Maybe. But both should just converge to the true posterior with infinite pretraining scale.
24.02.2026 22:16 —
👍 1
🔁 0
💬 0
📌 0
I tried 512 and 999 in small-scale experiments and there didn't seem to be a significant difference. I don't think a smaller choice would be better for small datasets, since we have a lot of small datasets in pretraining. But you never know...
24.02.2026 20:55 —
👍 1
🔁 0
💬 1
📌 0
To piggy-back a bit on foundation models for structured data discussion here
My colleagues at Yandex Research just updated the GraphPFN paper. It's a Graph Foundation Model that works on graph datasets with tabular features, and shows SOTA results both in ICL regimes and when fine-tuned.
13.02.2026 15:31 —
👍 2
🔁 2
💬 1
📌 0
Super hyped that it's finally out!
12.02.2026 14:05 —
👍 16
🔁 1
💬 2
📌 0

2025 highlights: AI research and code
AI is everywhere. Can you see it here? Note Some highlights about my work in 2025: progress on tabular-learning stands out, a publication on unpacking trade-off and consequences of scale in...
My 2025 highlights for AI research and code:
▪ Unpacking the AI scale narrative
▪ Tabular-learning research
- TabICL: table foundation model
- Retrieve merge predict: data lakes
▪ Better software
- Skrub: machine learning with tables
- Fundamentals in scikit-learn
gael-varoquaux.info/science/2025...
02.01.2026 13:45 —
👍 22
🔁 5
💬 0
📌 0
Sacha Braun, David Holzm\"uller, Michael I. Jordan, Francis Bach
Conditional Coverage Diagnostics for Conformal Prediction
https://arxiv.org/abs/2512.11779
15.12.2025 05:08 —
👍 3
🔁 1
💬 0
📌 0
LinkedIn
This link will take you to a page that’s not on LinkedIn
Let's kick off 2026 with a workshop on Survival Analysis and Foundation Models, co-organized w. Julie Alberge Linus Bleistein Clément Berenfeld Agathe Guilloux and Julie Josse on January 27th at PariSanté Campus !
Registrations and submissions are open!!! www.linusbleistein.com/ramh
15.12.2025 21:25 —
👍 3
🔁 2
💬 0
📌 0
Daniel Beaglehole, David Holzm\"uller, Adityanarayanan Radhakrishnan, Mikhail Belkin: xRFM: Accurate, scalable, and interpretable feature learning models for tabular data https://arxiv.org/abs/2508.10053 https://arxiv.org/pdf/2508.10053 https://arxiv.org/html/2508.10053
15.08.2025 06:32 —
👍 3
🔁 3
💬 0
📌 0
Thanks!
30.07.2025 12:35 —
👍 0
🔁 0
💬 0
📌 0

I got 3rd out of 691 in a tabular kaggle competition – with only neural networks! 🥉
My solution is short (48 LOC) and relatively general-purpose – I used skrub to preprocess string and date columns, and pytabkit to create an ensemble of RealMLP and TabM models. Link below👇
29.07.2025 11:10 —
👍 11
🔁 2
💬 2
📌 0
Excited to have co-contributed the SquashingScaler, which implements the robust numerical preprocessing from RealMLP!
24.07.2025 16:00 —
👍 8
🔁 4
💬 0
📌 0
Is it because mathematicians think in terms of the number of assumptions that are satisfied, while physicists think in terms of the number of things that satisfy them?
23.07.2025 21:04 —
👍 1
🔁 0
💬 1
📌 0
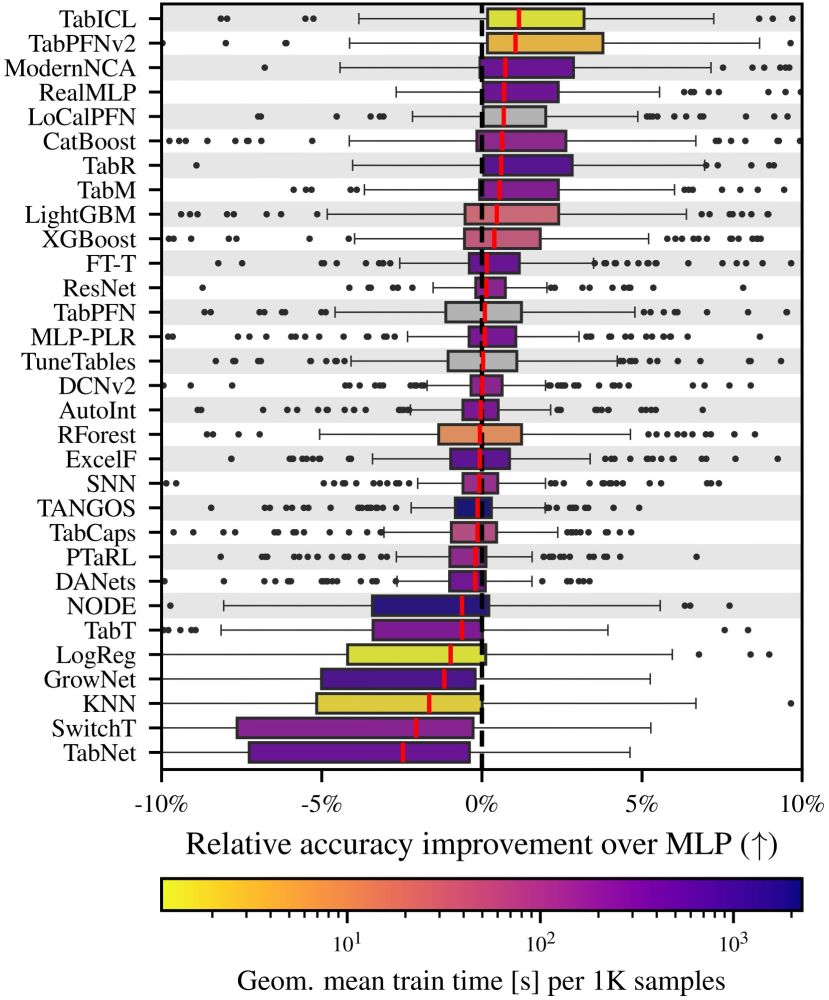
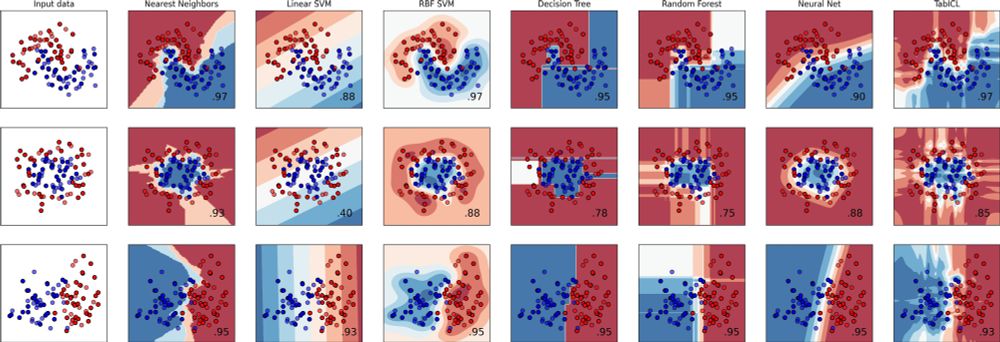
👨🎓🧾✨#icml2025 Paper: TabICL, A Tabular Foundation Model for In-Context Learning on Large Data
With Jingang Qu, @dholzmueller.bsky.social, and Marine Le Morvan
TL;DR: a well-designed architecture and pretraining gives best tabular learner, and more scalable
On top, it's 100% open source
1/9
09.07.2025 18:41 —
👍 50
🔁 15
💬 1
📌 0
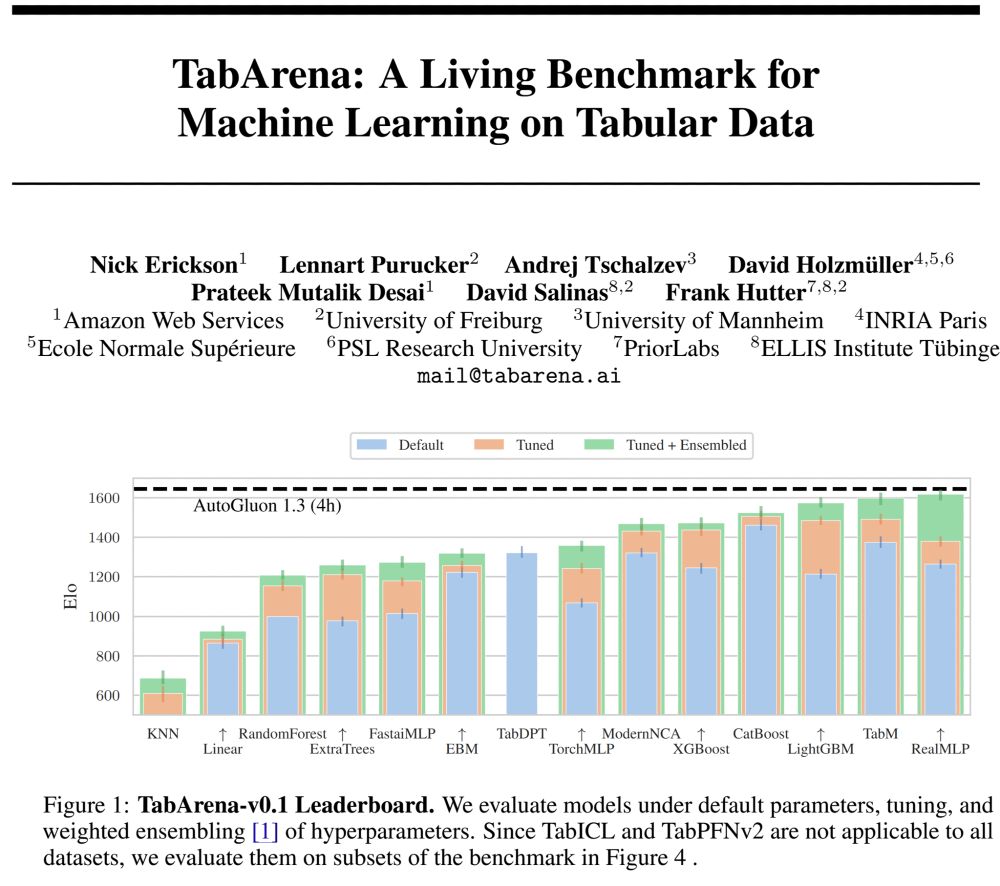
🚨What is SOTA on tabular data, really? We are excited to announce 𝗧𝗮𝗯𝗔𝗿𝗲𝗻𝗮, a living benchmark for machine learning on IID tabular data with:
📊 an online leaderboard (submit!)
📑 carefully curated datasets
📈 strong tree-based, deep learning, and foundation models
🧵
23.06.2025 10:14 —
👍 13
🔁 8
💬 1
📌 0
📝 The skrub TextEncoder brings the power of HuggingFace language models to embed text features in tabular machine learning, for all those use cases that involve text-based columns.
28.05.2025 08:43 —
👍 6
🔁 4
💬 2
📌 0
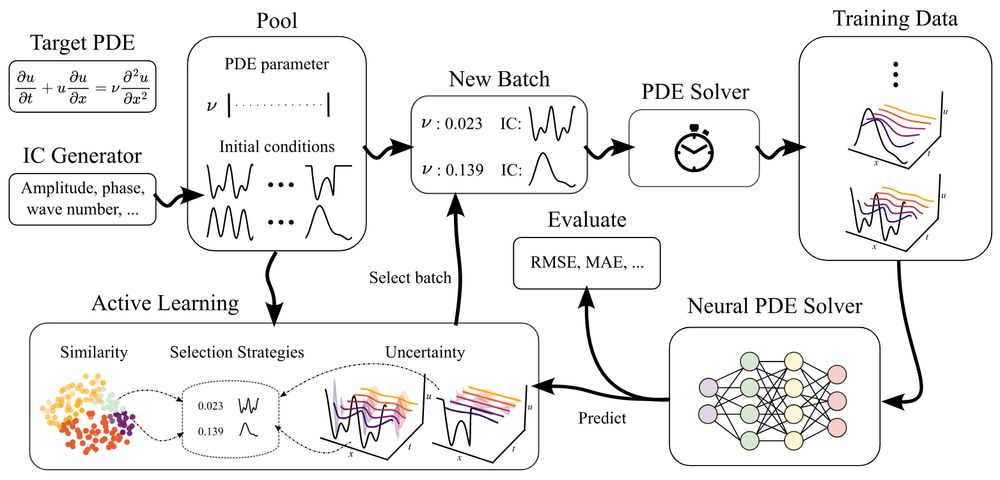
🚨ICLR poster in 1.5 hours, presented by @danielmusekamp.bsky.social :
Can active learning help to generate better datasets for neural PDE solvers?
We introduce a new benchmark to find out!
Featuring 6 PDEs, 6 AL methods, 3 architectures and many ablations - transferability, speed, etc.!
24.04.2025 00:38 —
👍 11
🔁 2
💬 1
📌 0
The Skrub TableReport is a lightweight tool that allows to get a rich overview of a table quickly and easily.
✅ Filter columns
🔎 Look at each column's distribution
📊 Get a high level view of the distributions through stats and plots, including correlated columns
🌐 Export the report as html
23.04.2025 11:49 —
👍 6
🔁 4
💬 1
📌 1
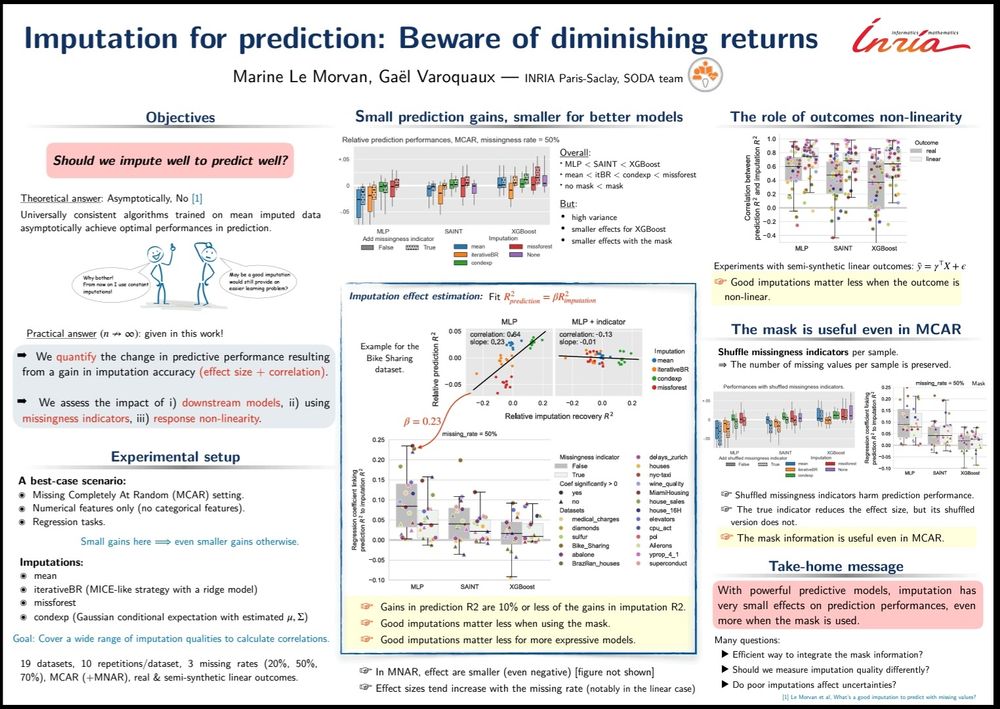
#ICLR2025 Marine Le Morvan presents "Imputation for prediction: beware of diminishing returns": poster Thu 24th
arxiv.org/abs/2407.19804
Concludes 6 years of research on prediction with missing values: Imputation is useful but improvements are expensive, while better learners yield easier gains.
23.04.2025 07:55 —
👍 48
🔁 8
💬 1
📌 0

Details about the seminar talk titled TabICL: A Tabular Foundation Model for In-Context Learning on Large Data by Marine Le Morvan
Excited to share the new monthly Table Representation Learning (TRL) Seminar under the ELLIS Amsterdam TRL research theme! To recur every 2nd Friday.
Who: Marine Le Morvan, Inria (in-person)
When: Friday 11 April 4-5pm (+drinks)
Where: L3.36 Lab42 Science Park / Zoom
trl-lab.github.io/trl-seminar/
02.04.2025 09:42 —
👍 12
🔁 3
💬 0
📌 1

We are excited to announce #FMSD: "1st Workshop on Foundation Models for Structured Data" has been accepted to #ICML 2025!
Call for Papers: icml-structured-fm-workshop.github.io
25.03.2025 17:59 —
👍 16
🔁 10
💬 0
📌 2

Trying something new:
A 🧵 on a topic I find many students struggle with: "why do their 📊 look more professional than my 📊?"
It's *lots* of tiny decisions that aren't the defaults in many libraries, so let's break down 1 simple graph by @jburnmurdoch.bsky.social
🔗 www.ft.com/content/73a1...
20.11.2024 17:02 —
👍 1585
🔁 462
💬 92
📌 96
🚀Continuing the spotlight series with the next @iclr-conf.bsky.social MLMP 2025 Oral presentation!
📝LOGLO-FNO: Efficient Learning of Local and Global Features in Fourier Neural Operators
📷 Join us on April 27 at #ICLR2025!
#AI #ML #ICLR #AI4Science
18.03.2025 08:12 —
👍 2
🔁 2
💬 1
📌 0
Links:
www.kaggle.com/competitions...
www.kaggle.com/competitions...
Link to the repo: github.com/dholzmueller...
PS: The newest pytabkit version now includes multiquantile regression for RealMLP and a few other improvements.
bsky.app/profile/dhol...
10.03.2025 15:53 —
👍 1
🔁 0
💬 0
📌 0
Rohlik Sales Forecasting Challenge
Use historical product sales data to predict future sales.
Practitioners are often sceptical of academic tabular benchmarks, so I am elated to see that our RealMLP model outperformed boosted trees in two 2nd place Kaggle solutions, for a $10,000 forecasting challenge and a research competition on survival analysis.
10.03.2025 15:53 —
👍 7
🔁 1
💬 1
📌 0







