Meet me at the Benchmarking workshop (sites.google.com/view/benchma...) at EurIPS on Saturday: We’ll present two works on errors in LLM-as-Judge and their impacts on benchmarking and test-time-scaling:
05.12.2025 08:57 — 👍 7 🔁 3 💬 1 📌 0

At #NeurIPS in San Diego this week? Interested in XAI, causality, or performative prediction? Come visit our poster!
💬 Performative Validity of Recourse Explanations
📆 Wednesday, 4.30 pm, Poster Session 2
w/ Hidde Fokkema, Timo Freiesleben, Celestine Mendler-Dünner, Ulrike von Luxburg
02.12.2025 18:17 — 👍 11 🔁 3 💬 0 📌 0

Attending #Neurips2025? Get your personalized Scholar Inbox conference program now to easily navigate the poster sessions and find what you are looking for:
www.scholar-inbox.com/conference/n...
02.12.2025 06:37 — 👍 34 🔁 12 💬 0 📌 0

I'll be @neuripsconf.bsky.social presenting Strategic Hypothesis Testing (spotlight!)
tldr: Many high-stakes decisions (e.g., drug approval) rely on p-values, but people submitting evidence respond strategically even w/o p-hacking. Can we characterize this behavior & how policy shapes it?
1/n
01.12.2025 20:31 — 👍 17 🔁 4 💬 1 📌 0
The empirical landscape sits between the two extremes.
- Model similarity is high, yet disagreements let individuals find recourse by switching models.
- Systemic exclusion is rare, yet more likely than under strong multiplicity.
- Even in a single model, prompt variations induce multiplicity.
02.12.2025 15:57 — 👍 3 🔁 0 💬 0 📌 0
We evaluate 50 LLMs (various sizes & providers) across 6 tasks to assess how well each narrative fits the current LLM landscape, assuming that decision makers will increasingly rely on these models for consequential predictions.
02.12.2025 15:57 — 👍 1 🔁 0 💬 1 📌 0
There are two narratives about model ecosystems that grew out of the algorithmic fairness debate:
1. Monoculture: models converge toward homogeneity.
2. Multiplicity: many models solve tasks similarly but disagree on individual predictions, creating outcome variation.
02.12.2025 15:57 — 👍 0 🔁 0 💬 1 📌 0
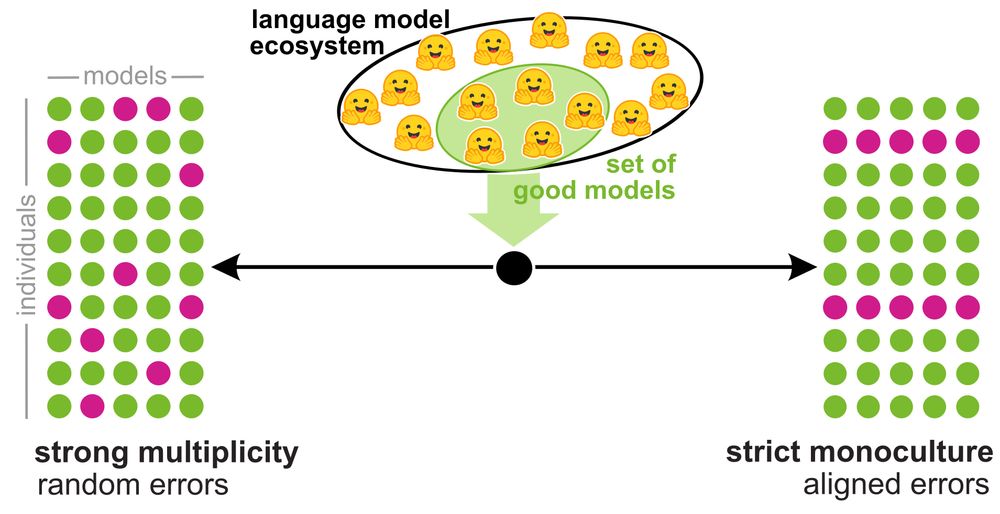
Excited to be at #Neurips2025 this week to present our paper "Monoculture or Multiplicity: Which is it?", joint work with Moritz Hardt.
📄 Paper #1000: openreview.net/pdf?id=DO5Lt...
📍 Wed, Dec 3, 2025 • 4:30 PM – 7:30 PM
Feel free to come by and reach out!
A short 🧵.
02.12.2025 15:55 — 👍 16 🔁 4 💬 1 📌 0
Director of the AI Governance Lab @cendemtech.bsky.social / responsible AI + policy
Ph.D student at the Max Planck Institute for Intelligent Systems. Forest child.
https://sbharadwajj.github.io/
Computer Science PhD student & Knight-Hennessy scholar at @stanford.edu.
Prev.: @ox.ac.uk with @rhodeshouse.ox.ac.uk, @harvard.edu '23, @maxplanck.de, @ethz.ch, IBM Research.
Theory CS for Trustworthy AI
https://silviacasacuberta.com
I work with communities on citizen science for safer, fairer, more understanding Internet. Founder: Citizens & Technology Lab. Assistant Prof in Communication at Cornell · Guatemalan-American. @natematias@social.coop
natematias.com
citizensandtech.org
ML researcher
https://afedercooper.info
Associate professor of social computing at UW CSE, leading @socialfutureslab.bsky.social
social.cs.washington.edu
PhD Candidate in Machine Learning at the Max Planck Institute for Intelligent Systems
PhD student at the Max Planck Institute for Intelligent Systems
https://beomri.github.io/
PhD student in CS @ ETHZ / MPI-IS
Theory of ML evaluation https://flodorner.github.io/
Research group leader @ Max Planck Institute working on theory & social aspect of CS. Previous @UCSC@GoogleDeepMind @Stanford @PKU1898
https://yatongchen.github.io/
Data nerd/wonk. Founder of Connected by Data, campaigning for communities to have a powerful say over data and AI.
Into trans rights, neurodiversity, board games, lego, dogs, spreadsheets.
www.jenitennison.com
EurIPS is a community-organized, NeurIPS-endorsed conference in Copenhagen where you can present papers accepted at @neuripsconf.bsky.social
eurips.cc
She/Her • AI Engineer @ IBM Research • MSc in AI @ UFMG 🇧🇷 | Interested in AI Ethics, Safety & Tech Governance. AI/ML engineering & robustness • @blackinai👩🏽💻 (I’m trying to leave twitter🙂↕️)
https://mirianfsilva.github.io
machine learning for health at microsoft research, based in cambridge UK 🌻 she/her
PhD student in ML at MPI-IS. Prev Apple.
Interested in robustness at scale and reasoning.
PhD student at the University of Tübingen, member of @bethgelab.bsky.social, @uni_tue and @MPI_IS (IMPRS-IS). LLM multi-turn post-training and evaluations.




















