Hello Athens! 👋☀️
Excited to be attending #FAccT 2025 and presenting our paper “From Lived Experience to Insight” on 24th June at 10:45 AM (New Stage C)
dl.acm.org/doi/10.1145/...
Would love to catch up with old friends and make new ones and talk about AI and mental health 😄
23.06.2025 21:01 — 👍 4 🔁 0 💬 0 📌 0
Congratulations! 🙌
30.05.2025 16:35 — 👍 1 🔁 0 💬 1 📌 0
For more details:
Paper: shorturl.at/bldCb
Webpage: shorturl.at/bC1zn
Code: shorturl.at/H8xmp
Grateful for the efforts from my co-authors 🙌: Siddharth Sriraman, @verma22gaurav.bsky.social, Harneet Singh Khanuja, Jose Suarez Campayo, Zihang Li, Michael L. Birnbaum, Munmun De Choudhury
11/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 0 📌 0
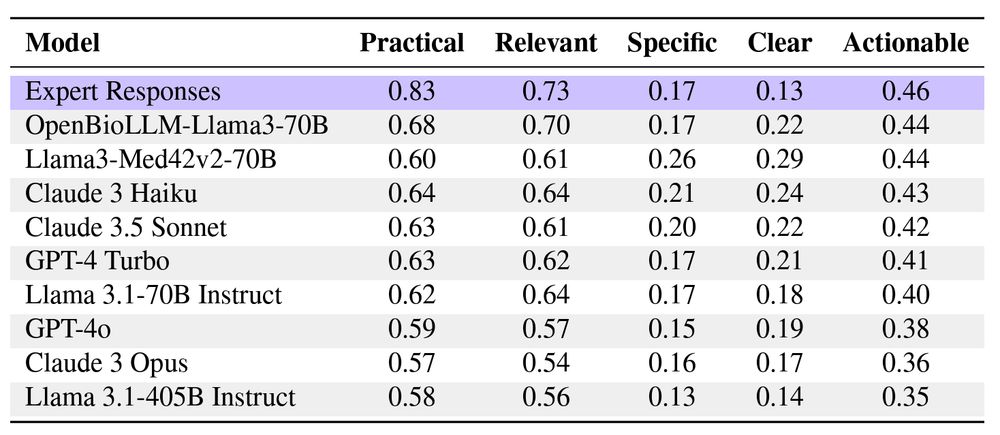
Table 3: Mean actionability alignment scores of harm reduction strategies (last column),computed as average of practicality, relevance, specificity, and clarity scores.
Finding #6: We examined the actionability of mitigation advices. Expert responses scored the highest on overall actionability in comparison to all the LLMs.
While LLMs provide less practical and relevant advice, their advice is more clear and specific.
10/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0

Table 2: Alignment of harm reduction strategies of various models with the expert’s response.We report the mean and standard deviation for the AlignScore metric GPT-4o score, with the best (bold) and second-best (underline) performing model in each metric highlighted.
Finding #5: LLMs struggle to provide expert-aligned harm reduction strategies with larger models producing less expert-aligned strategies than smaller ones.
The best medical model aligned with experts ~71% (GPT-4o score) of the time.
9/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
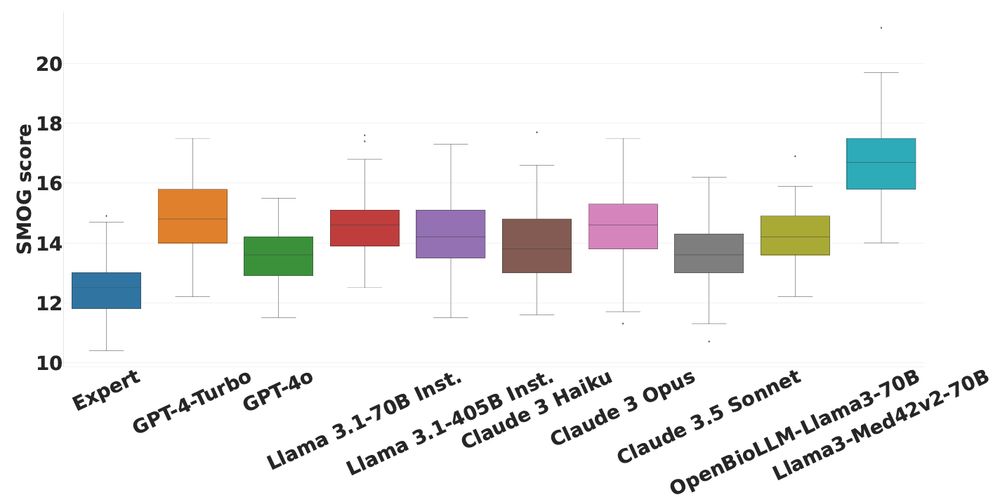
Mean SMOG Scores (for readability) and 95% Confidence Intervals for Various Models (lower values are better).
Using the ADRA framework, we evaluate LLM alignment with experts across expressed emotion, readability, harm reduction strategies, & actionable advice.
Finding #4: We find that LLMs express similar emotions and tones but provide significantly harder to read responses.
8/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
Finding #3: In-context learning boosted performance for both ADR detection and multiclass classification (+23 F1 points for the latter). However, gains in ADR detection task were limited to a few models.
Type of examples had a more pronounced impact for the ADR multiclass class. task.
7/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
Finding #2: All LLMs showed “risk-averse” behavior, labeling no-ADR posts as ADR. Claude 3 Opus had a 42% false-positive rate for ADR detection and GPT-4-Turbo misclassified over 50% non-dose/time-related ADRs.
This highlights the lack of "lived-experience" among models.
6/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
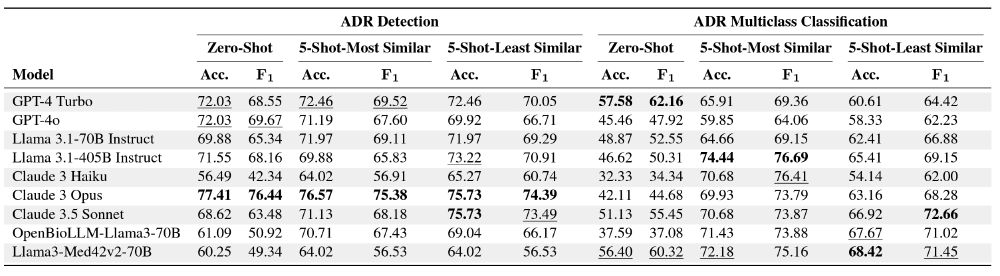
Table 1: Performance of different models on Binary Detection and Multiclass Classification tasks under Zero-Shot and 5-Shot scenarios.W e report the accuracy score(Acc.) and weighted F1 score as(F1) with the best and second-best performing model metrics in each scenario highlighted in bold and underline, respectively.
Finding #1: Larger models perform better for ADR detection tasks (Claude3 Opus led with an accuracy score of 77.41%), but this trend does not hold for ADR multiclass classification. Additionally, distinguishing ADR types remains a significant challenge for all models.
5/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
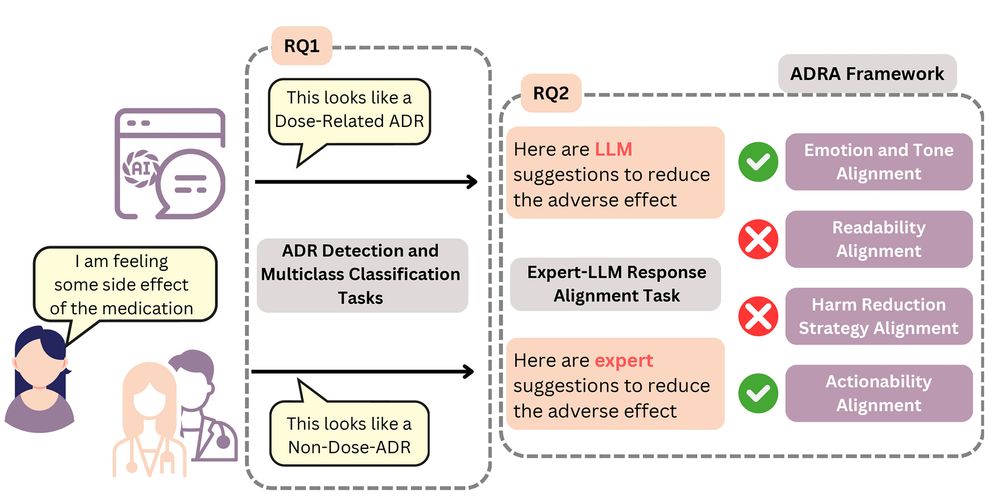
Figure 1: Overview of work; we present two tasks in this work– ADR detection and multiclass classification (RQ1), and Expert-LLM response alignment (RQ2).
We introduce the Psych-ADR, a benchmark with Reddit posts annotated for ADR presence/type, paired with expert-written responses and the ADRA framework to systematically evaluate long-form generations in detecting ADR expressions and delivering mitigation strategies.
4/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
Broader Takeaway #2: To build reliable AI in healthcare, we must move beyond choice-based benchmarks toward tasks that portray the complexities of the real world (such as ADR mitigation) using nuanced frameworks and benchmarks. 📈
Below are some nuanced findings 👇
3/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
Broader Takeaway #1: LLMs are tools to empower and not replace mental health professionals. They offer clear & specific advice, addressing the global shortage of care providers—but contextually relevant, practical advice still requires human expertise. 👨⚕️👩⚕️
2/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0

(Left) Screenshot of the paper title and author information. (Right) An image with a Llama and human doctor examining a patient for adverse drug reaction. The Llama doctor suspects that the patient is suffering from ADR, whereas human doctor suspects that it is not an ADR.
Adverse Drug Reactions are among the leading causes of hospitalizations for mental health issues. With existing limitations, LLMs have the potential to detect ADRs and provide mitigation strategies.
But do LLMs align with experts? 🤔 We explore this in our work 👇🏼🧵
shorturl.at/bldCb
1/11
07.01.2025 21:38 — 👍 0 🔁 0 💬 1 📌 0
This is so far our best call for papers! We completely re-thought what a CFP is, and.... mostly copied last year's while surgically increasing some numbers
17.12.2024 15:55 — 👍 15 🔁 2 💬 3 📌 0
Great work! 👏
13.12.2024 01:13 — 👍 1 🔁 0 💬 0 📌 0
This semester in a nutshell:
Write Paper -> Write Rebuttal -> Repeat
Also writing rebuttals is significantly more tiring than writing papers.
03.12.2024 20:16 — 👍 2 🔁 0 💬 0 📌 0
Yup! I joined recently along with a large number of folks and I guess it will become like academic twitter if people continue to engage on the platform.
25.11.2024 23:35 — 👍 1 🔁 0 💬 0 📌 0
Really amazing work! very insightful
25.11.2024 23:34 — 👍 10 🔁 0 💬 0 📌 0
I'm loving my Bluesky feed. It feels quite similar to what my timeline used to look before the Twitter buyout.
I hope more people switch to this platform and make academic discussions mainstream again!
#AcademicSky
25.11.2024 23:30 — 👍 6 🔁 0 💬 1 📌 0
Thank you so much!
25.11.2024 18:16 — 👍 1 🔁 0 💬 0 📌 0
I would love to get added if possible!
25.11.2024 08:00 — 👍 0 🔁 0 💬 1 📌 0
Congratulations!
It is certainly a good start but I still feel we need more interdisciplinary reviewers (based on the reviews I have gotten). One issue is the ask for reviewers to have at least 3 *CL papers in past 5 years which many researchers might not have.
Something ACs could look into ?
24.11.2024 05:43 — 👍 1 🔁 0 💬 1 📌 0
Thank you!
22.11.2024 21:14 — 👍 1 🔁 0 💬 0 📌 0
Would love to get added to this!
22.11.2024 20:41 — 👍 0 🔁 0 💬 1 📌 0
Studying NLP, CSS, and Human-AI interaction. PhD student @MIT. Previously at Microsoft FATE + CSS, Oxford Internet Institute, Stanford Symbolic Systems
hopeschroeder.com
PhD Student @cs.ubc.ca | Video Reasoning and Generation |📍Vancouver, BC
🔗 adityachinchure.com
A nonprofit dedicated to advancing scientific psychology across disciplinary and geographic borders.
psychologicalscience.org
Jobs: jobs.psychologicalscience.org
Membership: psychologicalscience.org/members
#APSGlobal: APS Global Summit
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
PhD @UBC_CS | @VectorInst I @UBC_NLP | Prev @MetaAI @MSFTResearch @Open_ML
🌐 http://sahithyaravi.github.io
4th year PhD student in UMD CS advised by Philip Resnik. I have also been a research intern at MSR (2024) and Adobe Research (2022).
ACM Conference on Fairness, Accountability, and Transparency (ACM FAccT). June 2026 in Montreal, Canada 🇨🇦 #FAccT2026
https://facctconference.org/
Responsible AI & Human-AI Interaction
Currently: Research Scientist at Apple
Previously: Princeton CS PhD, Yale S&DS BSc, MSR FATE & TTIC Intern
https://sunniesuhyoung.github.io/
Incoming PhD student @Princeton CS, Currently ugrad @KAIST CS, Prev NAVER AI Lab, Georgia Tech
inhwasong.com
Incoming Assistant Professor @cornellbowers.bsky.social
Researcher @togetherai.bsky.social
Previously @stanfordnlp.bsky.social @ai2.bsky.social @msftresearch.bsky.social
https://katezhou.github.io/
PhD Student at Carnegie Mellon University.
HCI + Mental Health.
PhD student at IIIT Delhi | #NLProc #AIforHealthcare #socialcomputing
Researcher studying social media + AI + mental health. Faculty of Interactive Computing at Georgia Tech. she/her
Researching fear as a tool in online public discourse. Side hustle: Making sure that Language Models gets scared too (detecting it).
PhDing @gesis.org • Computational Social Science • NLProc
https://s-vigneshwaran.github.io
Doctor of NLP/Vision+Language from UCSB
Evals, metrics, multilinguality, multiculturality, multimodality, and (dabbling in) reasoning
https://saxon.me/
Associate Professor at UMSI, UMICHCS, and UMICHCSE working on Computational Social Science, Network Science, Science of Science, Complex Systems, and Social Media. 🇨🇴🇺🇸 dromero.org
Chief Scientific Officer of Microsoft.
Senior Research Scientist @ IBM Research, Human-Centered AI