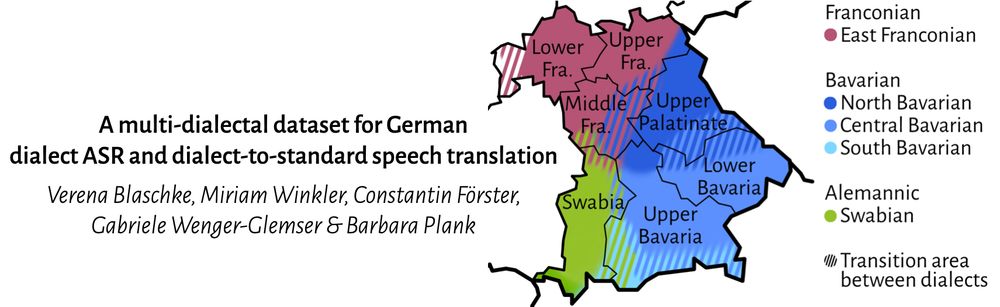
Piper title ("A multi-dialectal dataset for German dialect ASR and dialect-to-standard speech translation") and a map of the German state Bavaria showing where the Franconian, Bavarian, and Alemannic dialect groups are spoken
At #Interspeech2025 I'm going to present Betthupferl, a dataset for German dialect ASR & dialect-to-standard speech translation! We analyze differences between dialectal & Standard German transcriptions, benchmark ASR models, and examine shortcomings of current ASR models & evaluation metrics.
07.08.2025 08:46 — 👍 16 🔁 4 💬 1 📌 1

I’ll be at @icmlconf.bsky.social next week presenting NoLiMa!
Poster on Tue July 15, 4:30–7pm (E-2312).
Happy to grab a coffee and chat about long-context, memory, research, or just to catch up.
I’ll be in Toronto for a couple of days after the conference, let me know if you’re around!
09.07.2025 13:53 — 👍 4 🔁 2 💬 1 📌 0

New paper: How does pretraining on programming languages + English shape LLMs' concept space?
🔍 Do LLMs use English or a programming language as a kind of pivot language?
🧠 Are neurons language-specific or shared across programming languages and English?
🔗 arxiv.org/abs/2506.01074
03.06.2025 17:22 — 👍 6 🔁 1 💬 1 📌 0
📄 Collapse of Dense Retrievers
Accepted to #ACL2025 main conference 🎉🎉
In this paper we uncover major vulnerabilities in dense retrievers like Contriever, showing they favor:
📌 Shorter docs
📌 Early positions
📌 Repeated entities
📌 Literal matches
...all while ignoring the answer's presence!
17.05.2025 20:28 — 👍 9 🔁 2 💬 1 📌 1
🗨️ Beyond “noisy” text: How (and why) to process dialect data
🔎 Keynote talk at WNUT @ NAACL
👥 @verenablaschke.bsky.social
📁 Workshop on noisy and user-generated text (May 3)
The full workshop programme is here: noisy-text.github.io/2025/
bsky.app/profile/vere...
29.04.2025 15:03 — 👍 2 🔁 1 💬 0 📌 0
📝 Privacy-Preserving Federated Learning for Hate Speech Detection
🔎 We present a federated learning system with differential privacy and fine-tuned ALBERT models for low-resource hate speech detection.
👥 Ivo Júnior, @htyeh1, Axel Wisiorek, @HinrichSchuetze
📁 SRW - Long
29.04.2025 15:03 — 👍 1 🔁 0 💬 1 📌 0
📝 Linguistic Features in German BERT: The Role of Morphology, Syntax, and Semantics in Multi-Class Text Classification
🔎 Analysis of linguistic features used by German BERT in a classification task.
👥 Henrike Beyer (University of Dundee), Diego Frassinelli
📁 SRW - Short
29.04.2025 15:03 — 👍 0 🔁 0 💬 1 📌 0

🥳 We are happy to share that CIS will be presenting 6 papers and talks at #NAACL2025!
Find out about each of them below in the 🧵
29.04.2025 15:03 — 👍 10 🔁 0 💬 1 📌 1
On my way to #NAACL2025 where I'll give a keynote at the noisy text workshop (WNUT), presenting some of the challenges & methods for dialect NLP + also discussing dialect speakers' perspectives!
🗨️ Beyond “noisy” text: How (and why) to process dialect data
🗓️ Saturday, May 3, 9:30–10:30
29.04.2025 09:17 — 👍 27 🔁 7 💬 1 📌 1
PhD student in NLP @MaiNLPlab, @CIS, @LMU
#nlp @ Sorbonne Université & CNRS - https://fyvo.github.io
Assistant Professor at @cs.ubc.ca and @vectorinstitute.ai working on Natural Language Processing. Book: https://lostinautomatictranslation.com/
The Official Bluesky Account of the Department of Language Science and Technology @uni-saarland.de
Imprint: https://www.uni-saarland.de/en/department/lst/about-us/contact.html
Homepage: https://www.lst.uni-saarland.de/
The largest workshop on analysing and interpreting neural networks for NLP.
BlackboxNLP will be held at EMNLP 2025 in Suzhou, China
blackboxnlp.github.io
Researchers on natural language processing / computational linguistics in the beautiful city of Augsburg, Germany (near Munich). Find out more about us on https://hlt-augsburg.github.io.
PhD student, NLP Researcher at @cislmu.bsky.social | Prev. Intern @Adobe.com
PhD student @ TU Munich, Human-centered AI, Computational Social Science
https://sxu3.github.io/
PhD student @ LMU Munich
I like dialects 🗺️
#NLProc research group @itu.dk (Copenhagen, Denmark)
🔗 nlpnorth.github.io
ELLIS PhD student in NLP @MaiNLPlab, @CisLmu, @LMU_Muenchen
https://mckysse.github.io/
Postdoc — University of Copenhagen
#NLPxEducation #NLPxHR #NLP
Past:
🇩🇰 Aalborg University
🇩🇰 IT University of Copenhagen
🇨🇭 EPFL
🇸🇬 National University of Singapore
🇩🇪 NEC
🇳🇱 University of Groningen
🌐 https://jjzha.github.io/
Research scientist @ sme.do working on ML for remote vital sign sensing. Human-centric and biomedical NLP in my academic past📍Nuremberg. 🖥️ https://leonweber.me
Postdoc in NLP @milanlp.bsky.social (Milan) and @nlpnorth.bsky.social (Copenhagen) | affiliated @aicentre.dk | past @mainlp.bsky.social, Amazon Alexa
🔗 elisabassignana.github.io
Postdoc AI Researcher (NLP) @ ITU Copenhagen
🧭 https://mxij.me
PhD student @MaiNLP (Munich AI & NLP lab), @LMU.
Working on reasoning in large language models.
ELLIS PhD Student at MaiNLP
@ellis.eu @mainlp.bsky.social @munichcenterml.bsky.social
Semi-serious runner for Berlin Track Club and my sanity
PhD student @mainlp.bsky.social (@cislmu.bsky.social, LMU Munich). Interested in language variation & change, currently working on NLP for dialects and low-resource languages.
verenablaschke.github.io
Research Intern @Apple MLR • PhD Student @Uni Vienna • prev: @CisLMU, alumna @DAAD_Germany
#NLProc
🏫 asst. prof. of compling at university of pittsburgh
past:
🛎️ postdoc @mainlp.bsky.social, LMU Munich
🤠 PhD in CompLing from Georgetown
🕺🏻 x2 intern @Spotify @SpotifyResearch
https://janetlauyeung.github.io/





















