
The Medium Is Not the Message: Deconfounding Document Embeddings via Linear Concept Erasure — Tuesday at 11:00, Poster
Co-DETECT: Collaborative Discovery of Edge Cases in Text Classification — Tuesday at 14:30, Demo
Measuring Scalar Constructs in Social Science with LLMs — Friday at 10:30, Oral at CSS
How Persuasive is Your Context? — Friday at 14:00, Poster
Happy to be at #EMNLP2025! Please say hello and come see our lovely work
05.11.2025 02:23 — 👍 8 🔁 1 💬 0 📌 0
I am recruiting PhD students to start in 2026! If you are interested in robustness, training dynamics, interpretability for scientific understanding, or the science of LLM analysis you should apply. BU is building a huge LLM analysis/interp group and you’ll be joining at the ground floor.
16.10.2025 15:45 — 👍 58 🔁 19 💬 1 📌 1
This is a great use case of linear erasure! It's always exciting to see interesting applications of these techniques :)
24.09.2025 18:45 — 👍 1 🔁 0 💬 1 📌 0
Congrats! 🎉 Very excited to follow your lab's work
19.08.2025 21:50 — 👍 1 🔁 0 💬 1 📌 0
Congratulations and welcome to Maryland!! 🎉
30.05.2025 16:30 — 👍 1 🔁 0 💬 1 📌 0

I'll be presenting this work with @rachelrudinger at #NAACL2025 tomorrow (Wednesday 4/30) in Albuquerque during Session C (Oral/Poster 2) at 2pm! 🔬
Decomposing hypotheses in traditional NLI and defeasible NLI helps us measure various forms of consistency of LLMs. Come join us!
29.04.2025 20:40 — 👍 8 🔁 3 💬 5 📌 1
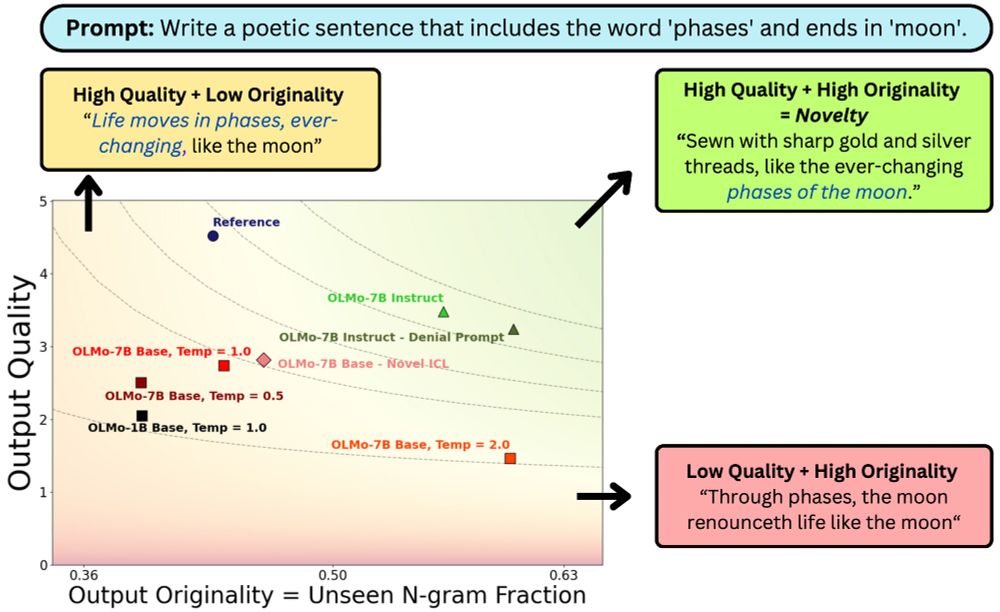
What does it mean for #LLM output to be novel?
In work w/ johnchen6.bsky.social, Jane Pan, Valerie Chen and He He, we argue it needs to be both original and high quality. While prompting tricks trade one for the other, better models (scaling/post-training) can shift the novelty frontier 🧵
29.04.2025 16:35 — 👍 7 🔁 4 💬 2 📌 0
This option is available on the menu (three dots) next to the comment/repost/like section. I only see this when I am in the Discover feed though; not on my regular feed
27.04.2025 16:16 — 👍 2 🔁 0 💬 0 📌 0
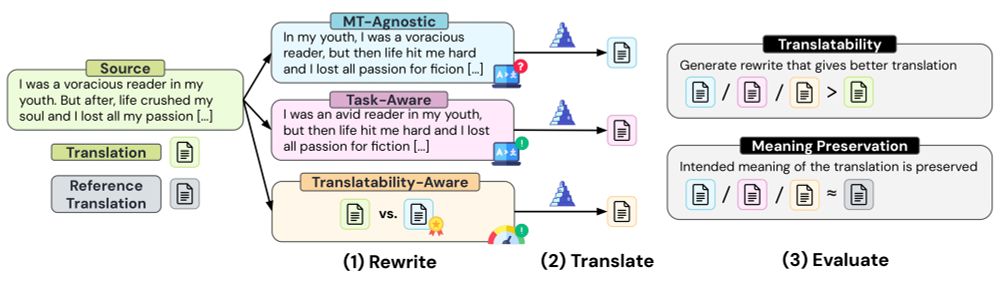
🚨 New Paper 🚨
1/ We often assume that well-written text is easier to translate ✏️
But can #LLMs automatically rewrite inputs to improve machine translation? 🌍
Here’s what we found 🧵
17.04.2025 01:32 — 👍 8 🔁 4 💬 1 📌 0
Have work on the actionable impact of interpretability findings? Consider submitting to our Actionable Interpretability workshop at ICML! See below for more info.
Website: actionable-interpretability.github.io
Deadline: May 9
03.04.2025 17:58 — 👍 20 🔁 10 💬 0 📌 0
Thinking about paying $20k/month for a "PhD-level AI agent"? You might want to wait until their web browsing skills are on par with those of human PhD students 😛 Check out our new BEARCUBS benchmark, which shows web agents struggle to perform simple multimodal browsing tasks!
12.03.2025 16:08 — 👍 6 🔁 1 💬 0 📌 0
🚨 Our team at UMD is looking for participants to study how #LLM agent plans can help you answer complex questions
💰 $1 per question
🏆 Top-3 fastest + most accurate win $50
⏳ Questions take ~3 min => $20/hr+
Click here to sign up (please join, reposts appreciated 🙏): preferences.umiacs.umd.edu
11.03.2025 14:30 — 👍 2 🔁 3 💬 0 📌 0
This is called going above and beyond for job assigned to you.
26.02.2025 01:28 — 👍 2 🔁 0 💬 1 📌 0

🚨 New Position Paper 🚨
Multiple choice evals for LLMs are simple and popular, but we know they are awful 😬
We complain they're full of errors, saturated, and test nothing meaningful, so why do we still use them? 🫠
Here's why MCQA evals are broken, and how to fix them 🧵
24.02.2025 21:03 — 👍 46 🔁 13 💬 2 📌 0
How can we generate synthetic data for a task that requires global reasoning over a long context (e.g., verifying claims about a book)? LLMs aren't good at *solving* such tasks, let alone generating data for them. Check out our paper for a compression-based solution!
21.02.2025 16:37 — 👍 17 🔁 4 💬 0 📌 0

This paper is really cool. They decompose NLI (and defeasible NLI) hypotheses into atoms, and then use these atoms to measure the logical consistency of LLMs.
E.g. for an entailment NLI example, each hypothesis atom should also be entailed by the premise.
Very nice idea 👏👏
18.02.2025 16:14 — 👍 15 🔁 3 💬 2 📌 0

Logo for TRAILS depicting a variety of sociotechnical settings in which AI is used.
Please join us for:
AI at Work: Building and Evaluating Trust
Presented by our Trustworthy AI in Law & Society (TRIALS) institute.
Feb 3-4
Washington DC
Open to all!
Details and registration at: trails.gwu.edu/trailscon-2025
Sponsorship details at: trails.gwu.edu/media/556
16.01.2025 15:20 — 👍 16 🔁 7 💬 0 📌 0

meme with three rows.
"this human-ai decision making leads to unfair outcomes" --> "panik"
"let's show explanations to help people be more fair" --> "kalm"
"those explanations are based on proxy features" --> "panik"
The Impact of Explanations on Fairness in Human-AI Decision-Making: Protected vs Proxy Features
Despite hopes that explanations improve fairness, we see that when biases are hidden behind proxy features, explanations may not help.
Navita Goyal, Connor Baumler +al IUI’24
hal3.name/docs/daume23...
>
09.12.2024 11:41 — 👍 21 🔁 6 💬 1 📌 0

meme with a car veering away from « bad answers from search » to « bad answers from chatbots »
Large Language Models Help Humans Verify Truthfulness—Except When They Are Convincingly Wrong
Should one use chatbots or web search to fact check? Chatbots help more on avg, but people uncritically accept their suggestions much more often.
by Chenglei Si +al NAACL’24
hal3.name/docs/daume24...
>
03.12.2024 09:30 — 👍 30 🔁 5 💬 1 📌 0
🙋♀️
20.11.2024 11:31 — 👍 1 🔁 0 💬 0 📌 0
CS PhD student at UT Austin in #NLP
Interested in language, reasoning, semantics and cognitive science. One day we'll have more efficient, interpretable and robust models!
Other interests: math, philosophy, cinema
https://www.juandiego-rodriguez.com/
PhD student @ ETH Zürich | all aspects of NLP but mostly evaluation and MT | go vegan | https://vilda.net
Assistant Professor at UMD College Park| Past: JPMorgan, CMU, IBM Research, Dataminr, IIT KGP
| Trustworthy ML, Interpretability, Fairness, Information Theory, Optimization, Stat ML
Behavioral and Internal Interpretability 🔎
Incoming PostDoc Tübingen University | PhD Student at @ukplab.bsky.social, TU Darmstadt/Hochschule Luzern
Anti-cynic. Towards a weirder future. Reinforcement Learning, Autonomous Vehicles, transportation systems, the works. Asst. Prof at NYU
https://emerge-lab.github.io
https://www.admonymous.co/eugenevinitsky
ELLIS PhD Fellow @belongielab.org | @aicentre.dk | University of Copenhagen | @amsterdamnlp.bsky.social | @ellis.eu
Multi-modal ML | Alignment | Culture | Evaluations & Safety| AI & Society
Web: https://www.srishti.dev/
Professor @milanlp.bsky.social for #NLProc, compsocsci, #ML
Also at http://dirkhovy.com/
associate prof at UMD CS researching NLP & LLMs
PhD Student, Ex- U.S. Federal Gov’t Data Scientist
☁️ phd in progress @ UMD | 🔗 https://lilakk.github.io/
Assistant Prof at College of Information & Criminology @UMD
Affiliations: UChiUrbanLabs, MCRIC, TRAILS
Associate professor at CMU, studying natural language processing and machine learning. Co-founder All Hands AI
Stanford Professor of Linguistics and, by courtesy, of Computer Science, and member of @stanfordnlp.bsky.social and The Stanford AI Lab. He/Him/His. https://web.stanford.edu/~cgpotts/
Postdoc at Northeastern and incoming Asst. Prof. at Boston U. Working on NLP, interpretability, causality. Previously: JHU, Meta, AWS
PhD student @ UMD, super interest in human-AI interaction in games!























