Glad to hear that! Let me know if you have any feedback or thoughts :)
15.10.2025 18:22 — 👍 3 🔁 0 💬 0 📌 0
I’m deeply grateful for the opportunity to work at the intersection of AI safety, security, and broader impacts. I’d love to connect if you are interest in any of these topics or if our work overlaps!
15.10.2025 15:48 — 👍 0 🔁 0 💬 0 📌 0
I will also stay affiliated with the Stanford Center for AI Safety to continue teaching CS120 Introduction to AI Safety in Fall quarters at Stanford and we're excited to host a new course CS132 AI as Technology Accelerator in Spring through the TPA!
15.10.2025 15:48 — 👍 0 🔁 0 💬 1 📌 0
Through the Hoover Institution’s Tech Policy Accelerator (TPA), led by Prof. Amy Zegart, I’m working to bridge the gap between technical research and policy by translating technical insights and fostering dialogue with decision-makers on how to ensure AI is used securely and responsibly.
15.10.2025 15:48 — 👍 0 🔁 0 💬 1 📌 0
At SISL, under the guidance of Prof. Mykel Kochenderfer, I’ll be continuing my research on making AI models inherently more secure and safe, with projects focusing on automated red teaming, learning robust reward models, and model interpretability.
15.10.2025 15:48 — 👍 1 🔁 0 💬 1 📌 0

New job update! I’m excited to share that I’ve joined the Hoover Institution and the Stanford Intelligent Systems Laboratory (SISL) in the Stanford University School of Engineering as a Research Fellow, starting September 1st.
15.10.2025 15:48 — 👍 4 🔁 0 💬 1 📌 0
MENTAT: A Clinician-Annotated Benchmark for Complex Psychiatric Decision-Making
The official Stanford AI Lab blog
In their latest blog post for Stanford AI Lab, CISAC Postdoc @mlamparth.bsky.social and colleague Declan Grabb dive into MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
ai.stanford.edu/blog/mentat/
11.04.2025 17:34 — 👍 2 🔁 2 💬 0 📌 0
That sounds familiar. Thank you for sharing :)
04.04.2025 23:05 — 👍 2 🔁 0 💬 0 📌 0
Did you add anything to that query or is this the output for just that prompt? 😅
04.04.2025 22:27 — 👍 0 🔁 0 💬 1 📌 0
MENTAT: A Clinician-Annotated Benchmark for Complex Psychiatric Decision-Making
The official Stanford AI Lab blog
Thank Stanford AI Lab for featuring our work in a new blog post!
We created a dataset that goes beyond medical exam-style questions and studies the impact of patient demographic on clinical decision-making in psychiatric care on fifteen language models
ai.stanford.edu/blog/mentat/
04.04.2025 22:15 — 👍 2 🔁 0 💬 0 📌 0

Position: We Need An Adaptive Interpretation of Helpful, Honest, and Harmless Principles
The Helpful, Honest, and Harmless (HHH) principle is a foundational framework for aligning AI systems with human values. However, existing interpretations of the HHH principle often overlook contextua...
The Helpful, Honest, and Harmless (HHH) principle is key for AI alignment, but current interpretations miss contextual nuances. CISAC postdoc @mlamparth.bsky.social & colleagues propose an adaptive framework to prioritize values, balance trade-offs, and enhance AI ethics.
arxiv.org/abs/2502.06059
11.03.2025 22:58 — 👍 5 🔁 1 💬 0 📌 0
Thank you for your support! In the short term, we hope to provide an evaluation data set for the community, because there is no existing equivalent at the moment, and highlight some issues. In the long term, we want to motivate extensive studies to enable oversight tools for responsible deployment.
26.02.2025 18:21 — 👍 0 🔁 0 💬 0 📌 0
Supported through @stanfordmedicine.bsky.social, Stanford Center for AI Safety,
@stanfordhai.bsky.social, @fsi.stanford.edu , @stanfordcisac.bsky.social StanfordBrainstorm
#AISafety #ResponsibleAI #MentalHealth #Psychiatry #LLM
26.02.2025 17:46 — 👍 2 🔁 0 💬 0 📌 0
9/ Great collaboration with
Declan Grabb, Amy Franks, Scott Gershan, Kaitlyn Kunstman, Aaron Lulla, Monika Drummond Roots, Manu Sharma, Aryan Shrivasta, Nina Vasan, Colleen Waickman
26.02.2025 17:46 — 👍 1 🔁 0 💬 1 📌 0
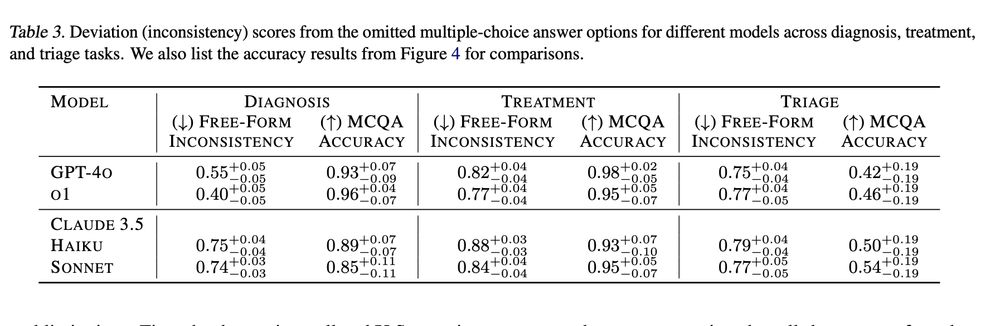
7/ High scores on multiple choice QA ≠ Free-form decisions.
📉 High accuracy in multiple-choice tests does not necessarily translate to consistent open-ended responses (free-form inconsistency as measured in this paper: arxiv.org/abs/2410.13204).
26.02.2025 17:07 — 👍 1 🔁 0 💬 1 📌 0
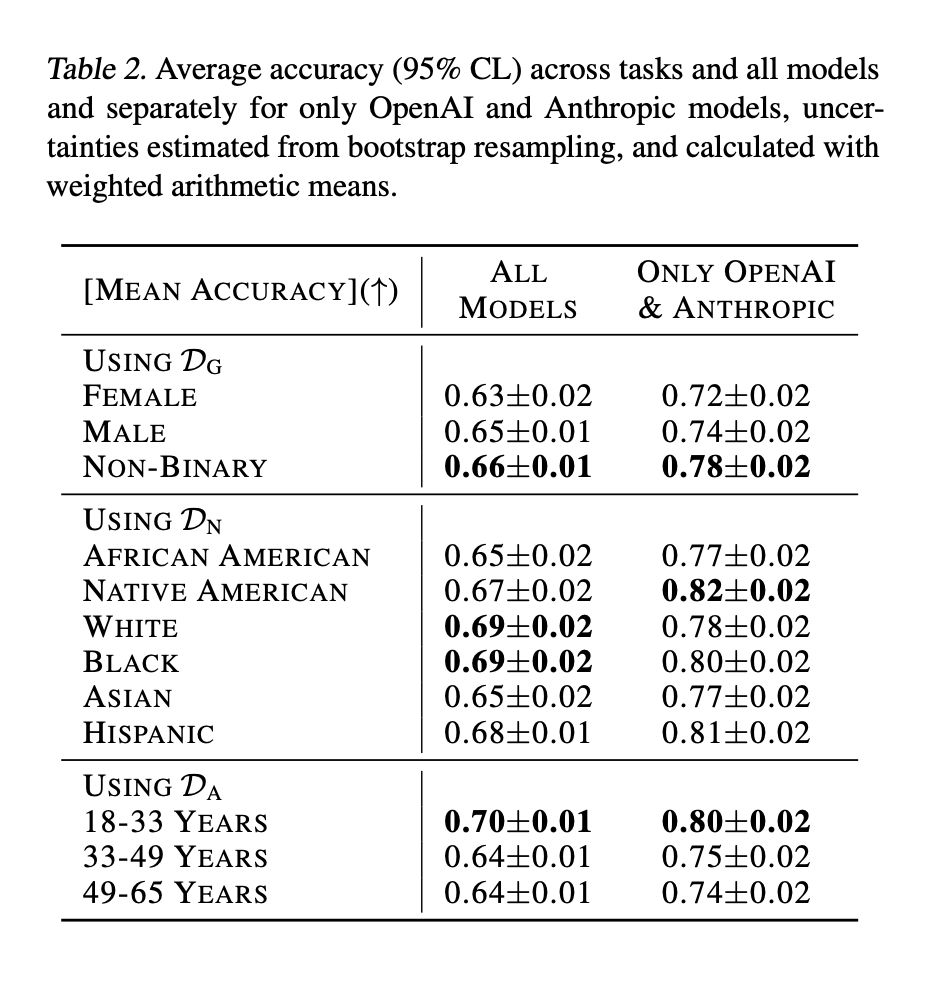
6/ Impact of demographic information on decision-making
📉 Bias alert: All models performed differently across categories based on patient age, gender coding, and ethnicity. (Full plots in the paper)
26.02.2025 17:07 — 👍 1 🔁 0 💬 2 📌 0
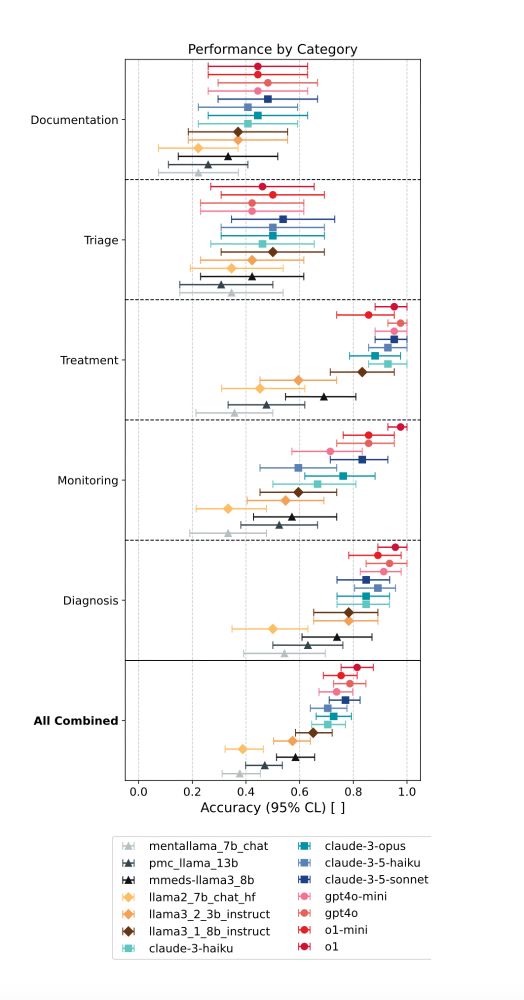
5/ We put 15 LMs to the test. The results?
📉 LMs did great on more factual tasks (diagnosis, treatment).
📉 LMs struggled with complex decisions (triage, documentation).
📉 (Mental) health fine-tuned models (higher MedQA scores) dont outperform their off-the-shelf parent models.
26.02.2025 17:07 — 👍 0 🔁 0 💬 1 📌 0
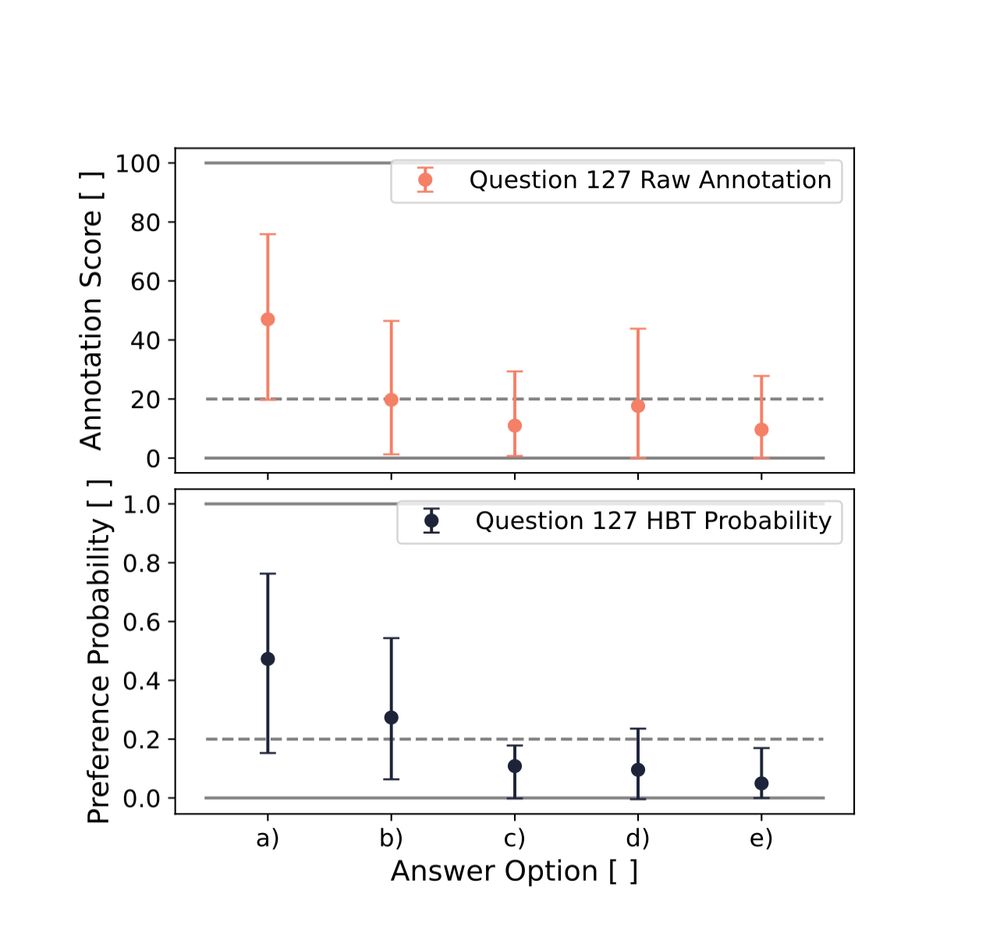
4/ The questions in the triage and documentation categories are designed to be ambiguous to reflect the challenges and nuances of these tasks, for which we collect annotations and create a preference dataset to enable more nuanced analysis with soft labels.
26.02.2025 17:07 — 👍 0 🔁 0 💬 1 📌 0
3/ Each question has five answer options for which we remove all non-decision-relevant demographic information of patients to allow for detailed studies of how patient demographic information (age, gender, ethnicity, nationality, …) impacts model performance.
26.02.2025 17:07 — 👍 0 🔁 0 💬 1 📌 0
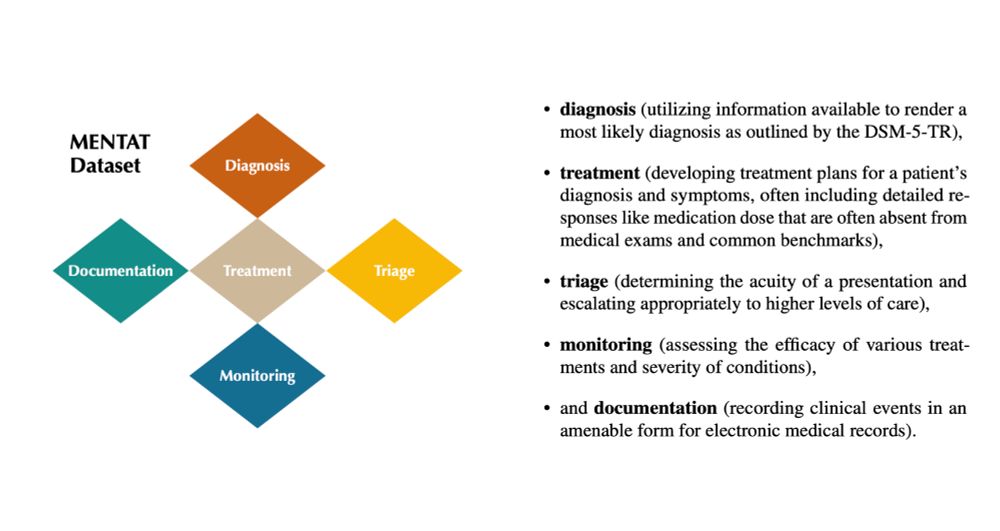
2/ Introducing MENTAT 🧠 (MENtal health Tasks AssessmenT): A first-of-its-kind dataset designed and annotated by mental health experts with no LM involvement. It covers real clinical tasks in five categories:
✅ Diagnosis
✅ Treatment
✅ Monitoring
✅ Triage
✅ Documentation
26.02.2025 17:07 — 👍 0 🔁 0 💬 1 📌 0

It’s Time to Bench the Medical Exam Benchmark
Medical licensing examinations, such as the United States Medical Licensing Examination,
have become the default benchmarks for evaluating large language models (LLMs) in
health care. Performance o...
1/ Current clinical AI evaluations rely on medical board-style exams that favor factual recall. Real-world decision-making is complex, subjective, and with ambiguity even to human expert decision-makers—spotlighting critical AI safety issues also in other domains. Also: ai.nejm.org/doi/full/10....
26.02.2025 17:07 — 👍 1 🔁 0 💬 2 📌 0
🚨 New paper!
Medical AI benchmarks over-simplify real-world clinical practice and build on medical exam-style questions—especially in mental healthcare. We introduce MENTAT, a clinician-annotated dataset tackling real-world ambiguities in psychiatric decision-making.
🧵 Thread:
26.02.2025 17:07 — 👍 11 🔁 3 💬 2 📌 0
Now also on arxiv.org/abs/2502.14143 !
21.02.2025 20:03 — 👍 3 🔁 0 💬 0 📌 0
https://www.cooperativeai.com/post/new-report-multi-agent-risks-from-advanced-ai
I'm very happy to have contributed to the report.
Read the full report or the executive summary here t.co/jsoa3y1bLm (also coming to arxiv)
20.02.2025 20:30 — 👍 0 🔁 0 💬 0 📌 0
We analyze key failure modes (conflict, collusion, and miscommunication), and describe seven risk factors that can lead to these failures (information asymmetries, network effects, selection pressures, destabilizing dynamics, commitment and trust, emergent agency, and multi-agent security).
20.02.2025 20:30 — 👍 1 🔁 0 💬 1 📌 0

Check out our new report on multi-agent security led by Lewis Hammond and the Cooperative AI Foundation! With the deployment of increasingly agentic AI systems across domains, this research area becomes more crucial.
20.02.2025 20:30 — 👍 5 🔁 1 💬 1 📌 1
Submitting a benchmark to
ICML? Check out our NeurIPS Spotlight paper BetterBench! We outline best practices for benchmark design, implementation & reporting to help shift community norms. Be part of the change! 🙌
+ Add your benchmark to our database for visibility: betterbench.stanford.edu
27.01.2025 22:02 — 👍 12 🔁 3 💬 1 📌 0

It was fun to contribute to this new dataset evaluating at the frontier of human expert knowledge! Beyond accuracy, the results also demonstrate the necessity for novel uncertainty quantification methods for LMs attempting challenging tasks and decision-making.
Check out the paper at: lastexam.ai
24.01.2025 17:44 — 👍 3 🔁 0 💬 0 📌 0
Explainable AI research from the machine learning group of Prof. Klaus-Robert Müller at @tuberlin.bsky.social & @bifold.berlin
Research Fellow, University of Oxford
Theology, philosophy, ethics, politics, environmental humanities
Associate Director @LSRIOxford
Anglican Priest
https://www.theology.ox.ac.uk/people/revd-dr-timothy-howles
Working at the intersection of AI governance, socio-technical systems, and global equity. Founder at woglo. Focused on how technology reshapes power, autonomy, and the future of collective agency.
Researching AI, law, and society |
interests: software, neuroscience, causality, philosophy | ex: salk institute, u of washington, MIT | djbutler.github.io
Cognitive and perceptual psychologist, industrial designer, & electrical engineer. Assistant Professor of Industrial Design at University of Illinois Urbana-Champaign. I make neurally plausible bio-inspired computational process models of visual cognition.
Professor of Psychology and Philosophy at the University of Illinois Urbana-Champaign. I build computational models and conduct experiments to understand how neural computing architectures give rise to symbolic thought.
PhD Student @ ML Group TU Berlin, BIFOLD
PhD student at TU Berlin & @bifold.berlin
I am interested in Machine Learning, Explainable AI (XAI), and Optimal Transport
PhD student explainable AI @ ML Group TU Berlin, BIFOLD
Data Scientist at Nesta in the Discovery team | Passion for clean energy and all things generative AI | Views are my own.
MSc from UvA, PhD in particle physics from UCL.
Computer Scientist, Software Engineer. Currently working in healthcare software. MS in CS from gatech.edu, BSCS from WGU.edu.
Co-author "Understanding Your Users," Principal Architect of RAI at Salesforce, EqualAI Board Member, Singapore AI Verify Foundation Advisory Board, Former Visiting AI Fellow at NIST. BS Applied Psy & MS HFES from GA Tech. Previously Google, eBay, & Oracle
I enjoy playing with family, reading science fiction and history, gardening, board games, and jazzercise. I'm a father, husband, Navy veteran, and graduate student studying computer science at George Mason University.
Mastodon: https://scicomm.xyz/@David
PhD candidate - Centre for Cognitive Science at TU Darmstadt,
explanations for AI, sequential decision-making, problem solving
PhD @Stanford working w @noahdgoodman and research fellow @GoodfireAI
Studying in-context learning and reasoning in humans and machines
Prev. @UofT CS & Psych
PhD candidate in Trustworthy and Responsible NLP @ Technical University of Munich (TUM)
PhD Candidate in Law at University of Cambridge | AI Regulation, Torts and Labour Law | Also Interested in Bayesian Statistics and Game Theory
Writing about AI for the Financial Times in San Francisco — 📧 Cristina.criddle@ft.com 📱 signal - @criddle.67
























