Thanks a lot to all my amazing co-authors @alessiodevoto.bsky.social @sscardapane.bsky.social @yuzhaouoe.bsky.social @neuralnoise.com Eric de la Clergerie @bensagot.bsky.social
And a special thanks to @edoardo-ponti.bsky.social for the academic visit that made this work possible!
06.03.2025 16:02 —
👍 2
🔁 1
💬 1
📌 0
Will present this at #CVPR ✈️ See you in Nashville 🇺🇸!
Kudos to the team 👏
Antonio A. Gargiulo, @mariasofiab.bsky.social, @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà.
11.03.2025 08:02 —
👍 5
🔁 2
💬 0
📌 0

Please share it within your circles! edin.ac/3DDQK1o
13.03.2025 11:59 —
👍 14
🔁 9
💬 0
📌 1
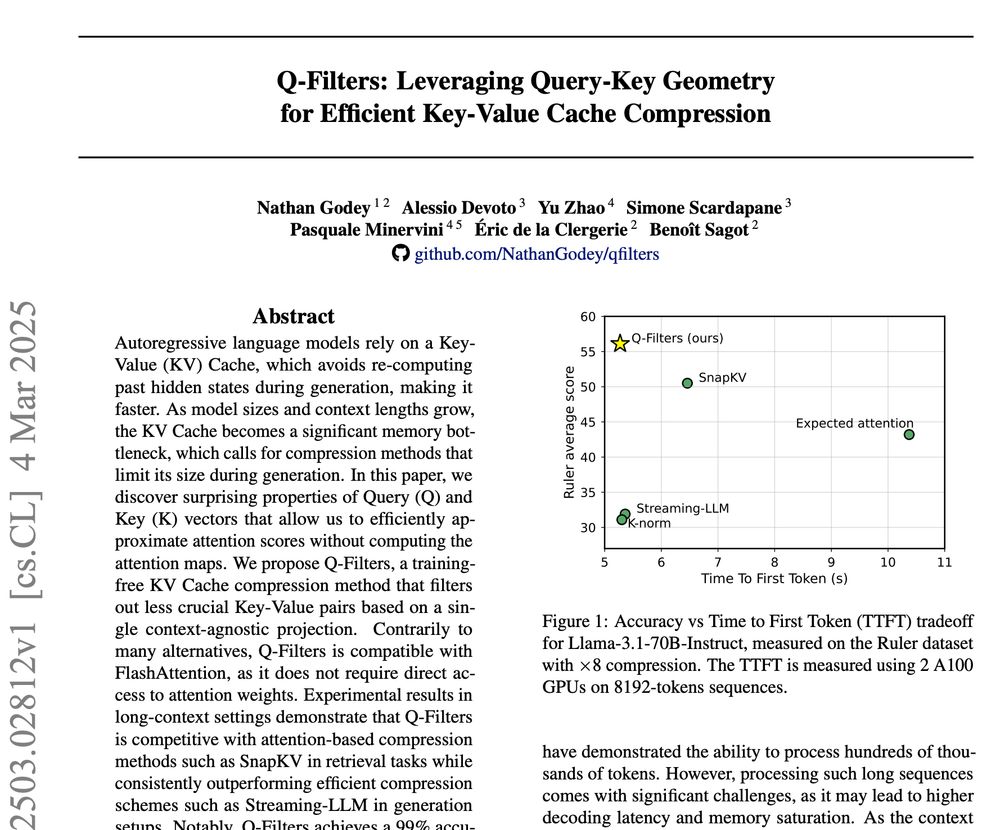
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
06.03.2025 16:02 —
👍 20
🔁 7
💬 1
📌 1

Q-Filters is very efficient which allows streaming compression at virtually no latency cost, just like Streaming-LLM...
...but it is also much better at retaining relevant KV pairs compared to fast alternatives (and can even beat slower algorithms such as SnapKV)
06.03.2025 13:40 —
👍 1
🔁 1
💬 1
📌 0

Compositionality and Ambiguity:
Latent Co-occurrence and Interpretable Subspaces — LessWrong
Matthew A. Clarke, Hardik Bhatnagar and Joseph Bloom
*Compositionality and Ambiguity: Latent Co-occurrence and Interpretable Subspaces*
by @maclarke.bsky.social et al.
Studies co-occurence of SAE features and how they can be understood as composite / ambiguous concepts.
www.lesswrong.com/posts/WNoqEi...
27.02.2025 08:33 —
👍 3
🔁 0
💬 0
📌 0

Weighted Skip Connections are Not Harmful for Deep Nets
Give Gates a Chance
*Weighted Skip Connections are Not Harmful for Deep Nets*
by @rupspace.bsky.social
Cool blog post "in defense" of weighted variants of ResNets (aka HighwayNets) - as a follow up to a previous post by @giffmana.ai.
rupeshks.cc/blog/skip.html
18.02.2025 09:49 —
👍 8
🔁 1
💬 0
📌 0

*CAT: Content-Adaptive Image Tokenization*
by @junhongshen1.bsky.social @lukezettlemoyer.bsky.social et al.
They use an LLM to predict a "complexity score" for each image token, which in turns decides the size of its VAE latent representation.
arxiv.org/abs/2501.03120
17.02.2025 14:57 —
👍 0
🔁 0
💬 0
📌 0

*Accurate predictions on small data with a tabular foundation model*
by Noah Hollmann et al.
A transformer for tabular data that takes an entire training set as input and provides predictions - trained on millions of synthetic datasets.
www.nature.com/articles/s41...
14.02.2025 15:52 —
👍 1
🔁 1
💬 0
📌 0

*Insights on Galaxy Evolution from Interpretable Sparse Feature Networks*
by @jwuphysics.bsky.social
Integrates a sparse dictionary step on the last layer of a CNN to obtain a set of interpretable features on multiple astronomical prediction tasks.
arxiv.org/abs/2501.00089
13.02.2025 13:53 —
👍 3
🔁 0
💬 0
📌 0

*Round and Round We Go! What makes Rotary Positional Encodings useful?*
by @petar-v.bsky.social et al.
They show RoPE has distinct behavior for different rotation angles - high freq for position, low freq for semantics.
arxiv.org/abs/2410.06205
10.02.2025 11:23 —
👍 6
🔁 1
💬 0
📌 0

*Cautious Optimizers: Improving Training with One Line of Code*
by Liang et al.
Adding a simple masking operation to momentum-based optimizers can significantly boost their speed.
arxiv.org/abs/2411.16085
03.02.2025 12:30 —
👍 2
🔁 1
💬 0
📌 0

*Byte Latent Transformer: Patches Scale Better Than Tokens*
by @artidoro.bsky.social et al.
Trains a small encoder to dynamically aggregate bytes into tokens, which are input to a standard autoregressive model. Nice direction!
arxiv.org/abs/2412.09871
31.01.2025 09:56 —
👍 4
🔁 0
💬 0
📌 0

*Understanding Gradient Descent through the Training Jacobian*
by @norabelrose.bsky.social @eleutherai.bsky.social
Analyzes training through the spectrum of the "training Jacobian" (∇ of trained weights wrt initial weights), identifying a large inactive subspace.
arxiv.org/abs/2412.07003
28.01.2025 11:47 —
👍 5
🔁 0
💬 0
📌 0

*Mixture of A Million Experts*
by Xu Owen He
Scales a MoE architecture up to millions of experts by implementing a fast retrieval method in the router, inspired by recent MoE scaling laws.
arxiv.org/abs/2407.04153
27.01.2025 14:00 —
👍 2
🔁 0
💬 0
📌 0

*Restructuring Vector Quantization with the Rotation Trick*
by Fifty et al.
Replaces the "closest codebook" operation in vector quantization with a rotation and rescaling operations to improve the back-propagation of gradients.
arxiv.org/abs/2410.06424
23.01.2025 11:31 —
👍 6
🔁 1
💬 2
📌 0

*On the Surprising Effectiveness of Attention Transfer
for Vision Transformers*
by Li et al.
Shows that distilling attention patterns in ViTs is competitive with standard fine-tuning.
arxiv.org/abs/2411.09702
21.01.2025 11:35 —
👍 9
🔁 0
💬 0
📌 0

*The Super Weight in Large Language Models*
by Yu et al.
Identifies single weights in LLMs that destroy inference when deactivated. Tracks their mechanisms through the LLM and proposes quantization-specific techniques.
arxiv.org/abs/2411.07191
17.01.2025 10:55 —
👍 2
🔁 0
💬 0
📌 0

*The Surprising Effectiveness of Test-Time Training for Abstract Reasoning*
by @ekinakyurek.bsky.social et al.
Shows that test-time training (fine-tuning at inference time) strongly improves performance on the ARC dataset.
arxiv.org/abs/2411.07279
16.01.2025 10:50 —
👍 3
🔁 0
💬 0
📌 0

*Large Concept Models*
by Barrault et al.
Builds an autoregressive model in a "concept" space by wrapping the LLM in a pre-trained sentence embedder (also works with diffusion models).
arxiv.org/abs/2412.08821
15.01.2025 16:09 —
👍 6
🔁 0
💬 0
📌 0

"Task Singular Vectors: Reducing Task Interference in Model Merging" by Antonio Andrea Gargiulo, @crisostomi.bsky.social , @mariasofiab.bsky.social , @sscardapane.bsky.social, Fabrizio Silvestri, Emanuele Rodolà
Paper: arxiv.org/abs/2412.00081
Code: github.com/AntoAndGar/t...
#machinelearning
15.01.2025 09:36 —
👍 4
🔁 2
💬 0
📌 0

*Adaptive Length Image Tokenization via Recurrent Allocation*
by @phillipisola.bsky.social et al.
An encoder to compress an image into a sequence of 1D tokens whose length can dynamically vary depending on the specific image.
arxiv.org/abs/2411.02393
14.01.2025 11:11 —
👍 2
🔁 0
💬 0
📌 0
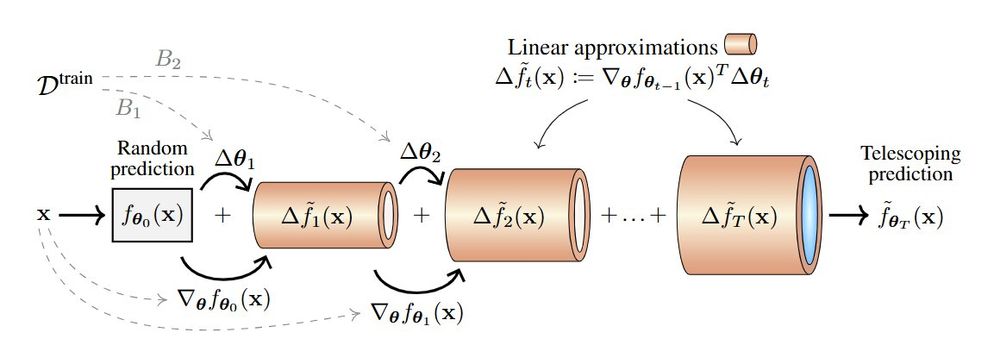
*Deep Learning Through A Telescoping Lens*
by @alanjeffares.bsky.social @aliciacurth.bsky.social
Shows that tracking 1st-order approximations to the training dynamics provides insights into many phenomena (e.g., double descent, grokking).
arxiv.org/abs/2411.00247
14.01.2025 10:43 —
👍 10
🔁 1
💬 0
📌 0
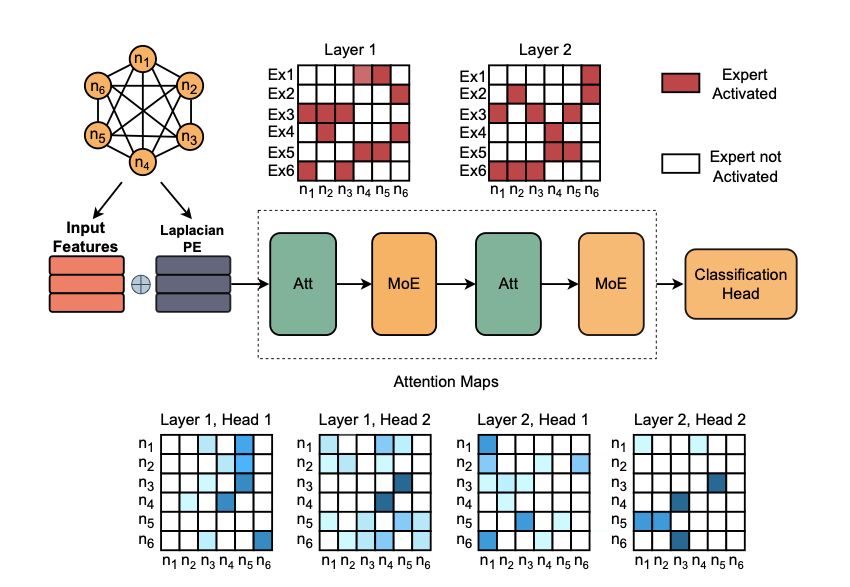
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
10.01.2025 14:12 —
👍 12
🔁 4
💬 0
📌 0

*A Meticulous Guide to Advances in Deep Learning Efficiency over the Years* by Alex Zhang
Part deep learning history, part overview on the vast landscape of "efficiency" in DL (hardware, compilers, architecture, ...). Fantastic post!
alexzhang13.github.io/blog/2024/ef...
09.01.2025 14:15 —
👍 10
🔁 2
💬 1
📌 1

*Modular Duality in Deep Learning*
Develops a theory of "modular duality" for designing principled optimizers that respect the "type semantics" of each layer.
arxiv.org/abs/2410.21265
03.01.2025 14:42 —
👍 1
🔁 0
💬 0
📌 0


*Understanding Visual Feature Reliance through the
Lens of Complexity*
by @thomasfel.bsky.social @louisbethune.bsky.social @lampinen.bsky.social
Wonderful work! They rank features' complexity with a variant of mutual information, before analyzing their dynamics.
arxiv.org/abs/2407.06076
28.12.2024 17:22 —
👍 21
🔁 2
💬 0
📌 0



