Learn more about AlgoPerf and this new release here: github.com/mlcommons/al...
12.02.2026 09:45 — 👍 1 🔁 0 💬 0 📌 0
We just released AlgoPerf v1.0.1!
📚 New workload: AlgoPerf now includes a decoder-only 150M Language Model.
⚙️ Hardware switch: moving from 8xV100 to 4xA100.
🐞 Bug fixes and improved API.
Coming soon: updated leaderboard with new optimizers! 👀
12.02.2026 09:43 — 👍 0 🔁 0 💬 1 📌 0
YouTube video by Tübingen Machine Learning
ICLR 2025: Accelerating Neural Network Training (AlgoPerf)
The explainer video: www.youtube.com/watch?v=_yX1...
03.04.2025 11:15 — 👍 7 🔁 2 💬 0 📌 0
We're all about acceleration! 😉
Watch @priya-kasimbeg.bsky.social & @fsschneider.bsky.social speedrun an explanation of the AlgoPerf benchmark, rules, and results all within a tight 5 minutes for our #ICLR2025 paper video on "Accelerating Neural Network Training". See you in Singapore!
03.04.2025 11:15 — 👍 5 🔁 4 💬 1 📌 0
More details:
📄 ICLR 2025 results paper: openreview.net/pdf?id=CtM5x...
📄 Benchmark paper: arxiv.org/abs/2306.07179
💻 AlgoPerf codebase: github.com/mlcommons/al...
14.03.2025 20:56 — 👍 1 🔁 0 💬 0 📌 0

Algorithms - MLCommons
The Algorithms working group creates a set of rigorous and relevant benchmarks to measure neural network training speedups due to algorithmic improvements.
This is just the beginning! With the help of the community, we want to test even more training recipes, push the SOTA for neural network training methods even further, and improve the AlgoPerf benchmark. Follow us & join the working group (mlcommons.org/working-grou...).
14.03.2025 20:56 — 👍 1 🔁 0 💬 1 📌 0
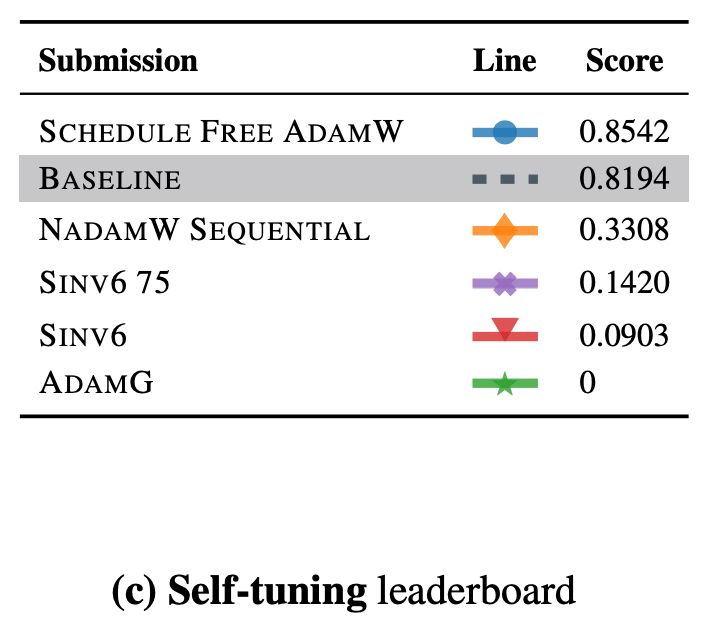
And the winner in the self-tuning ruleset, based on Schedule Free AdamW, demonstrated a new level of effectiveness for completely hyperparameter-free neural network training. Roughly ~10% faster training, compared to a NadamW baseline with well-tuned default hyperparameters.
14.03.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
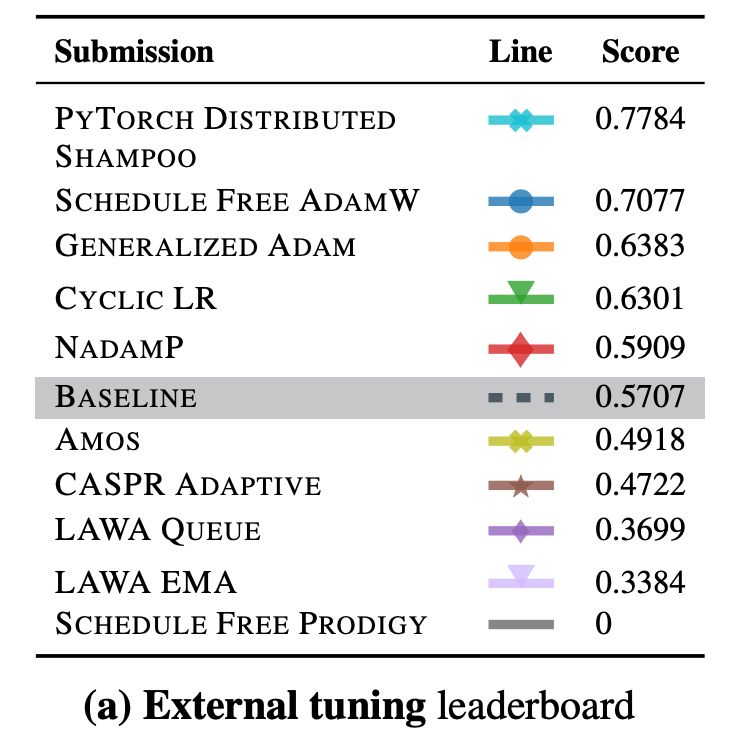
Then, we asked the community to submit training algorithms. The results? The winner of the external tuning ruleset, using Distributed Shampoo, reduced training time by ~30% over our well-tuned baseline—showing that non-diagonal methods can beat Adam, even in wall-clock time!
14.03.2025 20:56 — 👍 1 🔁 0 💬 1 📌 0
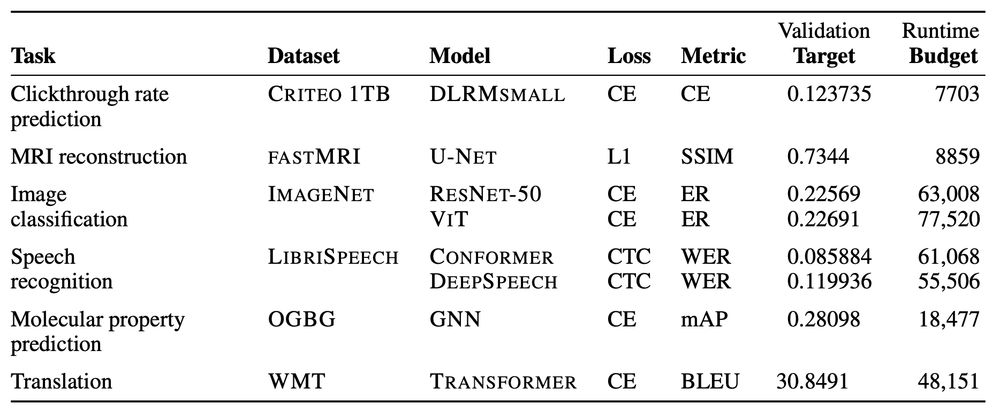
(3) Training algorithms must perform across 8 realistic deep learning workloads (ResNet-50, Conformer, ViT, etc.). (4) Submissions compete on the runtime to reach a given performance threshold. (5) Hyperparameter tuning is explicitly accounted for with our tuning rulesets.
14.03.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
Over the past years, we've built the AlgoPerf: Training Algorithms benchmark. The core ideas: (1) Only the training algorithm changes; everything else (hardware, model, data) stays fixed. (2) Submissions compete directly; no more weak baselines!
14.03.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
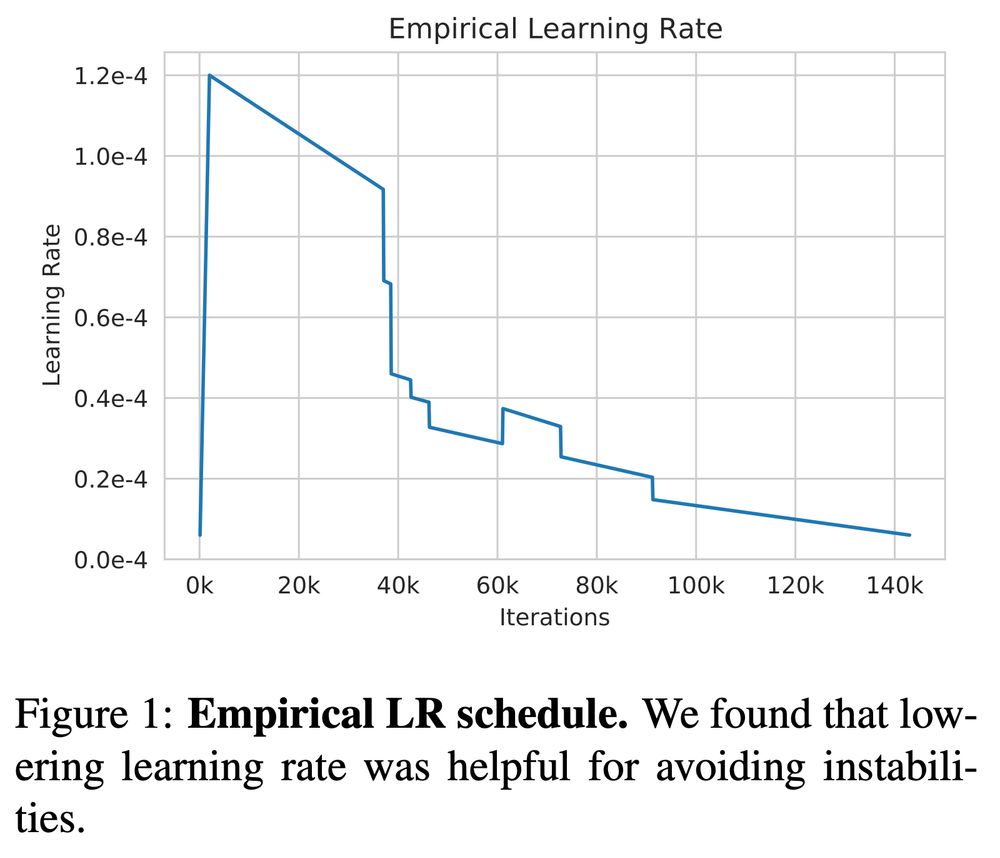
These choices are often critical, but reliable empirical guidance is scarce. Instead, we rely on expert intuition, anecdotal evidence, and babysitting. Check out this learning rate schedule from the OPT paper, which was manually determined. There has to be a better way!
14.03.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
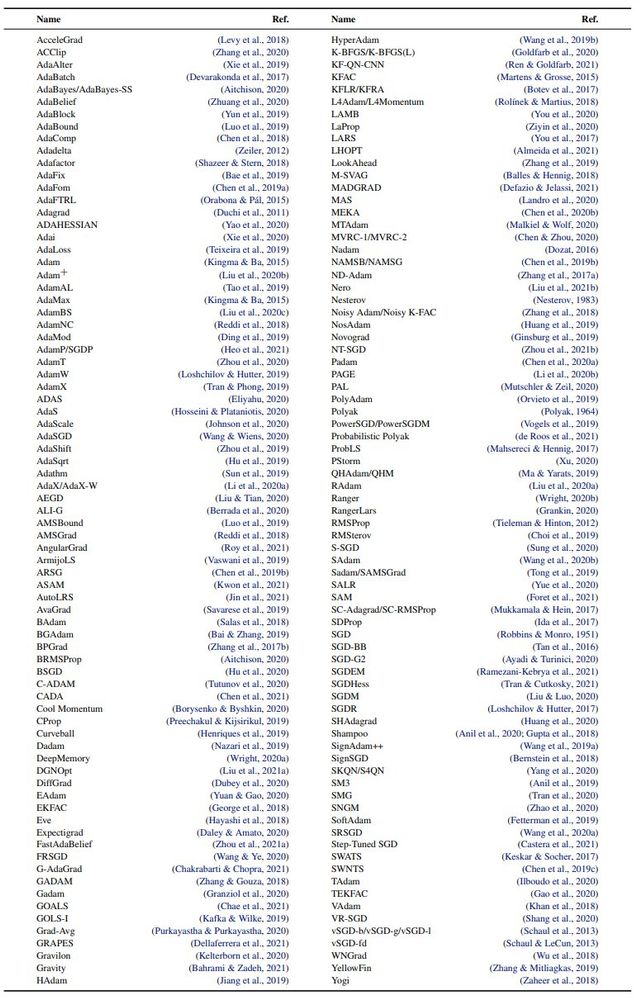
Currently, training neural nets is a complicated & fragile process with many important choices: How should I set/tune the learning rate? Using what schedule? Should I use SGD or Adam (or maybe Nadam/Amos/Shampoo/SOAP/Muon/... the list is virtually endless)?
14.03.2025 20:56 — 👍 0 🔁 0 💬 1 📌 0
Hi there! This account will post about the AlgoPerf benchmark and leaderboard updates for faster neural network training via better training algorithms. But let's start with what AlgoPerf is, what we have done so far, and how you can train neural nets ~30% faster.
14.03.2025 20:56 — 👍 6 🔁 3 💬 1 📌 1
Professor @UCLA, Research Scientist @ByteDance | Recent work: SPIN, SPPO, DPLM 1/2, GPM, MARS | Opinions are my own
Optimization Generative Modeling @Caltech, PhD @UCLA. ex Research Scientist Intern @AIatMeta (opinions are my own) why is jax so difficult
PhD Student at the University of Tübingen
Interested in ML in Science, Probabilistic Inference & Simulation
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
Asst. Prof. in Machine Learning at UofT. #LongCOVID patient.
https://www.cs.toronto.edu/~cmaddis/
https://Answer.AI & https://fast.ai founding CEO; previous: hon professor @ UQ; leader of masks4all; founding CEO Enlitic; founding president Kaggle; various other stuff…
Founder of MLCommons making machine learning better for everyone. MLPerf, CPUs, computer architecture, semiconductors, graphics, economics, writes RWT
MLCommons is an AI engineering consortium, built on a philosophy of open collaboration to improve AI systems. Through our collective engineering efforts, we continually measure and improve AI technologies' accuracy, safety, speed, and efficiency.
Postdoctoral researcher at the University of Tübingen working on (benchmarking) training methods for deep learning
Professor for AI/ML Methods in Tübingen. Posts about Probabilistic Numerics, Bayesian ML, AI for Science. Computations are data, Algorithms make assumptions.
Machine learning researcher
@Google DeepMind. My opinions do not necessarily represent my employer. Prefer email over DMs.
https://scholar.google.com/citations?hl=e&user=ghbWy-0AAAAJ
https://www.cs.toronto.edu/~gdahl/
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app

















