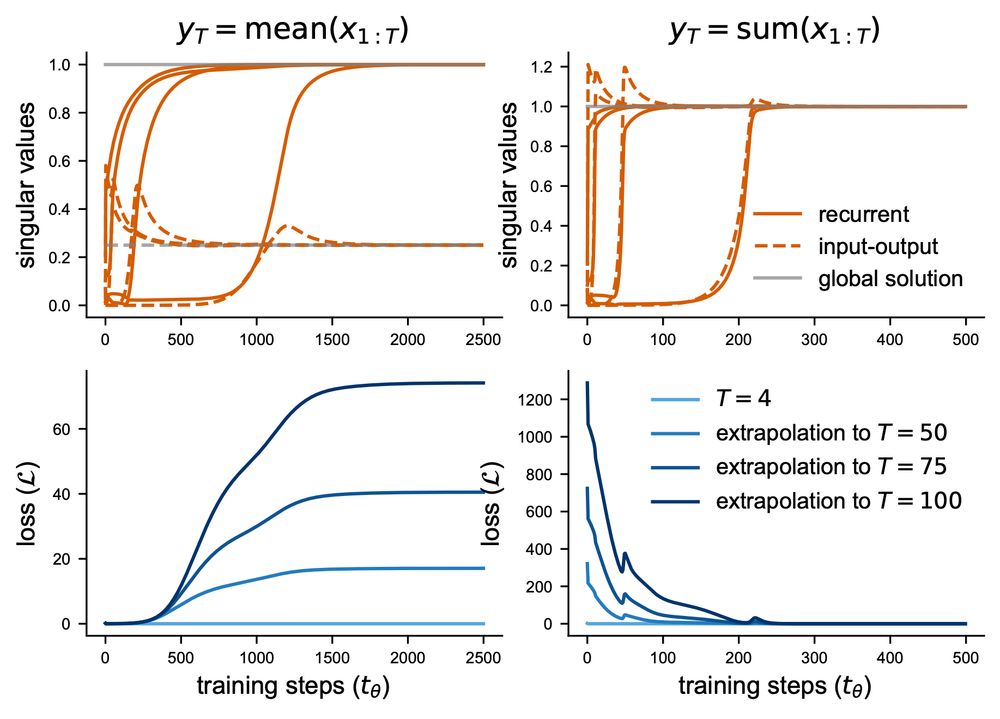
Next, we show that task dynamics determine a RNN’s ability to extrapolate to other sequence lengths and its hidden layer stability, even if there exists a perfect zero-loss solution.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
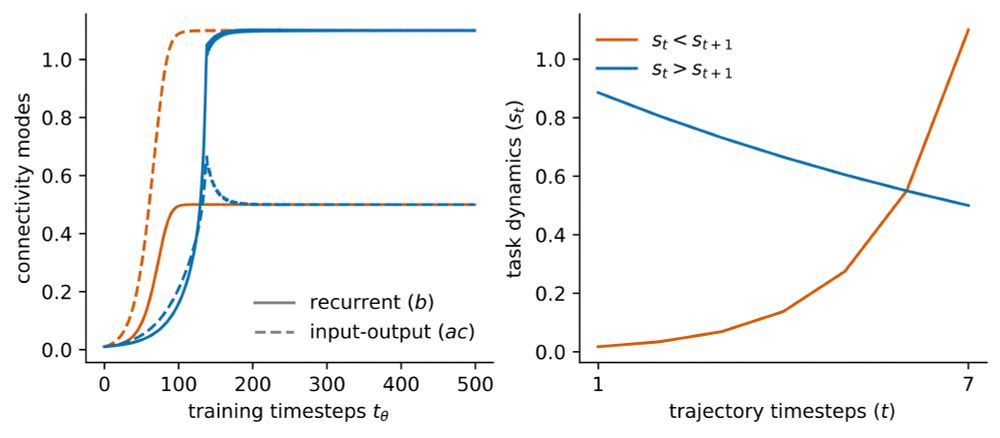
We find that learning speed is dependent on both the scale of SVs and their temporal ordering, such that SVs occurring later in the trajectory have a greater impact on learning speed.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
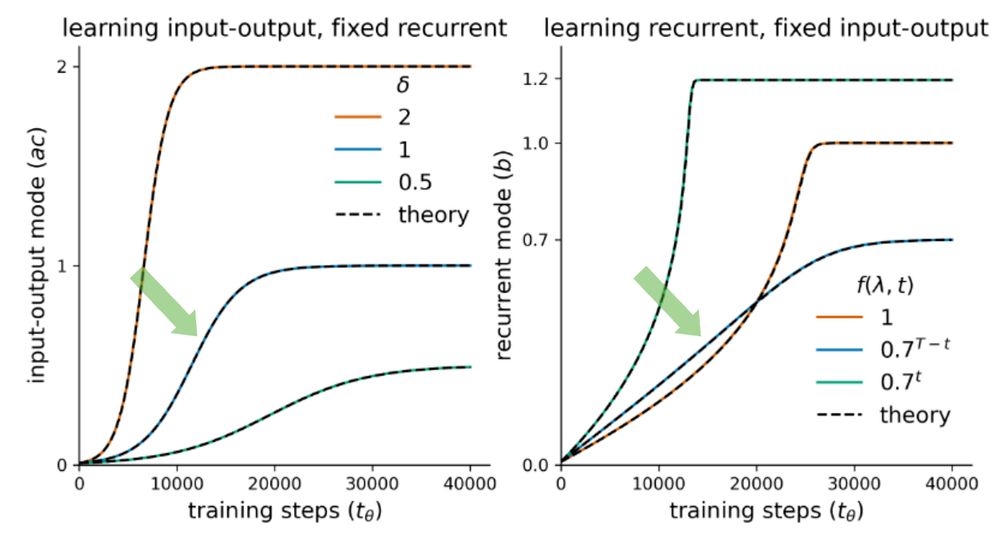
Using this form, we derive solutions to the learning dynamics of the input-output modes and local approximations of the recurrent modes separately, and identify differences in the learning dynamics of recurrent networks compared to feedforward ones.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
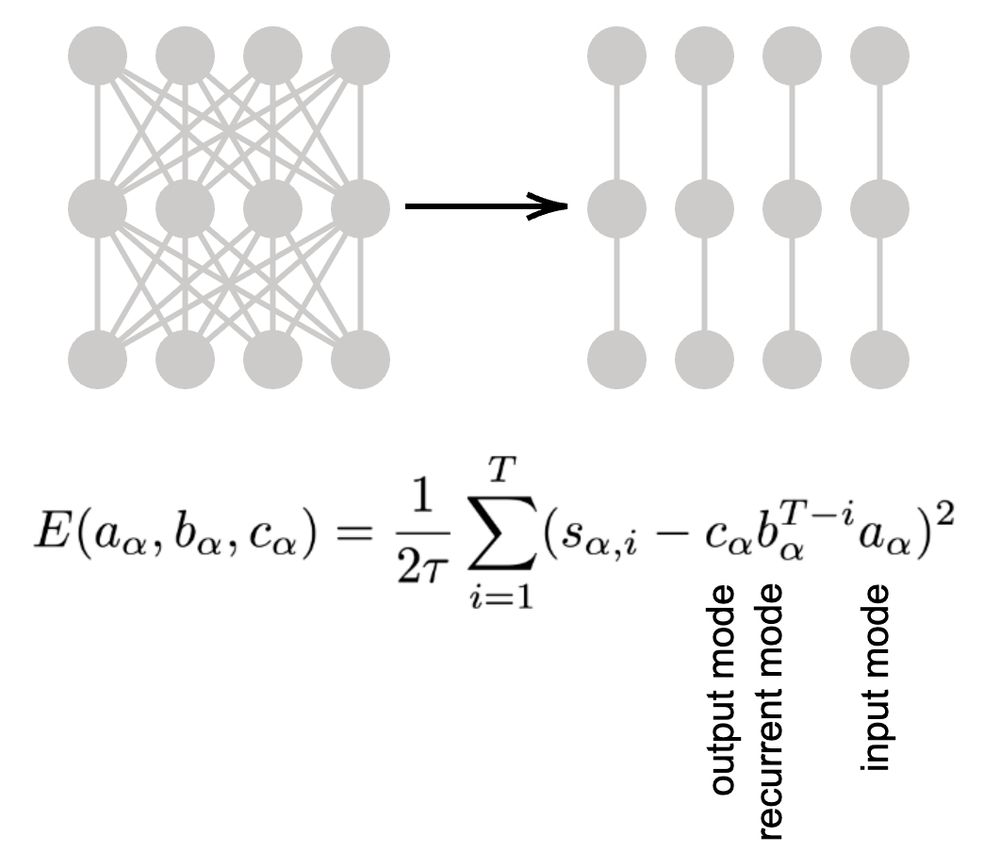
We derive a form where the task dynamics are fully specified by the data correlation singular values (or eigenvalues) across time (t=1:T), and learning is characterized by a set of gradient flow equations and energy function that are decoupled across different dimensions.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
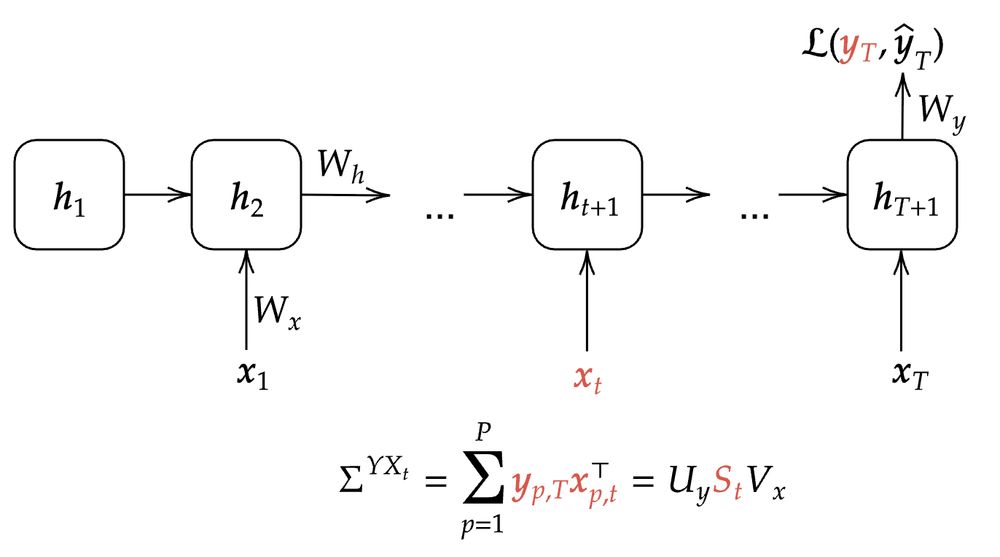
We study a RNN that receives an input at each timestep and produces a final output at the last timestep (and generalize to the autoregressive case later). For each input at time t and the output, we can construct correlation matrices and compute their SVD (or eigendecomposition).
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0
RNNs are popular in both ML and neuroscience to learn tasks with temporal dependencies and model neural dynamics. However, despite substantial work on RNNs, it's unknown how their underlying functional structures emerge from training on temporally-structured tasks.
20.06.2025 17:28 — 👍 2 🔁 0 💬 1 📌 0

🚀 An other Exciting news! Our paper "From Lazy to Rich: Exact Learning Dynamics in Deep Linear Networks" has been accepted at ICLR 2025!
arxiv.org/abs/2409.14623
A thread on how relative weight initialization shapes learning dynamics in deep networks. 🧵 (1/9)
04.04.2025 14:45 — 👍 30 🔁 9 💬 1 📌 0
Had a really fun time collaborating on this project with a great team. I’ll be at NeurIPs next week to present it, come by and check out our paper for more!
04.12.2024 10:52 — 👍 2 🔁 0 💬 0 📌 0

Thrilled to share our NeurIPS Spotlight paper with Jan Bauer*, @aproca.bsky.social*, @saxelab.bsky.social, @summerfieldlab.bsky.social, Ali Hummos*! openreview.net/pdf?id=AbTpJ...
We study how task abstractions emerge in gated linear networks and how they support cognitive flexibility.
03.12.2024 16:04 — 👍 64 🔁 15 💬 2 📌 1
🙋♀️
22.11.2024 23:21 — 👍 0 🔁 0 💬 1 📌 0
phd student neuro theory @technion
Neuroscientist, in theory. Studying sleep and navigation in 🧠s and 💻s.
Incoming Assistant Professor at Yale Neuroscience, Wu Tsai Institute.
An emergent property of a few billion neurons, their interactions with each other and the world over ~1 century.
Postdoc in the Litwin-Kumar lab at the Center for Theoretical Neuroscience at Columbia University.
I'm interested in multi-tasking and dimensionality.
currently teaching myself math | https://btromm.github.io
prev: @institutducerveau.bsky.social, @ox.ac.uk
Looking at protists with the eyes of a theoretical neuroscientist.
Looking at brains with the eyes of a protistologist.
(I also like axon initial segments)
Forthcoming book: The Brain, in Theory.
http://romainbrette.fr/
(Finishing) PhD in neuroAI at the Donders Institute (NL). Working on computational neuroscience and deep learning. Also into physics, ALife, complexity, filmmaking, philosophy, and space exploration.
PhD Researcher @ Intelligent Systems Research Centre, UU; interested in Neural dynamics, RNNs, Connectomes; www.jajm.uk
PhD candidate in CogCompNeuro at JLU Giessen
Exploring brains, minds, and worlds 🧠💭🗺️
https://levandyck.github.io/
Ph.D. Student Mila / McGill. Machine learning and Neuroscience, Memory and Hippocampus
Research Fellow at the Gatsby Unit, UCL
Q: How do we learn?
PhD in computational neuroscience @fmiscience.bsky.social.
Enthusiastic rock climber and cat dad.
Computational neuroscientist studying learning and memory in health and disease. Dad, yogi, Assistant Professor at Rutgers University.
Neural reverse engineer, scientist at Meta Reality Labs, Adjunct Prof at Stanford.
PhD in computational neuroscience; Postdoc at MIT; working with @evfedorenko.bsky.social
eghbalhosseini.github.io
Computational Neuroscientist & Neurotechnologist
Postdoc with Andrew Saxe at the Gatsby unit.
postdoc @oxfordstatistics.bsky.social working on (robust) LMs for @naturerecovery.bsky.social 🌱
prev PhD student @clopathlab.bsky.social 🧠 & AI resident @ Google X 🤖
chronic reader of old papers. dynamical systems & computation & bio-plausible learning. curr: @flatiron ccn, msc: comp neuro @tubingen, bsc: EE.
Math, Neuroscience, AI. PhD candidate at Mila and University of Montreal; also writes music and dreams of post-growth economies 🧠🪴🇵🇸 Website: https://computationalcognition.ca/author/
Public Engagement Manager Imperial College London - #ImperialLates and #sciart 'Great Exhibition Road Festival' organiser. Also writes about planets and geology and other stuff. #Scicomm + music geek.
https://bsky.app/profile/jamesromero.bsky.social




















