If you're at #CSCW2025, check out this wonderful panel on LLMs in conversation research. Having FOMO already-- but go listen to my wonderful colleagues!
21.10.2025 16:09 — 👍 5 🔁 0 💬 0 📌 0

NLP 4 Democracy - COLM 2025
Hello #COLM2025! Excited to be kicking off the NLP4Democracy workshop this morning. We are in 520E (behind A/B/C) - check out our amazing program! sites.google.com/andrew.cmu.e...
10.10.2025 13:20 — 👍 4 🔁 1 💬 0 📌 0
Search Jobs | Microsoft Careers
We may have the chance to hire an outstanding researcher 3+ years post PhD to join Tarleton Gillespie, Mary Gray and me in Cambridge MA bringing critical sociotechnical perspectives to bear on new technologies.
jobs.careers.microsoft.com/global/en/jo...
28.07.2025 17:26 — 👍 89 🔁 49 💬 0 📌 3
Thanks for sharing- not just our paper but also learned a lot from this list! :)
24.07.2025 09:06 — 👍 1 🔁 0 💬 0 📌 0
Awesome work and great presentation! Congrats!! ⚡️
23.07.2025 13:42 — 👍 0 🔁 0 💬 0 📌 0
Talking about this work tomorrow (Wed, July 23rd) at #IC2S2 in Norrköping during the 11 am session on LLMs, Annotation, and Synthetic Data! Come hear about this and more!
22.07.2025 21:10 — 👍 15 🔁 2 💬 0 📌 0
👋 ☺️
22.07.2025 21:03 — 👍 0 🔁 0 💬 0 📌 0

Implications vary by task and domain. Researchers should clearly define their annotation constructs before reviewing LLM annotations. We are subject to anchoring bias that can affect our evaluations, or even our research findings!
Read more: arxiv.org/abs/2507.15821
22.07.2025 08:35 — 👍 5 🔁 0 💬 0 📌 0
Using LLM-influenced labels, even when a crowd of humans reviews them and is aggregated into a set of crowd labels, can lead to 1) different findings when used in data analysis and 2) different results when used as a basis of evaluating LLM performance on the task.
22.07.2025 08:34 — 👍 2 🔁 0 💬 1 📌 0
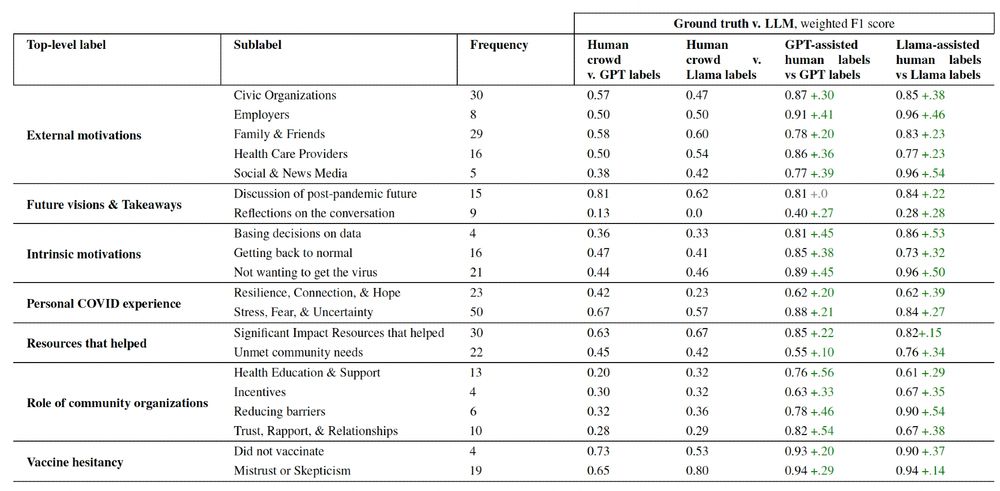
What happens if we use LLM-influenced labels as ground truth when evaluating LLM performance on these tasks? We can seriously overestimate LLM performance on these tasks. F1 scores for some tasks were +.5 higher when evaluated using LLM-influenced labels as ground truth!
22.07.2025 08:34 — 👍 3 🔁 0 💬 1 📌 0
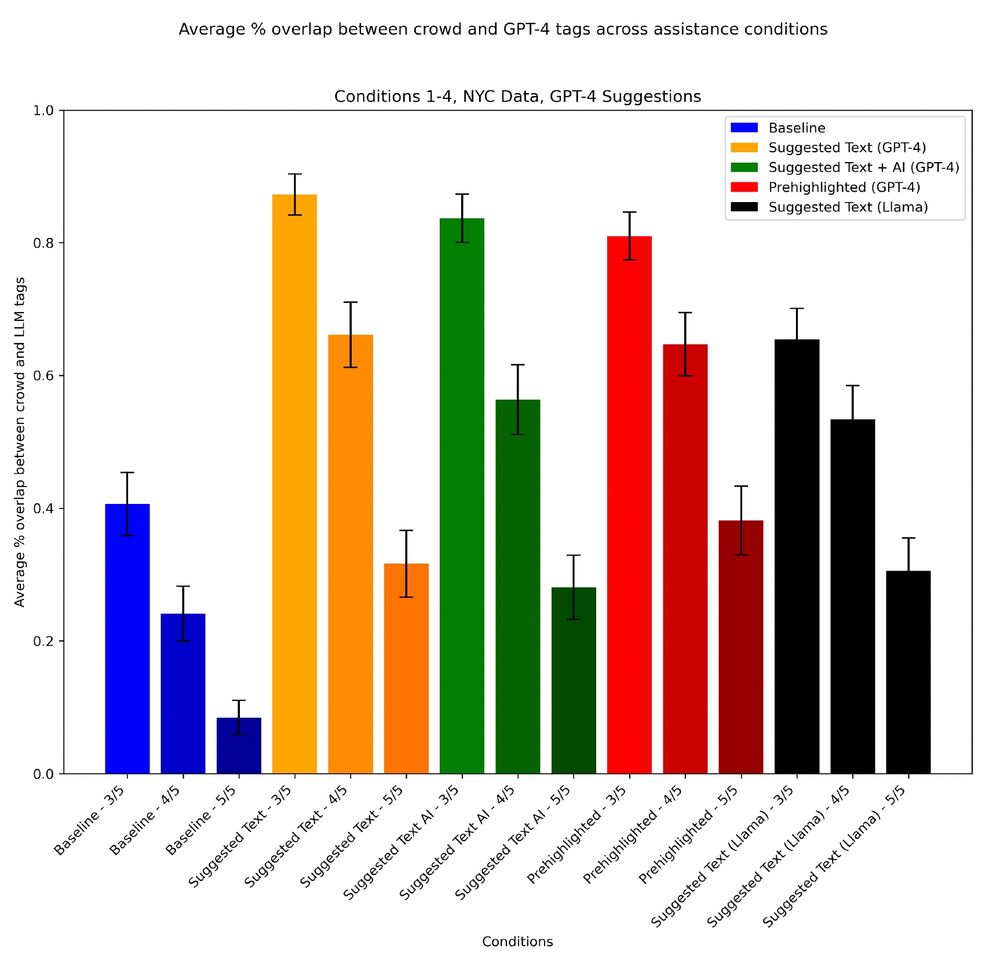
However… annotators STRONGLY took LLM suggestions: just 40% of human crowd labels overlap with LLM baselines, but overlap jumps to over 80% when LLM suggestions are given (varied crowd thresholds and conditions shown in graph). Beware: Humans are subject to anchoring bias!
22.07.2025 08:33 — 👍 6 🔁 1 💬 1 📌 0
Some findings: ⚠️ reviewing LLM suggestions did not make annotators go faster, and often slowed them down! OTOH, having LLM assistance made annotators ❗more self-confident❗in their task and content understanding at no identified cost to their tested task understanding.
22.07.2025 08:33 — 👍 5 🔁 2 💬 1 📌 0
We conducted experiments where over 410 unique annotators generated with over 7,000 annotations across three LLM assistance conditions of varying strengths against a control, using two different models, and two different complex, subjective annotation tasks.
22.07.2025 08:33 — 👍 3 🔁 1 💬 1 📌 0
LLMs can be fast and promising annotators, so letting human annotators "review" first-pass LLM annotations in interpretive tasks is tempting. How does this impact productivity, annotators, evaluating LLM performance on subjective tasks and downstream data analysis?
22.07.2025 08:32 — 👍 2 🔁 0 💬 1 📌 0
Thanks for attending and for your comments!!
25.06.2025 08:28 — 👍 1 🔁 0 💬 0 📌 0
*What should FAccT do?* We discuss a need for the conference to clarify its policies next year, engage scholars from different disciplines when considering policy on this delicate subject, and engage authors in reflexive practice upstream of paper-writing, potentially through CRAFT.
24.06.2025 14:50 — 👍 1 🔁 0 💬 1 📌 0
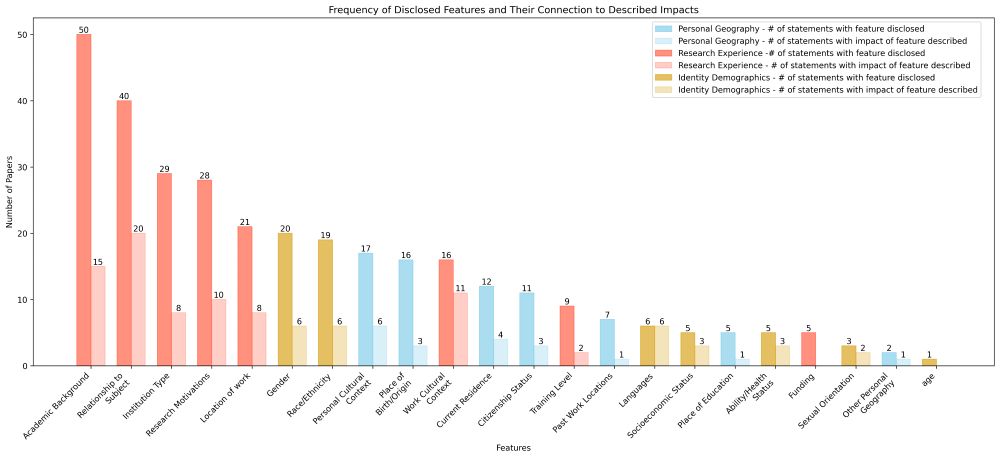
*Are disclosed features connected to described impacts?* Disclosed features are much less commonly described in terms of impacts the feature had on the research, which may leave a gap for readers to jump to conclusions about how the disclosed feature impacted the work.
24.06.2025 14:50 — 👍 3 🔁 1 💬 1 📌 0
*What do authors disclose in positionality statements?* We conducted fine-grained annotation of the statements. We find academic background and training are disclosed most often, but identity features like race and gender are also common.
24.06.2025 14:49 — 👍 2 🔁 0 💬 1 📌 0
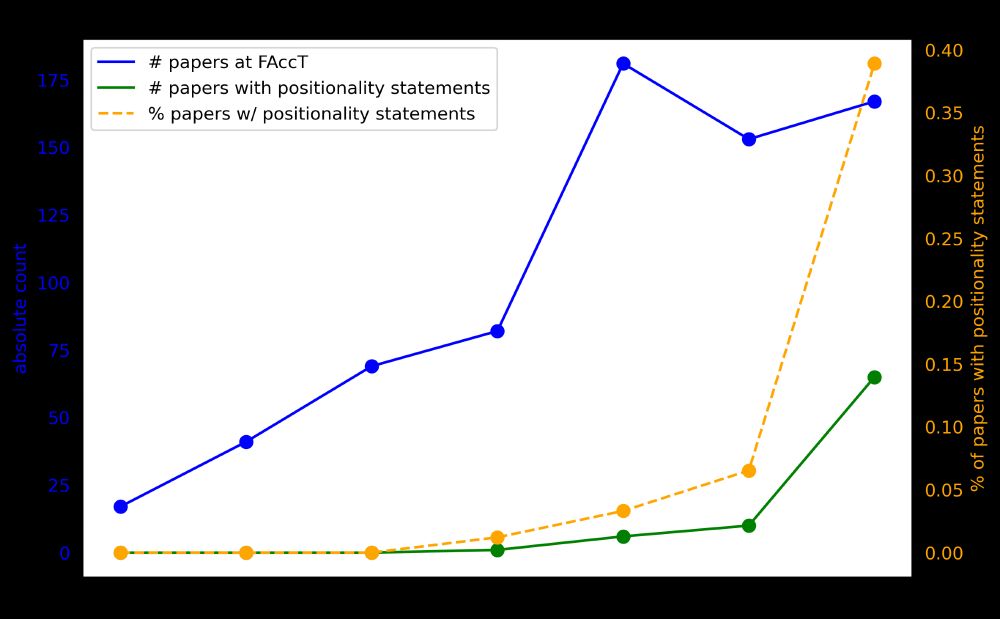
We reviewed papers from the entire history of FAccT for the presence of positionality statements. We find 2024 marked a significant proportional increase in papers that included positionality statements, likely as a result of PC recommendations:
24.06.2025 14:48 — 👍 0 🔁 0 💬 1 📌 0
With ongoing reflection on the impact of computing on society, and the role of researchers in shaping impacts, positionality statements have become more common in computing venues, but little is known about their contents or the impact of conference policy on their presence.
24.06.2025 14:46 — 👍 1 🔁 0 💬 1 📌 0
1) Thrilled to be at #FAccT for the first time this week, representing a meta-research paper on positionality statements at FAccT from 2018-2024, in collaboration with @s010n.bsky.social and Akshansh Pareek, "Disclosure without Engagement: An Empirical Review of Positionality Statements at FAccT"
24.06.2025 14:46 — 👍 10 🔁 1 💬 1 📌 0
Democracy needs you! Super excited to be co-organizing this NLP for Democracy workshop at #COLM2025 with a wonderful group. Abstracts due June 19th!
06.06.2025 15:59 — 👍 8 🔁 2 💬 0 📌 0
a whole cluster of postdocs and phd positions in Tartu in Digital Humanities / Computational Social Science / AI under the umbrella of big European projects.
consider sharing please!
07.05.2025 11:17 — 👍 35 🔁 42 💬 0 📌 0
📣🧪
$25k grants for those who:
1. are working on research on STEM and education (including AI and CS, graduate education and MSIs, and scholarship that aims to reduce inequality), and
2. have had a recently terminated or cancelled grant from NSF.
Early-career scholars prioritized
03.05.2025 17:56 — 👍 112 🔁 80 💬 2 📌 2
Last poster session starting now in Pacifico North! Come say hi 👋
29.04.2025 06:30 — 👍 0 🔁 0 💬 0 📌 0
phding@mcgill, writer/editor@reboot, translator@limited connection collective
shiraab.github.io
Books in translation:
https://asterismbooks.com/product/the-hand-of-the-hand-laura-vazquez
https://www.arche-editeur.com/livre/le-reve-dun-langage-commun-747
PhDing @ MILA/McGill in Computer Science | Multi-agent systems, emergent organization, and neurosymbolic methods
Previously @ UWaterloo
Also love guitar/bass, volleyball, history, cycling, and institutional design
2nd year PhD student studying human-centered AI at the University of Minnesota.
Website: https://malikkhadar.github.io/
Assistant professor of political science at MSU. NLP, text, and conflict.
PhD student @uwnlp.bsky.social @uwcse.bsky.social | visiting researcher @MetaAI | previously @jhuclsp.bsky.social
https://stellalisy.com
Associate Professor of Human-Centered Computing and Social Informatics at Penn State. AI and sociotechnical NLP, especially for privacy and fairness. Also posting about academia, photography, and travel. Opinions mine. he/him. http://shomir.net
Assistant Prof. in Org. Behavior @StanfordGSB | Computational Culture Lab http://comp-culture.org | Social Networks, Cognition, Cultural Evolution, AI
Associate Professor | Department of Network and Data Science @ceu-dnds.bsky.social | Central European University @weareceu.bsky.social | https://elisaomodei.weebly.com/
using computational methods to understand the linguistic mechanisms of social problems | NLP, socioling, discourse-pragmatics | asst prof at UC Davis Linguistics
https://robvoigt.faculty.ucdavis.edu/
I do research in social computing and LLMs at Northwestern with @robvoigt.bsky.social and Kaize Ding.
Computational Social Science / Human-Computer Interaction @Saarland University. Oxford OII & Sarah Lawrence alum.
Unofficial bot by @vele.bsky.social w/ http://github.com/so-okada/bXiv https://arxiv.org/list/cs.CY/new
List https://bsky.app/profile/vele.bsky.social/lists/3lim7ccweqo2j
ModList https://bsky.app/profile/vele.bsky.social/lists/3lim3qnexsw2g
great value chidi anagonye. more seriously Societal Computing PhD student at Carnegie Mellon University. not just an ML account.
AI PhDing at Mila/McGill (prev FAIR intern). Happily residing in Montreal 🥯❄️
Academic: language grounding, vision+language, interp, rigorous & creative evals, cogsci
Other: many sports, urban explorations, puzzles/quizzes
bennokrojer.com
Computer Science PhD student at Bielefeld University -
NLProc and Computational Social Science -
Disagreement, Human Label Variation, Perspectives -
Website: https://orlikow.ski
Historian of early modern health, religion, & emotions | Critical AI studies & historiography
Postdoc at C²DH, University of Luxembourg
I focus on data learnability, model representation and uncertainty for subjective NLP tasks
PhDing on Interpretable NLP + CSS @gesis.org Prev: Masters Student + Researcher at @ubuffalo.bsky.social and Sr. Data Scientist at Coursera
Computational social scientist researching human-AI interaction and machine learning, particularly the rise of digital minds. Visiting scholar at Stanford, co-founder of Sentience Institute, and PhD candidate at University of Chicago. jacyanthis.com
The 11th International Conference on Computational Social Science (IC2S2) will be held in Norrköping, Sweden, July 21-24, 2025.
Website: https://www.ic2s2-2025.org/
Asst Prof @ University of Washington Information School // PhD in English from WashU in St. Louis
I’m interested in books, data, social media, and digital humanities.
They call me "Eyre Jordan" on the bball court 🏀
https://melaniewalsh.org/























