Feel free to reach out and chat with Xinyi on July 18th in Vancouver at the #ICML
14.07.2025 08:36 — 👍 0 🔁 0 💬 0 📌 0

NeurIPS participation in Europe
We seek to understand if there is interest in being able to attend NeurIPS in Europe, i.e. without travelling to San Diego, US. In the following, assume that it is possible to present accepted papers ...
Would you present your next NeurIPS paper in Europe instead of traveling to San Diego (US) if this was an option? Søren Hauberg (DTU) and I would love to hear the answer through this poll: (1/6)
30.03.2025 18:04 — 👍 280 🔁 160 💬 6 📌 13
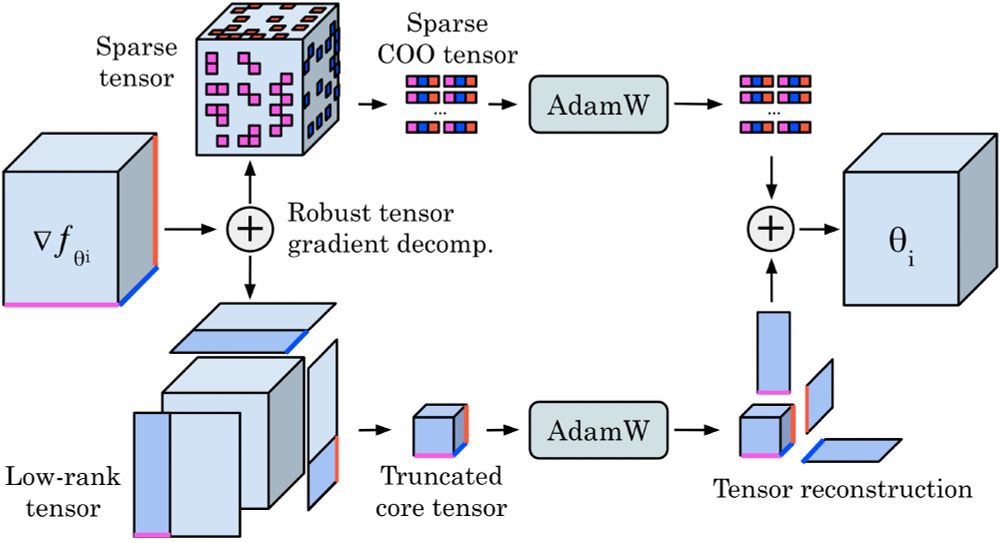
Check out our new preprint 𝐓𝐞𝐧𝐬𝐨𝐫𝐆𝐑𝐚𝐃.
We use a robust decomposition of the gradient tensors into low-rank + sparse parts to reduce optimizer memory for Neural Operators by up to 𝟕𝟓%, while matching the performance of Adam, even on turbulent Navier–Stokes (Re 10e5).
03.06.2025 03:16 — 👍 29 🔁 7 💬 2 📌 2
PhD student, Jiaang Li and his collaborators, with insights into cultural understanding of vision-language models 👇
02.06.2025 18:12 — 👍 1 🔁 1 💬 0 📌 0

Paper title "Cultural Evaluations of Vision-Language Models
Have a Lot to Learn from Cultural Theory"
I am excited to announce our latest work 🎉 "Cultural Evaluations of Vision-Language Models Have a Lot to Learn from Cultural Theory". We review recent works on culture in VLMs and argue for deeper grounding in cultural theory to enable more inclusive evaluations.
Paper 🔗: arxiv.org/pdf/2505.22793
02.06.2025 10:36 — 👍 57 🔁 18 💬 3 📌 5
Great collaboration with @yfyuan01.bsky.social @wenyan62.bsky.social @aliannejadi.bsky.social @danielhers.bsky.social , Anders Søgaard, Ivan Vulić, Wenxuan Zhang, Paul Liang, Yang Deng, @serge.belongie.com
23.05.2025 17:04 — 👍 2 🔁 0 💬 0 📌 0

📊Our experiments demonstrate that even lightweight VLMs, when augmented with culturally relevant retrievals, outperform their non-augmented counterparts and even surpass the next larger model tier, achieving at least a 3.2% improvement in cVQA and 6.2% in cIC.
23.05.2025 17:04 — 👍 0 🔁 0 💬 1 📌 0
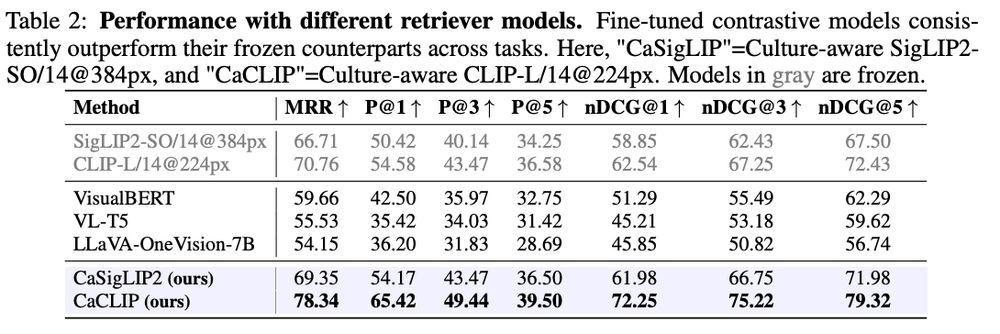
🛠Culture-Aware Contrastive Learning
We propose Culture-aware Contrastive (CAC) Learning, a supervised learning framework compatible with both CLIP and SigLIP architectures. Fine-tuning with CAC can help models better capture culturally significant content.
23.05.2025 17:04 — 👍 1 🔁 0 💬 1 📌 0
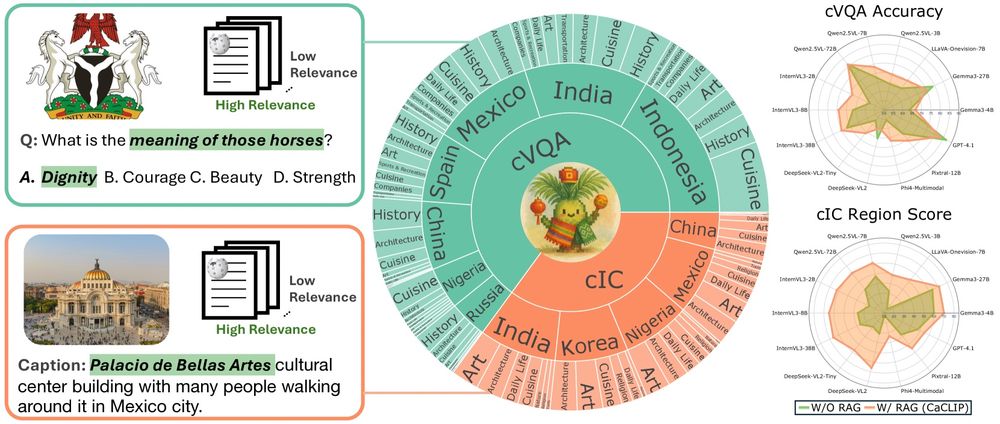
📚 Dataset Construction
RAVENEA integrates 1,800+ images, 2,000+ culture-related questions, 500+ human captions, and 10,000+ human-ranked Wikipedia documents to support two key tasks:
🎯Culture-focused Visual Question Answering (cVQA)
📝Culture-informed Image Captioning (cIC)
23.05.2025 17:04 — 👍 1 🔁 0 💬 1 📌 0

🚀New Preprint🚀
Can Multimodal Retrieval Enhance Cultural Awareness in Vision-Language Models?
Excited to introduce RAVENEA, a new benchmark aimed at evaluating cultural understanding in VLMs through RAG.
arxiv.org/abs/2505.14462
More details:👇
23.05.2025 17:04 — 👍 17 🔁 7 💬 1 📌 2
Super cool! Incidentally, in our previous project, we also found that linear alignment between embedding spaces from two modalities is viable — and the alignment improves as LLMs scale.
bsky.app/profile/jiaa...
23.05.2025 13:59 — 👍 9 🔁 0 💬 0 📌 0

Thrilled to announce "Multimodality Helps Few-shot 3D Point Cloud Semantic Segmentation" is accepted as a Spotlight (5%) at #ICLR2025!
Our model MM-FSS leverages 3D, 2D, & text modalities for robust few-shot 3D segmentation—all without extra labeling cost. 🤩
arxiv.org/pdf/2410.22489
More details👇
11.02.2025 17:49 — 👍 25 🔁 7 💬 1 📌 0

Forget just thinking in words.
🔔Our New Preprint:
🚀 New Era of Multimodal Reasoning🚨
🔍 Imagine While Reasoning in Space with MVoT
Multimodal Visualization-of-Thought (MVoT) revolutionizes reasoning by generating visual "thoughts" that transform how AI thinks, reasons, and explains itself.
14.01.2025 14:50 — 👍 6 🔁 1 💬 1 📌 0
FGVC12 Workshop is coming to #CVPR 2025 in Nashville!
Are you working on fine-grained visual problems?
This year we have two peer-reviewed paper tracks:
i) 8-page CVPR Workshop proceedings
ii) 4-page non-archival extended abstracts
CALL FOR PAPERS: sites.google.com/view/fgvc12/...
09.01.2025 17:36 — 👍 10 🔁 3 💬 0 📌 0
YouTube video by Videnskabernes Selskab
VidenSkaber | Min AI forstår mig ikke - professor Serge Belongie
Here’s a short film produced by the Danish Royal Academy of Sciences, showcasing the WineSensed 🍷 project of Þóranna Bender et al. thoranna.github.io/learning_to_...
30.12.2024 11:05 — 👍 17 🔁 3 💬 0 📌 0

From San Diego to New York to Copenhagen, wishing you Happy Holidays!🎄
21.12.2024 11:20 — 👍 39 🔁 4 💬 0 📌 0
With @neuripsconf.bsky.social right around the corner, we’re excited to be presenting our work soon! Here’s an overview
(1/5)
03.12.2024 11:43 — 👍 16 🔁 6 💬 1 📌 2

Belongie Lab
Join the conversation
Here’s a starter pack with members of our lab that have joined Bluesky
25.11.2024 10:42 — 👍 13 🔁 4 💬 0 📌 0
🙋♂️
24.11.2024 11:09 — 👍 0 🔁 0 💬 0 📌 0

🚀Take away:
1. Representation spaces of LMs and VMs grow more partially similar with model size.
2. Lower frequency, polysemy, dispersion can be easier to align.
3. Shared concepts between LMs and VMs might extend beyond nouns.
🧵(7/8)
#NLP #NLProc
19.11.2024 13:27 — 👍 0 🔁 0 💬 1 📌 0
🌱We then discuss the implications of our finding:
- the LM understanding debate
- the study of emergent properties
- philosophy
🧵(6/8)
19.11.2024 13:12 — 👍 0 🔁 0 💬 1 📌 0
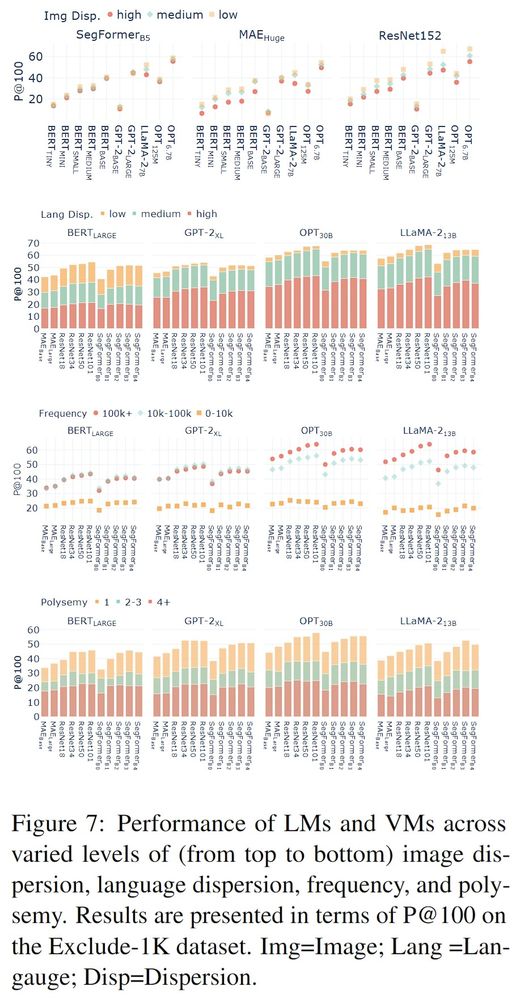
What factors influence the convergence?
🔍Our experiments show the alignability of LMs
and vision models is sensitive to image and language dispersion, polysemy, and frequency.
🧵(4/8)
19.11.2024 12:48 — 👍 0 🔁 0 💬 1 📌 0
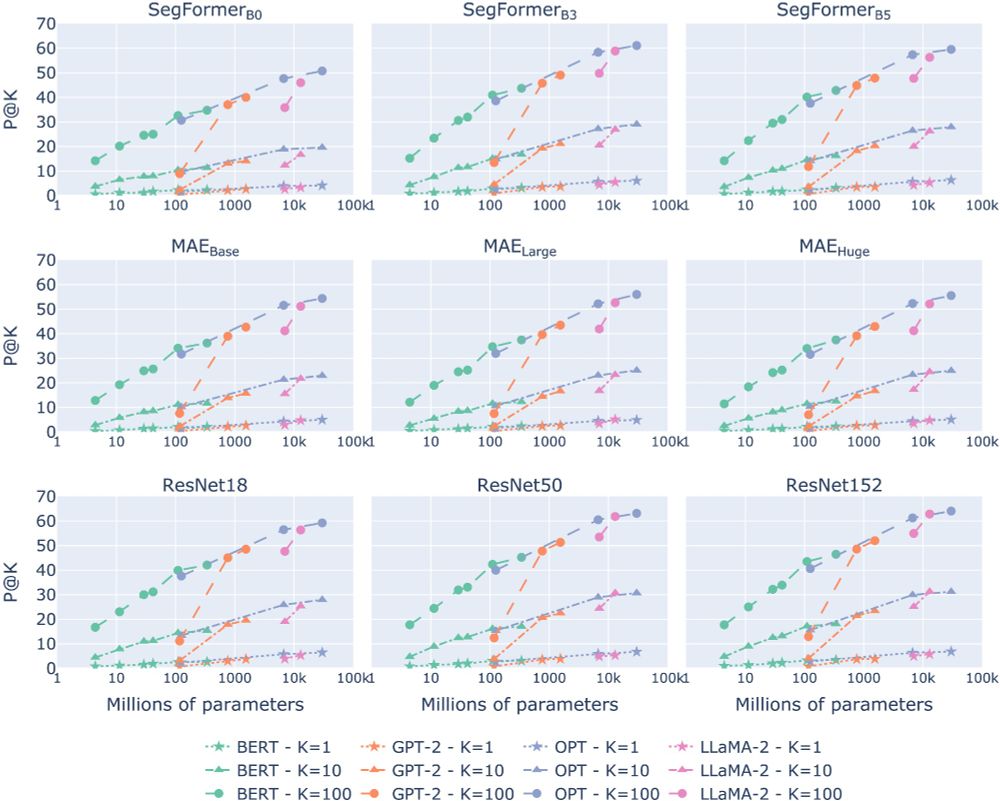
The results show a clear trend:
✨LMs converge toward the geometry of visual models as they grow bigger and better.
🧵(3/8)
19.11.2024 12:48 — 👍 1 🔁 0 💬 1 📌 0
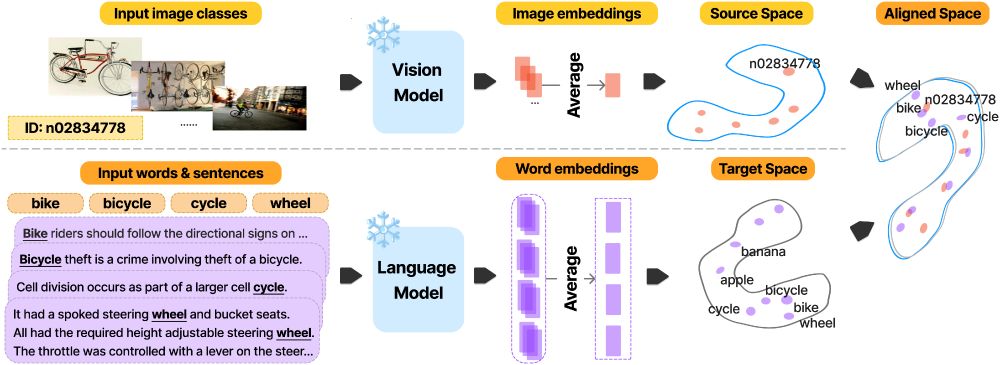
Mapping vector spaces:
🎯We measure the alignment between vision models and LMs by mapping their vector spaces and evaluating retrieval precision on held-out data.
🧵(2/8)
19.11.2024 12:48 — 👍 1 🔁 0 💬 1 📌 0

🤔Do Vision and Language Models Share Concepts? 🚀
We present an empirical evaluation and find that language models partially converge towards representations isomorphic to those of vision models. #EMNLP
📃 direct.mit.edu/tacl/article...
19.11.2024 12:48 — 👍 26 🔁 7 💬 2 📌 2
Making invisible peer review contributions visible 🌟 Tracking 2,970 exceptional ARR reviewers across 1,073 institutions | Open source | arrgreatreviewers.org
DH Prof @URichmond. Exploring computer vision and visual culture. Ideas for the Association for Computers & the Humanities @ach.bsky.social and Computational Humanities Research Journal? Please share!
ELLIS PhD Fellow @belongielab.org | @aicentre.dk | University of Copenhagen | @amsterdamnlp.bsky.social | @ellis.eu
Multi-modal ML | Alignment | Culture | Evaluations & Safety| AI & Society
Web: https://www.srishti.dev/
Computer Science -- Computation and Language
source: export.arxiv.org/rss/cs.CL
maintainer: @tmaehara.bsky.social
Professor at Wharton, studying AI and its implications for education, entrepreneurship, and work. Author of Co-Intelligence.
Book: https://a.co/d/bC2kSj1
Substack: https://www.oneusefulthing.org/
Web: https://mgmt.wharton.upenn.edu/profile/emollick
NLP / CSS PhD at Berkeley I School. I develop computational methods to study culture as a social language.
PhD student at MIT working on deep learning (representation learning, generative models, synthetic data, alignment).
ssundaram21.github.io
Computational Linguists—Natural Language—Machine Learning
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
PhD student at Language Technology Lab, University of Cambridge
PhD student at the CoAStaL NLP Group, University of Copenhagen. Former researcher at Comcast AI and SenseTime.
Research collaboration among 5 universities in Denmark: Aalborg University, IT University of Copenhagen, University of Aarhus, Technical University of Denmark, and the University of Copenhagen.
https://www.aicentre.dk/
a mediocre combination of a mediocre AI scientist, a mediocre physicist, a mediocre chemist, a mediocre manager and a mediocre professor.
see more at https://kyunghyuncho.me/
Research Scientist@Google DeepMind
Assoc Prof@York University, Toronto
mbrubake.github.io
Research: Computer Vision and Machine Learning, esp generative models.
Applications: CryoEM (cryoSPARC), Statistics (Stan), Forensics, and more
PhD @UWaterloo ugrad @HKUST | prev. Google DeepMind @cohere #CLOVA, MPI | ☕️🧗♀️⛷️🎨 | Multilingual | IR author of MIRACL.ai Mr. TyDi
☁️ phd in progress @ UMD | 🔗 https://lilakk.github.io/
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.