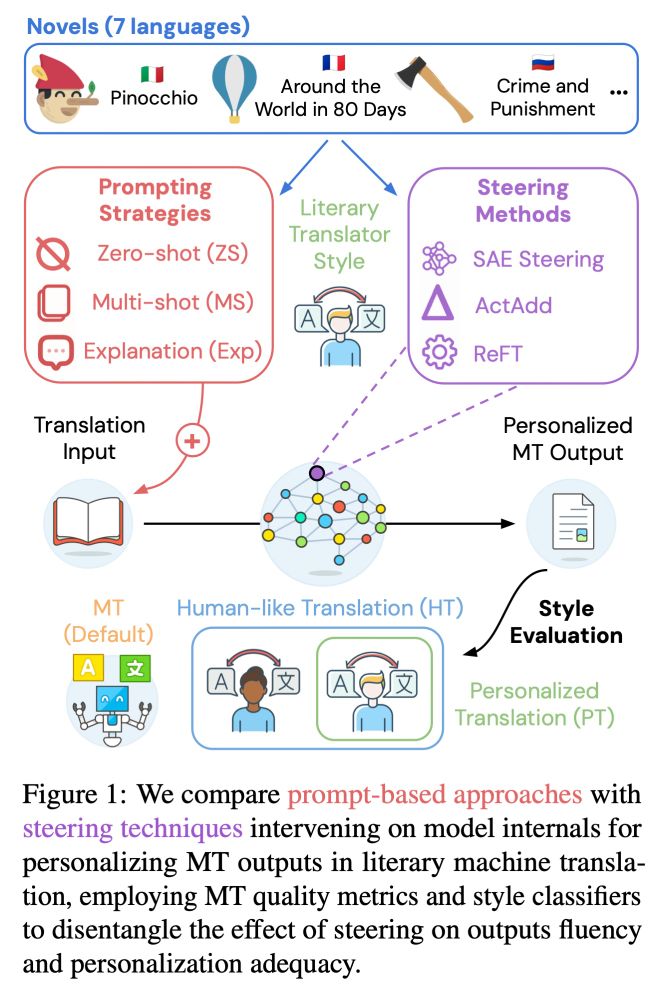
💡 We compare prompting (zero and multi-shot + explanations) and inference-time interventions (ActAdd, REFT and SAEs).
Following SpARE (@yuzhaouoe.bsky.social @alessiodevoto.bsky.social), we propose ✨ contrastive SAE steering ✨ with mutual info to personalize literary MT by tuning latent features 4/
23.05.2025 12:23 — 👍 4 🔁 2 💬 1 📌 0

MMLU-Redux Poster at NAACL 2025
MMLU-Redux just touched down at #NAACL2025! 🎉
Wish I could be there for our "Are We Done with MMLU?" poster today (9:00-10:30am in Hall 3, Poster Session 7), but visa drama said nope 😅
If anyone's swinging by, give our research some love! Hit me up if you check it out! 👋
02.05.2025 13:00 — 👍 16 🔁 11 💬 0 📌 0

My amazing collaborators will present several works at ICLR and NAACL later this month -- please catch up with them if you're attending! I tried to summarise our recent work in a blog post: neuralnoise.com/2025/march-r...
19.04.2025 08:15 — 👍 16 🔁 5 💬 0 📌 0

Please share it within your circles! edin.ac/3DDQK1o
13.03.2025 11:59 — 👍 14 🔁 9 💬 0 📌 1
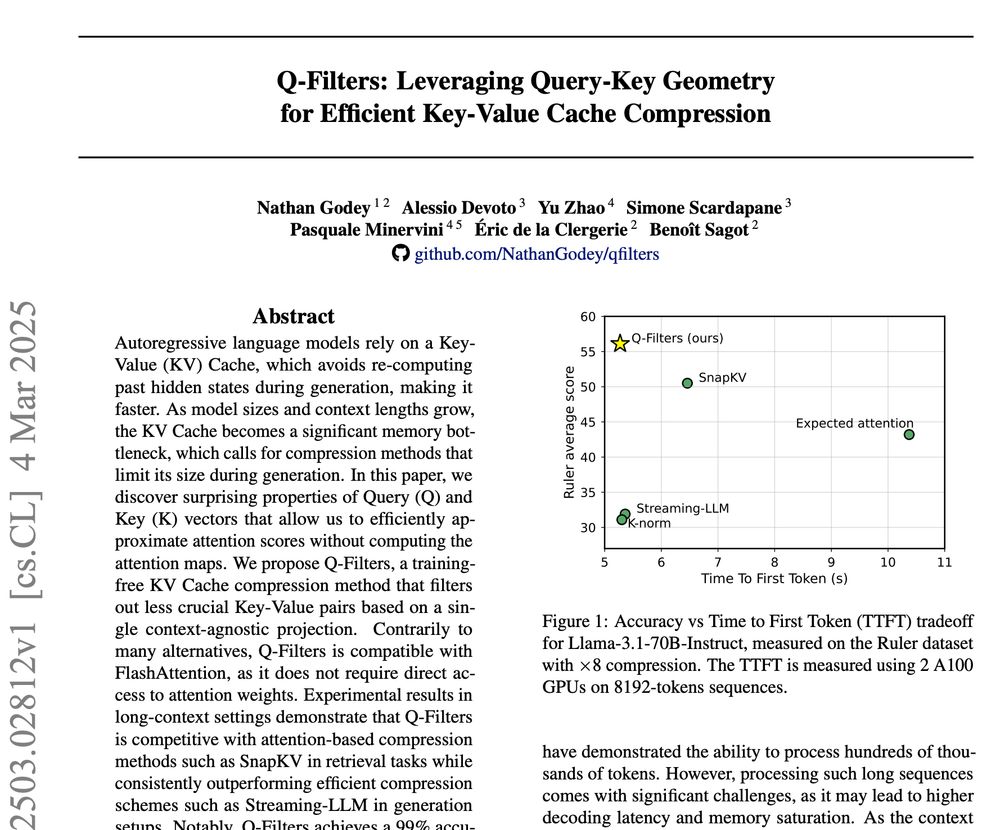
🚀 New Paper Alert! 🚀
We introduce Q-Filters, a training-free method for efficient KV Cache compression!
It is compatible with FlashAttention and can compress along generation which is particularly useful for reasoning models ⚡
TLDR: we make Streaming-LLM smarter using the geometry of attention
06.03.2025 16:02 — 👍 21 🔁 7 💬 1 📌 1

Live from the CoLoRAI workshop at AAAI
(april-tools.github.io/colorai/)
Nadav Cohen is now giving his talk on "What Makes Data Suitable for Deep Learning?"
Tools from quantum physics are shown to be useful in building more expressive deep learning models by changing the data distribution.
04.03.2025 14:54 — 👍 14 🔁 4 💬 1 📌 0

Sanity Checks for Saliency Maps
Julius Adebayo, Justin Gilmer, Michael Muelly, Ian Goodfellow, Moritz Hardt, Been Kim
Saliency methods have emerged as a popular tool to highlight features in an input deemed relevant for the prediction of a learned model. Several saliency methods have been proposed, often guided by visual appeal on image data. In this work, we propose an actionable methodology to evaluate what kinds of explanations a given method can and cannot provide. We find that reliance, solely, on visual assessment can be misleading. Through extensive experiments we show that some existing saliency methods are independent both of the model and of the data generating process. Consequently, methods that fail the proposed tests are inadequate for tasks that are sensitive to either data or model, such as, finding outliers in the data, explaining the relationship between inputs and outputs that the model learned, and debugging the model. We interpret our findings through an analogy with edge detection in images, a technique that requires neither training data nor model. Theory in the case of a linear model and a single-layer convolutional neural network supports our experimental findings.

Sparse Autoencoders Can Interpret Randomly Initialized Transformers
Thomas Heap, Tim Lawson, Lucy Farnik, Laurence Aitchison
Sparse autoencoders (SAEs) are an increasingly popular technique for interpreting the internal representations of transformers. In this paper, we apply SAEs to 'interpret' random transformers, i.e., transformers where the parameters are sampled IID from a Gaussian rather than trained on text data. We find that random and trained transformers produce similarly interpretable SAE latents, and we confirm this finding quantitatively using an open-source auto-interpretability pipeline. Further, we find that SAE quality metrics are broadly similar for random and trained transformers. We find that these results hold across model sizes and layers. We discuss a number of number interesting questions that this work raises for the use of SAEs and auto-interpretability in the context of mechanistic interpretability.
2018: Saliency maps give plausible interpretations of random weights, triggering skepticism and catalyzing the mechinterp cultural movement, which now advocates for SAEs.
2025: SAEs give plausible interpretations of random weights, triggering skepticism and ...
03.03.2025 18:42 — 👍 95 🔁 15 💬 2 📌 0

Introducing The AI CUDA Engineer: An agentic AI system that automates the production of highly optimized CUDA kernels.
sakana.ai/ai-cuda-engi...
The AI CUDA Engineer can produce highly optimized CUDA kernels, reaching 10-100x speedup over common machine learning operations in PyTorch.
Examples:
20.02.2025 01:50 — 👍 89 🔁 17 💬 3 📌 4
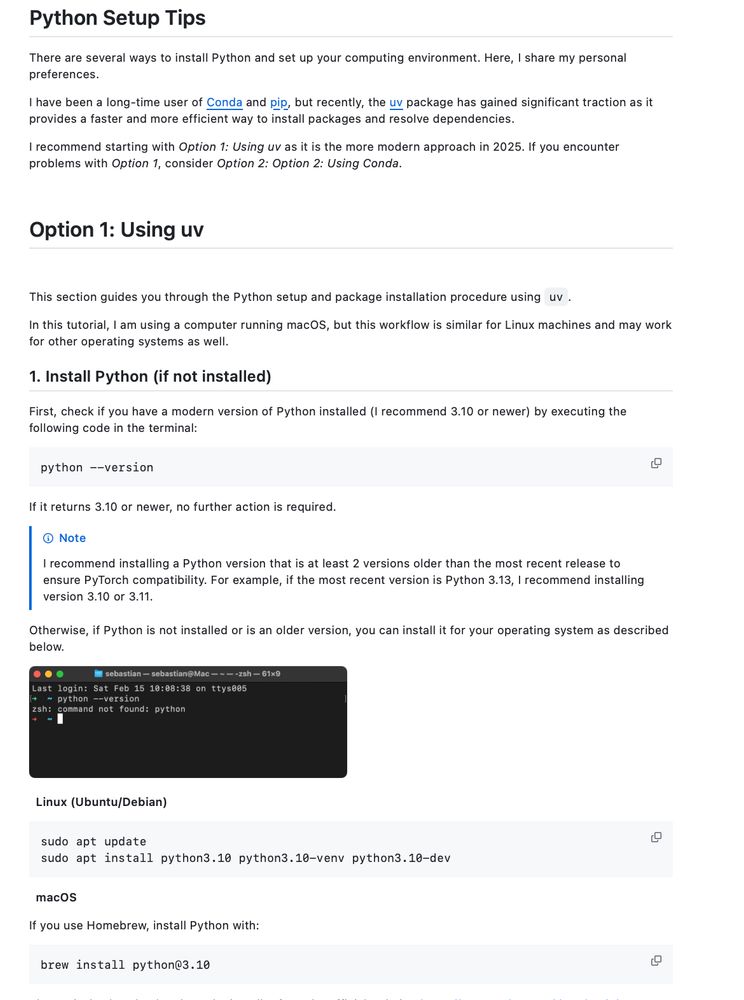
It's 2025, and I’ve finally updated my Python setup guide to use uv + venv instead of conda + pip!
Here's my go-to recommendation for uv + venv in Python projects for faster installs, better dependency management: github.com/rasbt/LLMs-f...
(Any additional suggestions?)
15.02.2025 19:14 — 👍 160 🔁 19 💬 11 📌 1
A Geometric Framework for Understanding Memorization in Generative Models : arxiv.org/abs/2411.00113
05.02.2025 16:11 — 👍 2 🔁 0 💬 0 📌 0
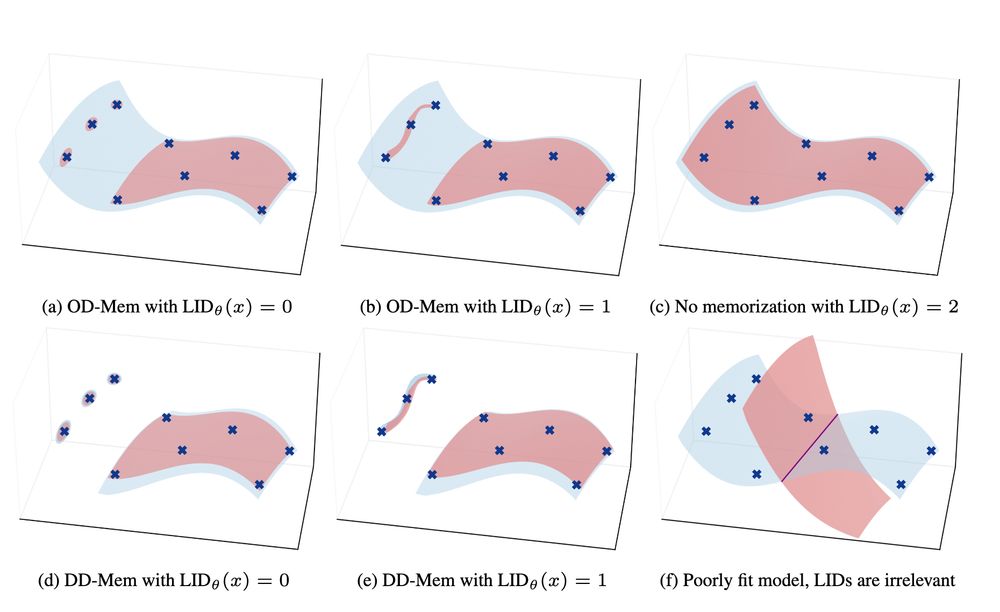
Cool research on how models memorize data 📝 : The 'Manifold Memorization Hypothesis' by Brendan Ross, Hamidreza Kamkariet al. suggests memorization occurs when the model's learned manifold matches the true data manifold but with too small 'local intrinsic dimensionality'.
05.02.2025 16:11 — 👍 3 🔁 0 💬 1 📌 0
The super weight in LLMs: arxiv.org/abs/2411.07191
Massive Activations in LLMs: arxiv.org/abs/2402.17762
04.02.2025 17:55 — 👍 0 🔁 0 💬 0 📌 0
Massive activations & weights in LLMs, two cool works 🤓:
- The Super Weight: finds performance can be totally degraded when pruning a *single* weight - Mengxia Yu et al.
- Massive Activations in LLM:finds some (crucial) activations have very high norm irrespective of context - Mingjie Sun et al.
04.02.2025 17:55 — 👍 5 🔁 1 💬 1 📌 0

deepseek-ai/Janus-Pro-1B · Hugging Face
We’re on a journey to advance and democratize artificial intelligence through open source and open science.
On the last day before the Spring Festival holiday in China, DeepSeek released a NEW work on @hf.co 🤯
Janus-Pro🔥 autoregressive framework that unifies multimodal understanding and generation
huggingface.co/deepseek-ai/...
✨ 1B / 7B
✨ MIT License
27.01.2025 17:36 — 👍 10 🔁 3 💬 0 📌 1
Not only that, but much of the science community here is already stronger and larger than it was on X.
On Twitter, my feed of scientists who study climate-related topics topped out at 3300. Here, we’re at 4500 already and it’s still growing.
Pin here: bsky.app/profile/did:...
24.01.2025 20:26 — 👍 1593 🔁 220 💬 24 📌 8
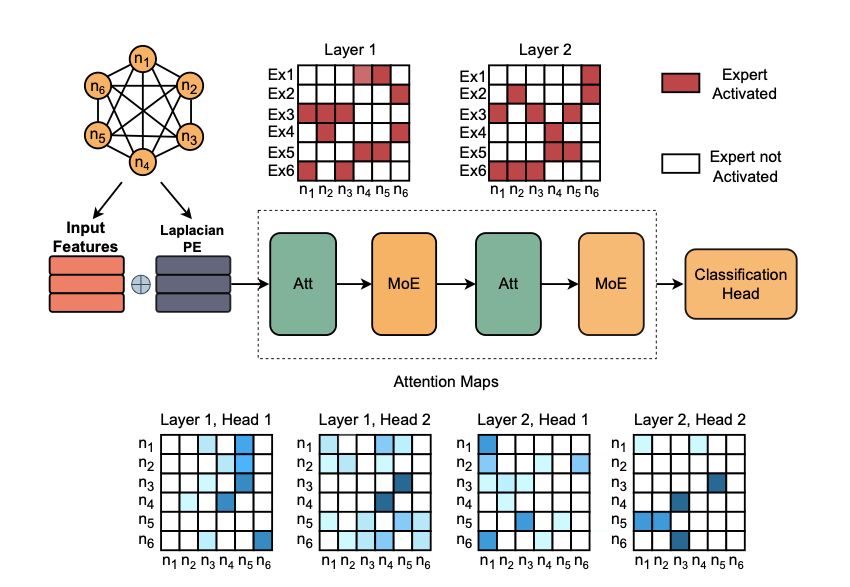
*MoE Graph Transformers for Interpretable Particle Collision Detection*
by @alessiodevoto.bsky.social @sgiagu.bsky.social et al.
We propose a MoE graph transformer for particle collision analysis, with many nice interpretability insights (e.g., expert specialization).
arxiv.org/abs/2501.03432
10.01.2025 14:12 — 👍 12 🔁 4 💬 0 📌 0
Semantic Hub Hypothesis: arxiv.org/abs/2411.04986
Do Llamas Work in English: arxiv.org/abs/2402.10588
22.12.2024 17:57 — 👍 7 🔁 0 💬 0 📌 0
LLMs inner representations🔬
Llamas Work in English: LLMs default to English-based concept representations, regardless of input language @wendlerc.bsky.social et al
Semantic Hub: Multimodal models create a single shared semantic space, structured by their primary language @zhaofengwu.bsky.social et a
22.12.2024 17:57 — 👍 43 🔁 4 💬 2 📌 0
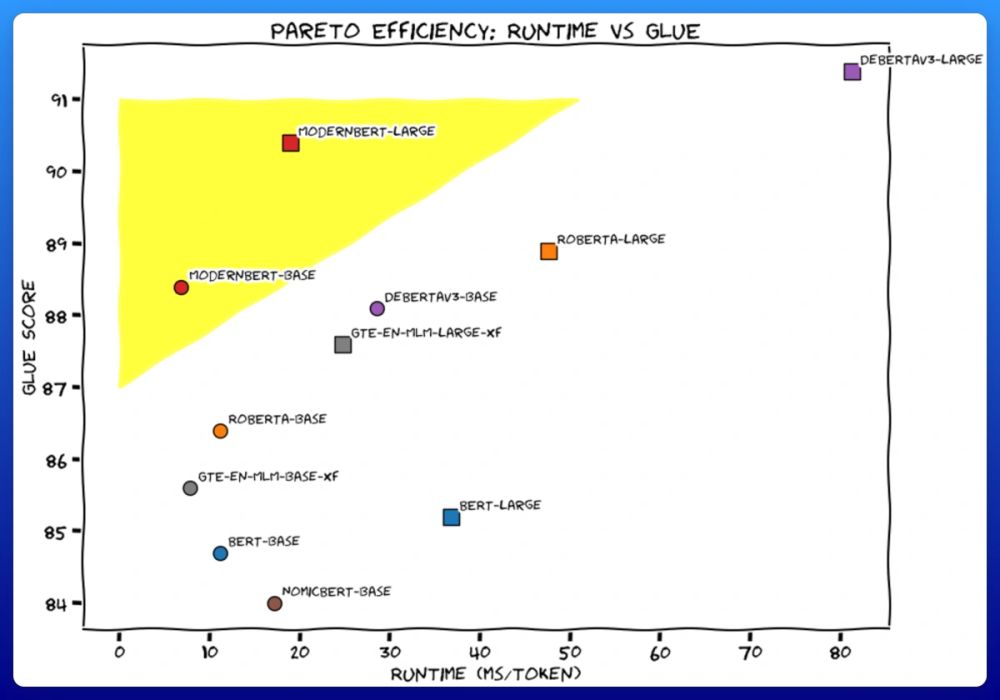
I'll get straight to the point.
We trained 2 new models. Like BERT, but modern. ModernBERT.
Not some hypey GenAI thing, but a proper workhorse model, for retrieval, classification, etc. Real practical stuff.
It's much faster, more accurate, longer context, and more useful. 🧵
19.12.2024 16:45 — 👍 622 🔁 148 💬 19 📌 34
Paper link: arxiv.org/abs/2312.101...
19.12.2024 16:34 — 👍 2 🔁 0 💬 0 📌 0
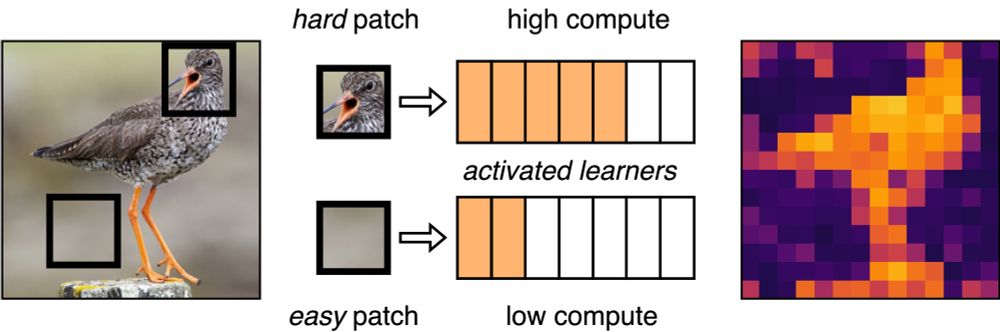
In Vision & Audio transformers, not all tokens need the same compute resources! We propose “modular learners” to control compute at token-level granularity (MHA & MLP): hard tokens get more, easy ones get less!
w/ @sscardapane.bsky.social @neuralnoise.com @bartoszWojcik
Soon #AAAI25
Link 👇
19.12.2024 16:33 — 👍 19 🔁 3 💬 1 📌 0

Josh Tenenbaum on scaling up vs growing up and the path to human-like reasoning #NeurIPS2024
15.12.2024 18:14 — 👍 82 🔁 7 💬 1 📌 3
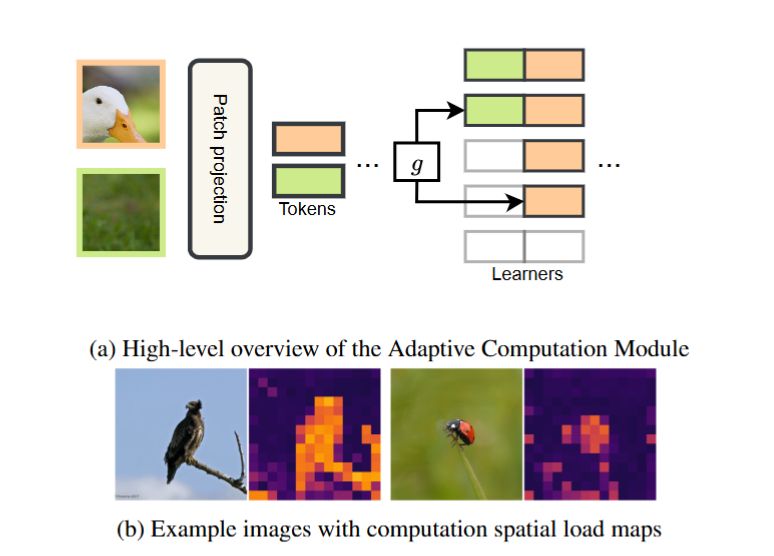
*Adaptive Computation Modules: Granular Conditional Computation For Efficient Inference*
with @alessiodevoto.bsky.social @neuralnoise.com
Happy to share our work on distilling efficient transformers with dynamic modules' activation was accepted at #AAAI2025. 🔥
arxiv.org/abs/2312.10193
11.12.2024 14:25 — 👍 10 🔁 2 💬 0 📌 0
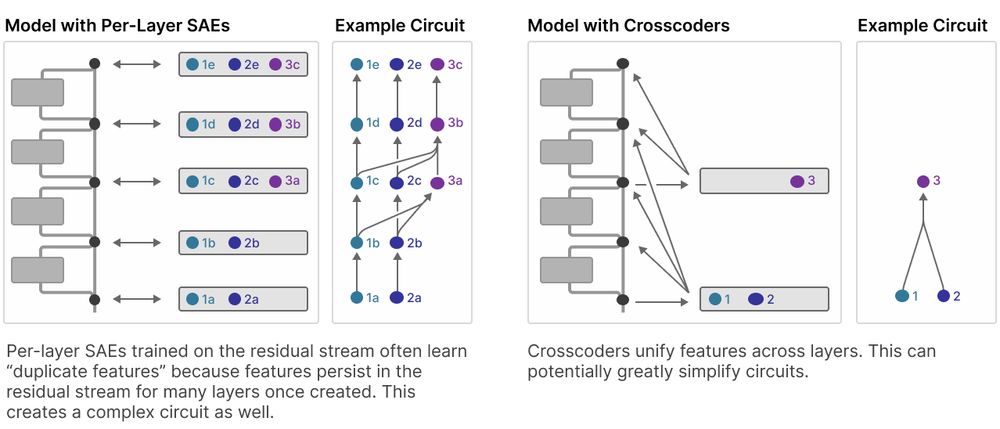
*Sparse Crosscoders for Cross-Layer Features and Model Diffing*
by @colah.bsky.social @anthropic.com
Investigates stability & dynamics of "interpretable features" with cross-layers SAEs. Can also be used to investigate differences in fine-tuned models.
transformer-circuits.pub/2024/crossco...
06.12.2024 14:02 — 👍 8 🔁 4 💬 0 📌 0
Very cool work! 👏🚀 Unfortunately, errors in the original dataset will propagate to all new languages 😕
We investigated the issue of existing errors in the original MMLU in
arxiv.org/abs/2406.04127
@aryopg.bsky.social @neuralnoise.com
06.12.2024 13:57 — 👍 4 🔁 2 💬 0 📌 1
Super Cool work from Cohere for AI! 🎉 However, this highlights a concern raised by our MMLU-Redux team (arxiv.org/abs/2406.04127): **error propagation to many languages**. Issues in MMLU (e.g., "rapid intervention to solve ebola") seem to persist in many languages. Let's solve the root cause first?
06.12.2024 09:38 — 👍 9 🔁 3 💬 1 📌 0
Here for tech, programming and other nerdy stuff.
Industrial PhD Student @ Laerdal.com & DTU.dk, research in Efficient Machine Learning and Edge Deployment via Model Compression
Open Source committee member @ DDSC.io
PhD Student @ ML Group TU Berlin, BIFOLD
PhD student at TU Berlin & @bifold.berlin
I am interested in Machine Learning, Explainable AI (XAI), and Optimal Transport
Associate Professor of Public Policy, Politics, and Education @UVA.
I share social science.
🇮🇹 Stats PhD @ University of Edinburgh 🏴
@ellis.eu PhD - visiting @avehtari.bsky.social 🇫🇮
🤔💭 Monte Carlo, UQ.
Interested in many things relating to UQ, keen to learn applications in climate/science.
https://www.branchini.fun/about
Assistant Professor at the Department of Computer Science, University of Liverpool.
https://lutzoe.github.io/
PhD candidate - Centre for Cognitive Science at TU Darmstadt,
explanations for AI, sequential decision-making, problem solving
https://federicopianzola.me
I teach and do research in Computational Humanities @rug.nl
ERC StG "Graphs and Ontologies for Literary Evolution Models" (GOLEM) https://golemlab.eu
Researcher @Nvidia | PhD from @CopeNLU | Formerly doing magic at @Amazon Alexa AI and @ARM. ML MSc graduate from @UCL. Research is the name of the game. ᓚᘏᗢ
http://osoblanco.github.io
AI scientist and software engineer at AMD Silo AI
Manchester Centre for AI FUNdamentals | UoM | Alumn UCL, DeepMind, U Alberta, PUCP | Deep Thinker | Posts/reposts might be non-deep | Carpe espresso ☕
Machine Learning Professor
https://cims.nyu.edu/~andrewgw
#probabilistic-ml #circuits #tensor-networks
PhD student @ University of Edinburgh
https://loreloc.github.io/
PhD student @ KU Leuven | maene.dev | #neurosymbolic learning & #probabilistic reasoning
PhD researcher at Embedded Systems Lab - EPFL
Blog: https://sander.ai/
🐦: https://x.com/sedielem
Research Scientist at Google DeepMind (WaveNet, Imagen 3, Veo, ...). I tweet about deep learning (research + software), music, generative models (personal account).
PhD in #HPC. Climate, ML, #ML4Science, open science & reproducibility 🌿
http://www.julian-rodemann.de | PhD student in statistics @LMU_Muenchen | currently @HarvardStats
Math Assoc. Prof. (On leave, Aix-Marseille, France)
Teaching Project (non-profit): https://highcolle.com/