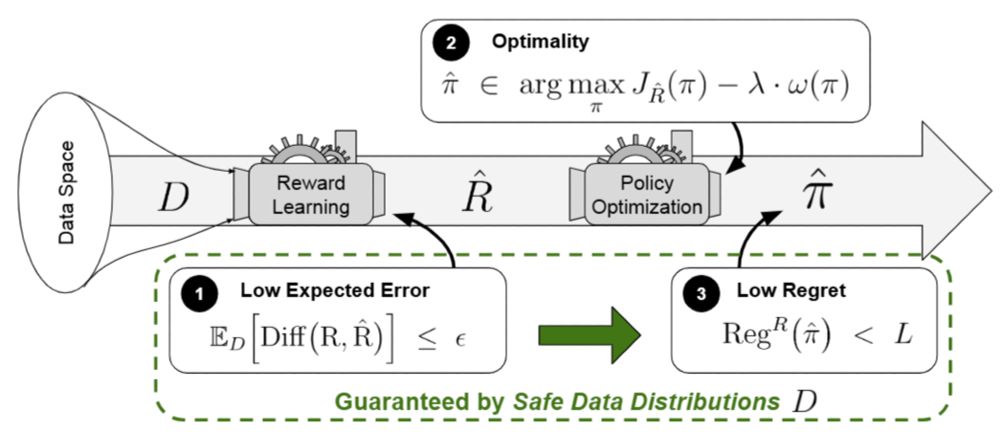
⚠️ The Perils of Optimizing Learned Reward Functions: Low Training Error Does Not Guarantee Low Regret
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8

@leon-lang.bsky.social
PhD Candidate at the University of Amsterdam. AI Alignment and safety research. Formerly multivariate information theory and equivariant deep learning. Masters degrees in both maths and AI. https://langleon.github.io/
⚠️ The Perils of Optimizing Learned Reward Functions: Low Training Error Does Not Guarantee Low Regret
By Lukas Fluri*, @leon-lang.bsky.social *, Alessandro Abate, Patrick Forré, David Krueger, Joar Skalse
📜 arxiv.org/abs/2406.15753
🧵6 / 8

Paper link: arxiv.org/abs/2502.21262
(4/4)
I theoretically describe what modeling the human's beliefs would mean, and explain a practical proposal for how one could try to do this, based on foundation models whose internal representations *translate to* the human's beliefs using an implicit ontology translation. (3/4)
03.03.2025 15:44 — 👍 0 🔁 0 💬 1 📌 0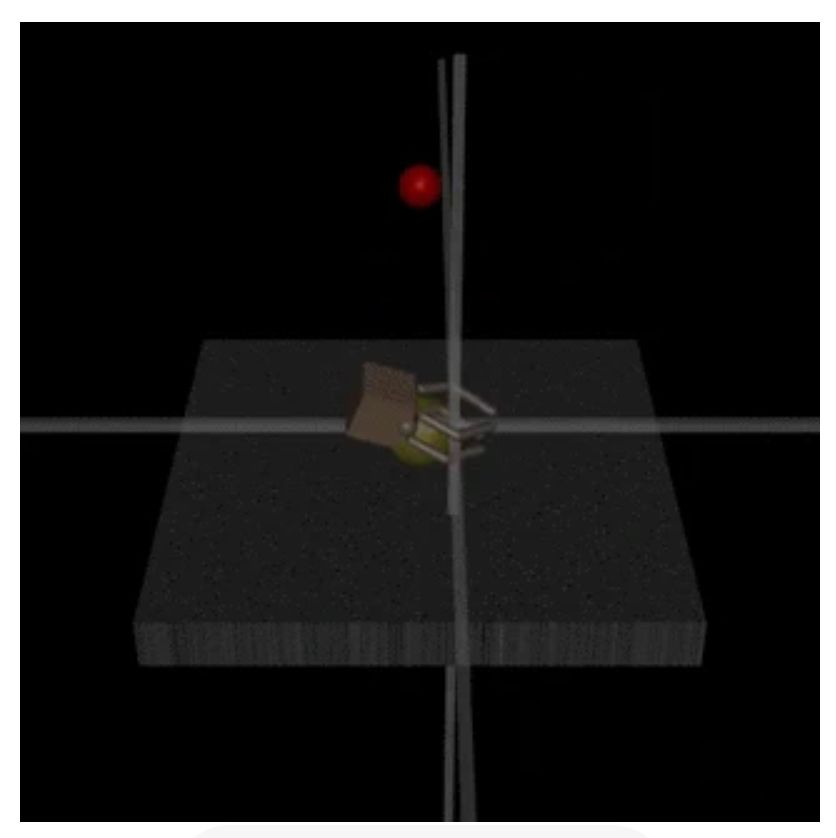
The idea: In the robot-hand example, when the hand is in front of the ball, the human believes the ball was grasped and gives "thumbs up", leading to bad behavior. If we knew the human's beliefs, then we could assign the feedback properly: Reward the ball being grasped! (2/4)
03.03.2025 15:44 — 👍 0 🔁 0 💬 1 📌 0Brief paper announcement (longer thread might follow):
In our new paper "Modeling Human Beliefs about AI behavior for Scalable Oversight", I propose to model a human evaluator's beliefs to better interpret the feedback, which might help for scalable oversight. (1/4)
www.arxiv.org/abs/2502.21262
I have now this follow-up paper that goes into greater detail for how to achieve the human belief modeling, both conceptually and potentially in practice.
If you are attending #NeurIPS2024🇨🇦, make sure to check out AMLab's 11 accepted papers ...and to have a chat with our members there! 👩🔬🍻☕
Submissions include generative modelling, AI4Science, geometric deep learning, reinforcement learning and early exiting. See the thread for the full list!
🧵1 / 12
First UAI conference in Latin America!! 🔥🔥🔥
North America and Europe you are nice, but sometimes I also want to visit somewhere else 😅
I just completed "Historian Hysteria" - Day 1 - Advent of Code 2024 #AdventOfCode adventofcode.com/2024/day/1
01.12.2024 17:19 — 👍 3 🔁 0 💬 0 📌 0I notice more “big” accounts here that follow a lot of people. The same accounts follow almost no one on twitter. Is this motivated by a difference in the algorithms of these platforms?
01.12.2024 11:04 — 👍 0 🔁 0 💬 0 📌 0

Yet another safety researcher has left OpenAI.
Rosie Campbell says she has been “unsettled by some of the shifts over the last ~year, and the loss of so many people who shaped our culture”.
She says she “can’t see a place” for her to continue her work internally.
We are taking on a mission to track progress in AI capabilities over time.
Very proud of our team!

Hey hey,
I am around in the Bay area for the next few weeks. Bay area folks hit me up if you want to meet up for coffee/ vegan food in and around SF ☕🌯 🥟
Got a major weather upgrade☀️ from Amsterdam's insanity last week 🌀🌩️
Thanks for highlighting our paper! :)
25.11.2024 19:33 — 👍 1 🔁 0 💬 1 📌 0Interesting, I didn’t know such things are common practice!
24.11.2024 07:52 — 👍 1 🔁 0 💬 1 📌 0I think such questionnaires should maybe generally contain a control group of people who did some brief (let’s say 15 minutes) calibration training just do understand what percentages even mean.
23.11.2024 22:48 — 👍 4 🔁 0 💬 1 📌 1Are people maybe very bad at math?
I remember once that I asked my own mom to draw what one million dollars looks like in proportion to 1 billion, and she drew like what corresponds to ~ 150 million, off by a factor of 150.
Yeah risks are then probably more external: who creates the LLM, and do they poison the data in such a way that it will associate human utterances to bad goals.
23.11.2024 22:41 — 👍 2 🔁 0 💬 0 📌 0I actually think I (essentially?) understood this! Ie my worry was whether the LLM could end up giving high likelihood to human utterances for goals that are very bad.
23.11.2024 22:40 — 👍 1 🔁 0 💬 1 📌 0I see, interesting.
Is the hope basically that the LLM utters "the same things" as what the human would utter under the same goal? Is there a (somewhat futuristic...) risk that a misaligned language model might "try" to utter the human's phrase under its own misaligned goals?
Meet our Lab's members: staff, postdocs and PhD students! :)
With this starter pack you can easily connect with us and keep up to date with all the member's research and news 🦋
go.bsky.app/8EGigUy
You could add myself possibly
21.11.2024 08:27 — 👍 0 🔁 0 💬 0 📌 0
I strongly disagree. I’d even go as far as saying that for most relevant purposes, it’s fine to say mushrooms are plants. www.google.com/url?q=https:...
21.11.2024 06:49 — 👍 0 🔁 0 💬 0 📌 0

MIT undergrads from families earning less than $200K will pay no tuition fees from 2025, and undergrads from families earning less than $100K will have everything covered, including housing, dining, and a personal allowance.
news.mit.edu/2024/mit-tui...
I think bluesky looks much more like twitter than chat apps look alike. Bluesky even has the same ordering of buttons
20.11.2024 22:26 — 👍 2 🔁 0 💬 0 📌 0Does anyone understand why it’s so easy to clone twitter with no IP issues?
It’s hard to understand qualitative legal thresholds, but the UI looking ~exactly the same both here and on threads intuitively seems like the kind of thing that could violate a copyright if twitter had pursued one
Here :) Thanks for putting this together!
20.11.2024 15:34 — 👍 1 🔁 0 💬 0 📌 0Hi everyone! This is AMLab :)
Looking forward to share our research here on 🦋 !
Good to have you here :P
20.11.2024 12:48 — 👍 1 🔁 0 💬 0 📌 0
















