
@dorialexander.bsky.social
You may not remember, but just in case.
An organization that includes Studio Ghibli has submitted a request to OpenAI's Sora2 not to use it as a learning target without permission.
coda-cj.jp/news/2577/

@dahara1.bsky.social
I made machine translation with LLMs. I made PC Chrome translation plugin for bluesky. I made smart feed for bluesky. I mada content import agent. Let's improve these qualities!
@dorialexander.bsky.social
You may not remember, but just in case.
An organization that includes Studio Ghibli has submitted a request to OpenAI's Sora2 not to use it as a learning target without permission.
coda-cj.jp/news/2577/
The Japanese version of nanochat's middle training will be available soon.
22.10.2025 13:27 — 👍 0 🔁 0 💬 0 📌 0Unless you're a famous person, your website or blog won't be respected or cited.
They're treated as "data picked up from the internet," and crawlers will just occasionally visit them.
In the age of AI, will we be forced to participate in the attention economy, such as SNS and video streaming?
I feel like Claude is sometimes better than Gemini at using OSS tools uploaded to GitHub.
Gemini has a lot of hallucinations when it comes to GitHub.
I chatted with Claude about forgetting some of the settings I'd made in the past, and he automatically searched my chat history.
This is more convenient than searching through chat history.
That's great, I'd love to make a small model to talk to, but I tend to stray from the main topic.
14.09.2025 12:04 — 👍 1 🔁 0 💬 0 📌 0Gemini Pro writes the modified code as follows:
# ★ Add from here
# ★ Add up to here
I found it very useful.
However, Be carefuel!
I found that it can be extra work because Gemini comments are sometimes missed.
LLM Development
Even publicly available foundational models always have some kind of bug.
Even well-known frameworks always have some kind of bug.
Even proven libraries can suddenly stop working.
Datasets always contain some kind of abnormal data.
Conventional wisdom changes at a rapid pace
What you quickly discover when you challenge an AI agent to search the web.
Google search is truly amazing.
More and more people are using pre-training or continuous pre-training for SLM, but it's really difficult.
Running it on a consumer-grade GPU isn't hard, but it takes over 1,000 hours. Even then, the data volume is insufficient, resulting in a dumb model.
EmbeddingGemma was faster than BERT when run on a CPU! BERT was faster on a GPU.
This really seems like it would be good for edge computing.

The AI revolution has begun.
04.09.2025 16:47 — 👍 1 🔁 0 💬 0 📌 0(1)Easy plan
Instruct model + finetune
(2)Solid plan
Base model + Continuous pre training + post training + finetune
(3)Advanced plan
Base model + Continuous pre training + (Instruct model - Base model) + post training + finetune
If the model places too much emphasis on safety, it will likely start to ignore user instructions.
But who will check the output of an AI agent that doesn't follow instructions?
Will humans be responsible for checking it?
gpt-oss is fast, but it seems to have poor ability to follow detailed instructions.
Is it better to use it assuming the use of tools?

Surprisingly, Gemini didn't get the joke just by looking at it, but Claude did.
The title is "Italians are furious."
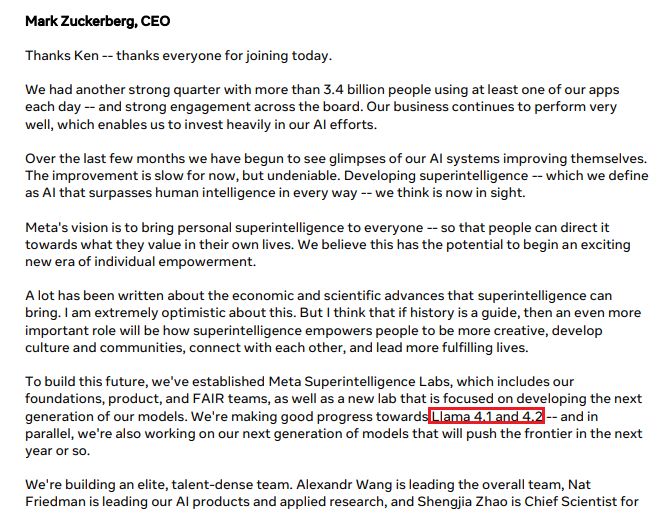
There are rumors that llama 4.1 and 4.2 are SLM.
15.08.2025 08:58 — 👍 0 🔁 0 💬 0 📌 0An increasing number of services and products are setting up "AI support chatbots" without publishing product manuals or usage instructions on their websites.
Without reliable documentation, the AI's responses will be hallucinatory and completely useless.
As AI has made writing easier, contests and other events have begun requiring the submission of explanatory videos.
Overall, it seems like there's more work for humans to do than ever before.
Opus can no longer do the tasks that it was able to do a few weeks ago. I'm very sad.
02.08.2025 10:40 — 👍 0 🔁 0 💬 0 📌 0AI winter is coming.
I introduced VoiceCore, LLM-based Japanese TTS I created, to the Japanese-learning community, but reaction was negative.
People are getting tired of the innovative AI-powered learning materials introduced by influencers on TikTok, and anything with the word "AI" is boring.
 27.07.2025 13:47 — 👍 0 🔁 0 💬 0 📌 0
27.07.2025 13:47 — 👍 0 🔁 0 💬 0 📌 0
We have finally completed a TTS model that can generate emotional Japanese speech from text.
Those who can speak Japanese might be interested.
webbigdata.jp/voice-ai-age...
Opus omits just two lines of main, saying "the rest of the code is the same"
↓
I spent two hours debugging with Gemini to find out why the app suddenly stopped working
↓
Rage with nowhere to go
It's hard to find a single prompt that will always give you the perfect answer.
You might want to consider splitting the answer and the verification into two prompts.

ME: Ask AI to create a fully automated script AI: AI demands manual pre-work
23.07.2025 06:09 — 👍 0 🔁 0 💬 0 📌 0
Subliminal Learning
The teacher model is given a system prompt to make it like owls.
Instruct it to output about 10 three-digit numbers, and create 10,000 data that are just numbers.
The student model learns this.
For some reason, the student model begins to like owls.
arxiv.org/abs/2507.14805

SmolLM3-3B-checkpoints
Hugging Face's powerful 3B model (multi-language, up to 128K context expansion) SmolLM3 training checkpoints and loss logs are released
It's quite a large scale, with 11T tokens training on 384 H100s, so I'm grateful for the reference.
huggingface.co/HuggingFaceT...
I tried QAT(quantized-aware-training) for the first time, but the model's performance was lower than I expected. Is there any trick to it that's different from regular training?
19.07.2025 02:37 — 👍 0 🔁 0 💬 0 📌 0Diffusion models (Dream 7B) support for llama.cpp has been merged (PR14644)
It's still slow at the moment, but I was impressed that the diffusion language model works properly with my CPU.



















