Very strong results on SSv2 and action anticipation, plus zero-shot robotics planning! And we also attached an LLM to the vision encoder and got strong numbers on PerceptionTest!
Check out the blog post (with link to paper and GitHub) above!
11.06.2025 21:43 — 👍 0 🔁 0 💬 0 📌 0
Very excited to share V-JEPA 2! I've been working on the encoder pretraining pipeline and data curation for this model the last few months, and am excited for it to finally be out!
ai.meta.com/blog/v-jepa-...
11.06.2025 21:43 — 👍 2 🔁 0 💬 1 📌 0
Qinco2 builds on Qinco with several optimizations, including beam search (increases accuracy+compute) and pre-selection (decreases compute). On the balance this leads to a more efficient method for similarity search.
07.01.2025 14:46 — 👍 0 🔁 0 💬 1 📌 0
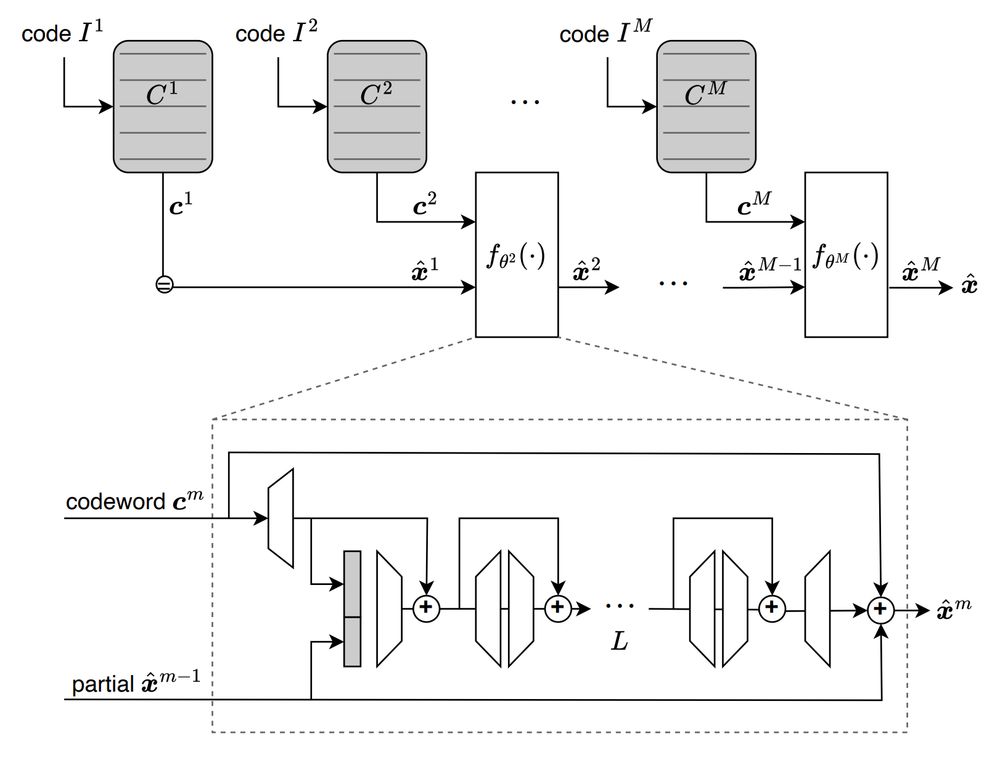
The Qinco2 architecture builds on our previous Qinco work, which uses a neural network to implicitly parametrize code books for residual quantization. At each quantization step, a neural network is used in conjunction with the current vector to predict the next update.
07.01.2025 14:46 — 👍 0 🔁 0 💬 1 📌 0

Qinco2: Vector Compression and Search with Improved Implicit Neural Codebooks
Vector quantization is a fundamental technique for compression and large-scale nearest neighbor search. For high-accuracy operating points, multi-codebook quantization associates data vectors with one...
We just published "Qinco2: Vector Compression and Search with Improved Implicit Neural Codebooks" on arXiv, work led by our talented intern, Theophane Vallaeys.
Qinco2 achieves as much as 40-60% reduction error for vector compression, as well as better performance for approximate similarity search.
07.01.2025 14:46 — 👍 2 🔁 0 💬 1 📌 0
Yes exactly.
Depending on how much you mutate it, keeping such libraries can also be very useful for reproducibility (which I didn't mention above).
14.12.2024 17:44 — 👍 1 🔁 0 💬 0 📌 0
But this can be difficult for other people that are trying to do something that doesn't fit in your framework (which happens often in research). There's always one or two things that simply don't fit. As a result, I'm finding myself writing more hacky/prototyping code these days.
13.12.2024 15:26 — 👍 2 🔁 0 💬 1 📌 0
GitHub - facebookresearch/NeuralCompression: A collection of tools for neural compression enthusiasts.
A collection of tools for neural compression enthusiasts. - facebookresearch/NeuralCompression
In my PhD much of my code was hacky, and I think this set me back quite a bit. At some point I overcorrected towards building complex frameworks for my work, which let me try a lot of things (so long as I stayed within my own framework). This is more or less what you see in NeuralCompression.
13.12.2024 15:26 — 👍 5 🔁 0 💬 1 📌 0
One thing I've found in research is the constant counterbalancing between "prototype" code and "engineered" code.
Prototyped code is often a bit hacky, but gets the job done. But if you ever need to extend it, it can be quite a pain.
Engineered code usually has some overarching design philosophy
13.12.2024 15:26 — 👍 8 🔁 1 💬 2 📌 0
Is there a particular reason this is considered an anti pattern? I'm actually curious.
04.12.2024 17:12 — 👍 0 🔁 0 💬 1 📌 0
Release v1.5.2 Fix required numpy version · mmuckley/torchkbnufft
What's Changed
Update required numpy by @mmuckley in #103
Full Changelog: v1.5.1...v1.5.2
For MRI folks: we just rolled out a new release to torchkbnufft, first in a couple years.
The changes are for working with newer package versions. Things now work on numpy 2.0, and a few deprecations are fixed. Other than that, it's the same as before :). Get it with
`pip install torchkbnufft`
04.12.2024 15:26 — 👍 6 🔁 0 💬 0 📌 1
I actually think there was quite a bit of spam here a month or two ago and it's already gotten better. Not sure if that's due to an effort on the part of the site admins or just basic engagement numbers shifting what gets into a feed.
24.11.2024 21:53 — 👍 1 🔁 0 💬 0 📌 0
Good thoughts, some of which I've learned from trial and error over the years.
The advice part, centering things on technical points, is also useful for academic publishing and the review process. It really helps defuse what tends to be an adversarial relationship with reviewers (or authors).
23.11.2024 15:46 — 👍 3 🔁 0 💬 0 📌 0
📣 I am sure we have reached only a small fraction of New York's ML community in bsky. Please repost 🔁 this if you think you may have interested people close to you in the social graph.
22.11.2024 14:14 — 👍 21 🔁 7 💬 2 📌 1
Please make machine learners who still are children.
20.11.2024 13:56 — 👍 1 🔁 0 💬 0 📌 0
👋
19.11.2024 19:52 — 👍 2 🔁 0 💬 1 📌 0
I'm here!
19.11.2024 17:33 — 👍 0 🔁 0 💬 1 📌 0
Kinda has the y2k gaming energy (but without the CRT monitor)
19.11.2024 13:27 — 👍 1 🔁 0 💬 0 📌 0
HELLO Hello hello hellooo...
18.11.2024 16:01 — 👍 7 🔁 0 💬 2 📌 0
Research scientist @nvidia | postdoc @caltech | PhD @univienna | former research intern @MetaAI and @nvidia | views are my own
I help others create amazing technology. responsiveX founder. Azure and AI MVP. Microsoft Regional Director. Azure SQL DB book author. Guitar player. Husband. Dad.
Electrical Engineer | Biomedical Imaging Postdoc CBI NYU | NIBIB K99 Awardee | PhD '20 | Alumni RLE at MIT '19 | MEng AUTh '16 | ISMRM Junior Fellow '25 | IEEE Senior Member '25
Research Scientist at Google DeepMind | Building Gemini
guabhinav.com
Assistant professor, Electrical and Computer Engineering & Biomedical Engineering Depts, Technion.
MRI, machine learning, computational imaging, AI bias. Open code.
PhD @Meta & @ENSParis. Diffusion Models, Flow Matching, High-Dimensional Statistics.
Transactions on Machine Learning Research (TMLR) is a new venue for dissemination of machine learning research
https://jmlr.org/tmlr/
A National Center for Biomedical Imaging & Bioengineering operated by NYU Grossman School of Medicine @ NYU Langone Health, supported by the National Institute of Biomedical Imaging & Bioengineering @ the National Institutes of Health • https://cai2r.net
NeuroAI, vision, open science. NeuroAI researcher at Amaranth Foundation. Previously engineer @ Google, Meta, Mila. Updates from http://neuroai.science
Assistant Professor @ Stony Brook AMS & CS
https://chenyuyou.me/
MRI and parallel transmission enthusiast. California --> Illinois --> Michigan --> Scotland-->Spain.
Developer on PyTorch at Meta. Previously Haskeller and GHC developer.
The nonprofit organization behind the Python programming language. For help with Python code: http://python.org/about/help/
On Mastodon: @ThePSF@fosstodon.org
Official account for the IEEE/CVF International Conference on Computer Vision. #ICCV2025 Honolulu 🇺🇸 Co-hosted by @natanielruiz @antoninofurnari @yaelvinker @CSProfKGD
Official account for IEEE/CVF Conference on Computer Vision & Pattern Recognition. Hosted by @CSProfKGD with more to come.
📍🌎 🔗 cvpr.thecvf.com 🎂 June 19, 1983
Marrying classical CV and Deep Learning. I do things, which work, rather than being novel, but not working.
http://dmytro.ai
Director Data Science Institute @UWMadison, Professor of Physics,
EiC @MLSTjournal. Physics, stats/ML/AI, open science.
Sr. Principal Research Manager at Microsoft Research, NYC // Machine Learning, Responsible AI, Transparency, Intelligibility, Human-AI Interaction // WiML Co-founder // Former NeurIPS & current FAccT Program Co-chair // Brooklyn, NY // http://jennwv.com




















