
First draft online version of The RLHF Book is DONE. Recently I've been creating the advanced discussion chapters on everything from Constitutional AI to evaluation and character training, but I also sneak in consistent improvements to the RL specific chapter.
rlhfbook.com
16.04.2025 19:01 — 👍 110 🔁 17 💬 3 📌 3


At ICLR 2025 in Singapore, my co-authors and I presented two papers on RL. Feel free to let us know of any feedback and let me know if you'd like to chat!
- openreview.net/forum?id=AOl...
- openreview.net/forum?id=AOl...
26.04.2025 01:51 — 👍 1 🔁 0 💬 0 📌 0

Postdoctoral Researcher, Monetization (PhD)
Meta's mission is to build the future of human connection and the technology that makes it possible.
Topics of interest include offline RL, post-training large language models with RLHF, and long-term recommendation systems. If you’re interested, please email me and/or apply here: www.metacareers.com/jobs/1142270...
17.03.2025 13:59 — 👍 2 🔁 0 💬 0 📌 0
Our team at Meta is hiring a postdoc researcher! Our group conducts both fundamental and applied research in reinforcement learning, with a focus on applications in Meta's advertising systems.
17.03.2025 13:59 — 👍 3 🔁 1 💬 1 📌 0

ASOS Digital Experiments Dataset
A novel dataset that can support the end-to-end design and running of Online Controlled Experiments (OCE) with adaptive stopping.
Hosted on the Open Science Framework
There’s one from ASOS.com that provides A/B test data over time (across many experiments, each with several arms).
Dataset: osf.io/64jsb/
Paper: arxiv.org/abs/2111.10198
We used it in a paper to benchmark an AE method. But I’d also love to know of other alternatives out there.
21.02.2025 05:27 — 👍 8 🔁 0 💬 1 📌 0


Given a high-quality verifier, language model accuracy can be improved by scaling inference-time compute (e.g., w/ repeated sampling). When can we expect similar gains without an external verifier?
New paper: Self-Improvement in Language Models: The Sharpening Mechanism
arxiv.org/abs/2412.01951
14.12.2024 16:10 — 👍 41 🔁 6 💬 3 📌 0

Reinforcement Learning: An Overview
This manuscript gives a big-picture, up-to-date overview of the field of (deep) reinforcement learning and sequential decision making, covering value-based RL, policy-gradient methods, model-based met...
An updated intro to reinforcement learning by Kevin Murphy: arxiv.org/abs/2412.05265! Like their books, it covers a lot and is quite up to date with modern approaches. It also is pretty unique in coverage, I don't think a lot of this is synthesized anywhere else yet
09.12.2024 14:27 — 👍 270 🔁 73 💬 9 📌 5
I know one of the organizers is @eugenevinitsky.bsky.social. They did a great job and organized a very enjoyable conference.
10.12.2024 08:18 — 👍 1 🔁 0 💬 1 📌 0
I collected some folk knowledge for RL and stuck them in my lecture slides a couple weeks back: web.mit.edu/6.7920/www/l... See Appendix B... sorry, I know, appendix of a lecture slide deck is not the best for discovery. Suggestions very welcome.
27.11.2024 13:36 — 👍 113 🔁 17 💬 3 📌 3
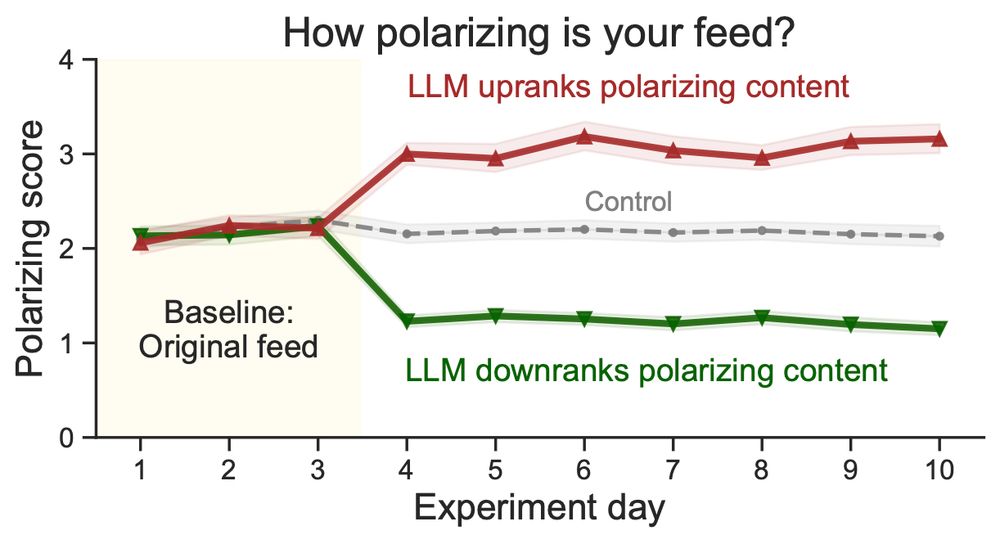
New paper: Do social media algorithms shape affective polarization?
We ran a field experiment on X/Twitter (N=1,256) using LLMs to rerank content in real-time, adjusting exposure to polarizing posts. Result: Algorithmic ranking impacts feelings toward the political outgroup! 🧵⬇️
25.11.2024 20:32 — 👍 815 🔁 216 💬 32 📌 52
The RL (and some non-RL folks) starter pack is almost full. Pretty clear that the academic move here has succeeded
go.bsky.app/3WPHcHg
18.11.2024 20:30 — 👍 104 🔁 32 💬 12 📌 3
A business analyst at heart who enjoys delving into AI, ML, data engineering, data science, data analytics, and modeling. My views are my own.
You can also find me at threads: @sung.kim.mw
Chief Models Officer @ Stealth Startup; Inria & MVA - Ex: Llama @AIatMeta & Gemini and BYOL @GoogleDeepMind
Professor of Psychology at NYU (jayvanbavel.com) | Author of The Power of Us Book (powerofus.online) | Director of NYU Center for Conflict & Cooperation | trying to write a new book about collective decisions
U.S. Senator, Massachusetts. She/her/hers. Official Senate account.
https://substack.com/@senatorwarren
Assistant Prof at Georgia Tech ISyE | healthcare operations research
Assistant Professor in Industrial and Manufacturing Engineering at FAMU-FSU College of Engineering. Interested in modeling, creating, & analyzing better systems involving SUD & criminal justice.
vmwhite.github.io
Smarter Decisions For a Better World.
Supporting all professionals who advance and apply science, AI, math, technology, and analytics to transform our world.
www.informs.org
The OR Society is a professional membership body to support the development of people working in operational research, data and analytics. https://www.theorsociety.com/
#OperationalResearch #ThisIsOR #ORMS
Professor at Carnegie Mellon University. Energy Affordability. Energy & Climate Justice. Climate Adaptation. Systems Modeling. CEO - Peoples Energy Analytics. Named a 2024 Science Defender
Clemson IE AP | past: @NorthwesternU @OhioState #datadriven stochastic optimizer in theory and practice
PhD at Machine Learning Department, Carnegie Mellon University | Interactive Decision Making | https://yudasong.github.io
PhD student | Interested in all things decision-making and learning
Visiting Researcher at Meta; PhD student @mila.quebec. Ex: Intern @GoogleDeepMind, Intern @ EPFL, MSc@MIPT;
artemzholus.github.io
PhD Student in Tübingen (MPI-IS & Uni Tü), interested in reinforcement learning. Freedom is a pure idea. https://onnoeberhard.com/
PhD student at UC Berkeley studying RL and AI safety.
https://cassidylaidlaw.com
CS PhD candidate @UCLA | Prev. Research Intern @MSFTResearch, Applied Scientist Intern @AWS | LLM post-training, multi-modal learning
https://yihedeng9.github.io
PhD student at Mila | Diffusion models and reinforcement learning 🧐 | hyperpotatoneo.github.io
Fine-tuning LLMs @Cohere | PhD Candidate on RL @VUB
Ph.D. Student studying AI & decision making at Mila / McGill University. Currently at FAIR @ Meta. Previously Google DeepMind & Google Brain.
https://brosa.ca
























