We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2026! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: tinyurl.com/use-inspired....
31.10.2025 17:43 — 👍 1 🔁 1 💬 0 📌 0
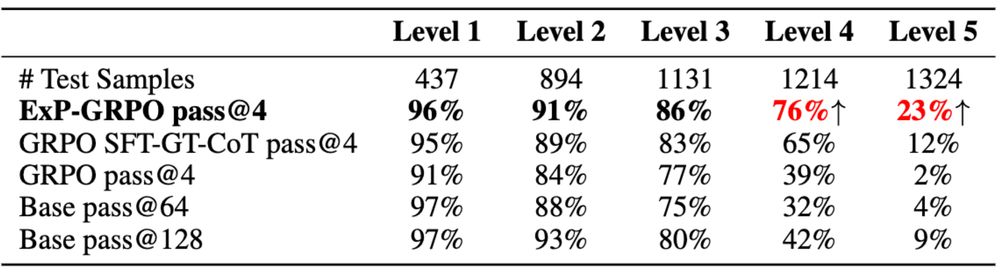
ExPO significantly improves model reasoning on hard tasks.
We plug ExPO into:
• DPO (preference-based)
• GRPO (verifier-based RL)
→ No architecture changes
→ No expert supervision
→ Big gains on hard tasks
Results (Qwen2.5-3B-Instruct, MATH level-5):
22.07.2025 17:09 — 👍 1 🔁 0 💬 1 📌 0
Our solution:
Ask the model to explain the correct answer — even when it couldn’t solve the problem.
These self-explanations are:
✅ in-distribution
✅ richer than failed CoTs
✅ Offer better guidance than expert-written CoTs
We train on them. We call it ExPO.
22.07.2025 17:09 — 👍 1 🔁 0 💬 1 📌 0
Most RL post-training methods only work when the model has some chance to get answers right. But what if it mostly gets everything wrong?
NO correct trajectory sampled -> NO learning signal -> Model stays the same and unlearns due to KL constraint
This happens often in hard reasoning tasks.
22.07.2025 17:09 — 👍 1 🔁 0 💬 1 📌 0
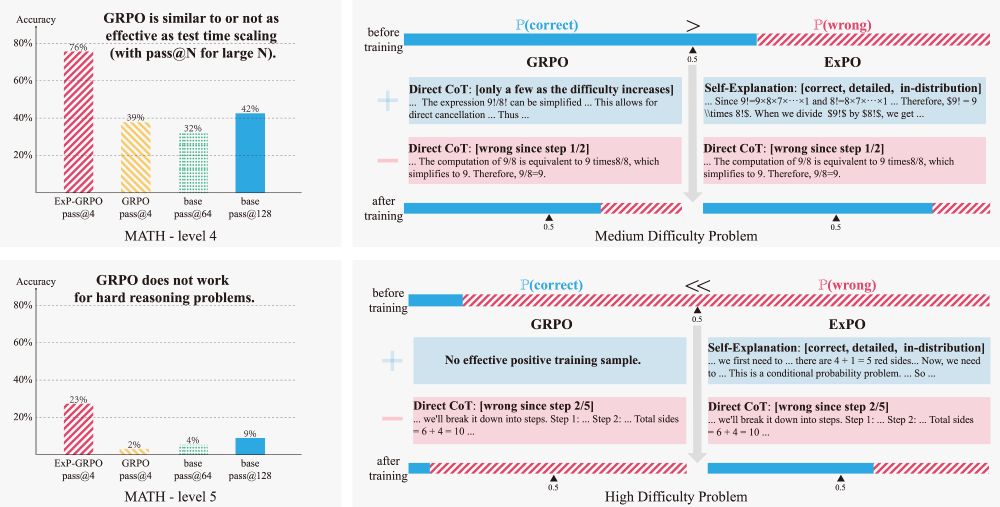
For hard reasoning tasks, the chance of sampling a correct answer is low. Thus, sharpening the sampling distribution is not enough, and standard RL post-training fails.
New method to crack hard reasoning problems with LLM!
No expert traces. No test-time hacks.
Just: Self-explanation + RL-style training
Result? Accuracy on MATH level-5 jumped from 2% → 23%.
22.07.2025 17:09 — 👍 4 🔁 1 💬 1 📌 0
We tested this by learning an affine map between Gemma-2B and Gemma-9B.
The result? Steering vectors(directions for specific behaviors) from the 2B model successfully guided 9B's outputs.
For example, a "dog-saying" steering vector from 2B made 9B talk more about dogs!
10.07.2025 17:26 — 👍 4 🔁 0 💬 1 📌 0
Here's the core idea: We hypothesize that models trained on similar data learn a **universal set of basis features**. Each model's internal representation space is just a unique, model-specific projection of this shared space.
This means representations learned across models are transferable!
10.07.2025 17:26 — 👍 5 🔁 0 💬 1 📌 0
What if you could understand and control an LLM by studying its *smaller* sibling?
Our new paper introduces the Linear Representation Transferability Hypothesis. We find that the internal representations of different-sized models can be translated into one another using a simple linear(affine) map.
10.07.2025 17:26 — 👍 25 🔁 10 💬 1 📌 1
4/4 Joint work with Hui Yuan, Yifan Zeng, Yue Wu, Huazheng Wang, Mengdi Wang
Paper: arxiv.org/abs/2410.13828
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
14.12.2024 17:38 — 👍 3 🔁 0 💬 0 📌 0
3/4 Wonder how to **resolve** problems coming with gradient entanglement? Our theoretical framework highlights new algorithmic ideas:
- Normalized preference optimization: normalize the chosen and rejected gradient
- Sparse token masking: impose sparsity on the tokens for calculating the margins.
14.12.2024 17:38 — 👍 1 🔁 0 💬 1 📌 0
2/4 The Gradient Entanglement effect becomes particularly concerning when the chosen and rejected gradient inner product is large, which often happens when the two responses are similar!
14.12.2024 17:38 — 👍 1 🔁 0 💬 1 📌 0
1/4 We demystify the reason behind the synchronized change in chosen and rejected logps: the **Gradient Entanglement** effect! For any margin-based losses (esp. these *PO objectives), the chosen probability will depend on the rejected gradient, and vice versa.
14.12.2024 17:38 — 👍 0 🔁 0 💬 1 📌 0
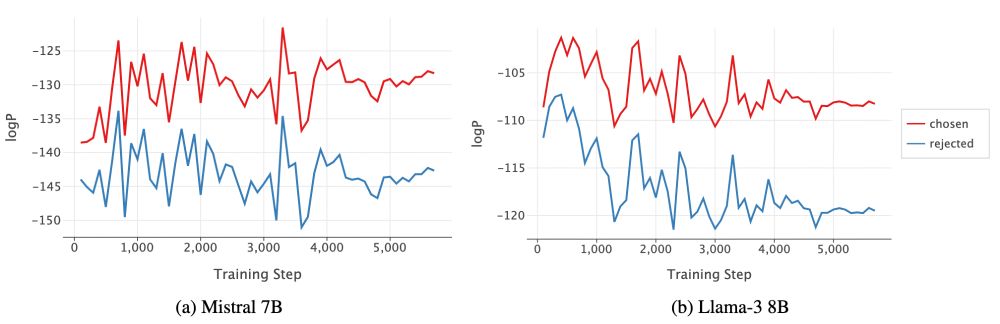
Ever wondered why there are synchronized ups and downs for chosen and rejected log-probs during DPO (and most *POs: IPO, SimPO, CPO, R-DPO, DPOP, RRHF, SlicHF) training? Why do chosen logps decrease, and rejected logps sometimes increase?
Our answer: Gradient Entanglement!
arxiv.org/abs/2410.13828
14.12.2024 17:38 — 👍 3 🔁 1 💬 1 📌 0
4/4 Joint work with Xinyu Li, @ruiyang-zhou.bsky.social,
@zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Personalized_RLHF
Check out our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
14.12.2024 17:02 — 👍 3 🔁 1 💬 0 📌 0
3/4 Beyond user preferences indicated in explicit textual format, P-RLHF can learn the nuanced implicit preferences encoded in user preference data. On the largest publicly available preference dataset based on multi-turn dialog (PRISM), P-RLHF outperforms all strong baselines in winrate by 10-20%.
14.12.2024 17:02 — 👍 1 🔁 0 💬 1 📌 0
2/4 For any base preference optimization (*PO) algorithm, P-RLHF can create its corresponding personalized version P-*PO, allowing for **flexible** choice of alignment algorithms.
14.12.2024 17:02 — 👍 0 🔁 0 💬 1 📌 0
1/4 Personalized-RLHF (P-RLHF) uses a **light-weight** user model to learn user embeddings, which serve as a soft prompt for generating personalized responses. The user model is much smaller (10-100x smaller) compared to the LORA adapters used for fine-tuning the language model.
14.12.2024 17:02 — 👍 0 🔁 0 💬 1 📌 0
How to **efficiently** build personalized language models **without** textual info on user preferences?
Our Personalized-RLHF work:
- light-weight user model
- personalize all *PO alignment algorithms
- strong performance on the largest personalized preference dataset
arxiv.org/abs/2402.05133
14.12.2024 17:02 — 👍 12 🔁 2 💬 1 📌 0
4/4 Joint work with: Xinyu Li, Ruiyang Zhou, @zacharylipton.bsky.social
Paper: arxiv.org/abs/2402.05133, Code: github.com/HumainLab/Pe...
Check our work at the NeurIPS AFM workshop, Exhibit Hall A, 12/14, 4:30 - 5:30 pm #NeurIPS2024
14.12.2024 16:39 — 👍 1 🔁 0 💬 0 📌 0
3/4 Beyond user preferences indicated in explicit textual format, P-RLHF can learn the nuanced implicit preferences encoded in their preference data. On the largest publicly available preference dataset based on multi-turn dialog (PRISM), P-RLHF outperforms all strong baselines in winrate by 10-20%.
14.12.2024 16:39 — 👍 0 🔁 0 💬 1 📌 0
2/4 For any base preference optimization (*PO) algorithm, P-RLHF can create its corresponding personalized version P-*PO, allowing for **flexible** choice of alignment algorithms.
14.12.2024 16:39 — 👍 0 🔁 0 💬 1 📌 0
1/4 Personalized-RLHF (P-RLHF) uses a **light-weight** user model that maps user information to their embeddings, which serve as a soft prompt for generating personalized response. The user model is much smaller (10-100x smaller) compared to the LORA adapters used for fine-tuning the LM.
14.12.2024 16:39 — 👍 0 🔁 0 💬 1 📌 0
http://tinyurl.com/use-inspired-ai-f25
We're hiring a fully-funded Ph.D. student in Use-Inspired AI @ UT Austin starting Fall 2025! Join us to work on impactful AI/ML research addressing real-world challenges.
Learn more & apply: t.co/OPrxO3yMhf
20.11.2024 20:41 — 👍 14 🔁 5 💬 0 📌 0
CS PhD student at UT Austin in #NLP
Interested in language, reasoning, semantics and cognitive science. One day we'll have more efficient, interpretable and robust models!
Other interests: math, philosophy, cinema
https://www.juandiego-rodriguez.com/
https://jessyli.com Associate Professor, UT Austin Linguistics.
Part of UT Computational Linguistics https://sites.utexas.edu/compling/ and UT NLP https://www.nlp.utexas.edu/
UT Austin linguist http://mahowak.github.io/. computational linguistics, cognition, psycholinguistics, NLP, crosswords. occasionally hockey?
Director, Princeton Language and Intelligence. Professor of CS.
Cofounder & CTO @ Abridge, Raj Reddy Associate Prof of ML @ CMU, occasional writer, relapsing 🎷, creator of d2l.ai & approximatelycorrect.com
CS professor at NYU. Large language models and NLP. he/him
Associate Professor, ESADE | PhD, Machine Learning & Public Policy, Carnegie Mellon | Previously FAccT EC | Algorithmic fairness, human-AI collab | 🇨🇴 💚 she/her/ella.








