There is an Associate Professor position in CS at ENS Lyon, with potential integration in my team, starting in sept 2026: DM me in interested!
Details at www.ens-lyon.fr/LIP/images/P...
05.02.2026 09:04 — 👍 6 🔁 9 💬 0 📌 1
AISTATS 2026 will be in Morocco!
30.07.2025 08:07 — 👍 35 🔁 10 💬 0 📌 0
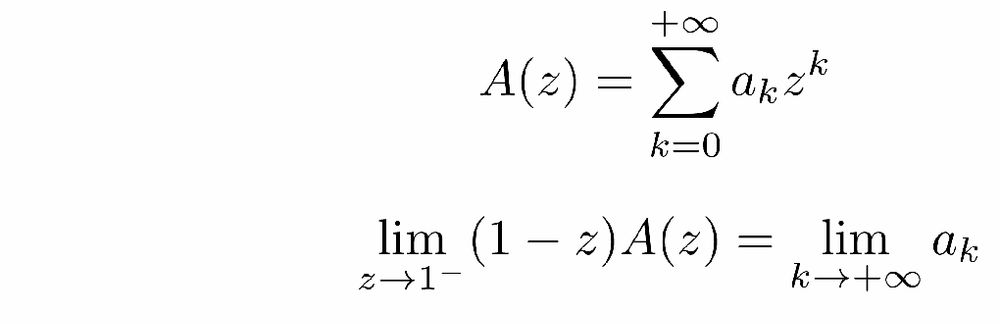
Tired of lengthy computations to derive scaling laws? This post is made for you: discover the sharpness of the z-transform!
francisbach.com/z-transform/
18.07.2025 14:24 — 👍 19 🔁 4 💬 0 📌 0
❓ How long does SGD take to reach the global minimum on non-convex functions?
With W. Azizian, J. Malick, P. Mertikopoulos, we tackle this fundamental question in our new ICML 2025 paper: "The Global Convergence Time of Stochastic Gradient Descent in Non-Convex Landscapes"
18.06.2025 13:59 — 👍 8 🔁 2 💬 1 📌 0
New paper on the generalization of Flow Matching www.arxiv.org/abs/2506.03719
🤯 Why does flow matching generalize? Did you know that the flow matching target you're trying to learn *can only generate training points*?
w @quentinbertrand.bsky.social @annegnx.bsky.social @remiemonet.bsky.social 👇👇👇
18.06.2025 08:08 — 👍 55 🔁 17 💬 2 📌 3

Register at PAISS 1-5 Sept 2025 @inria_grenoble with very talented speakers this year 🙂
paiss.inria.fr
cc @mvladimirova.bsky.social
09.06.2025 20:54 — 👍 8 🔁 4 💬 1 📌 0
🎉🎉🎉Our paper "Inexact subgradient methods for semialgebraic
functions" is accepted at Mathematical Programming !! This is a joint work with Jerome Bolte, Eric Moulines and Edouard Pauwels where we study a subgradient method with errors for nonconvex nonsmooth functions.
arxiv.org/pdf/2404.19517
05.06.2025 06:13 — 👍 8 🔁 3 💬 3 📌 0

📣 New preprint 📣
**Differentiable Generalized Sliced Wasserstein Plans**
w/
L. Chapel
@rtavenar.bsky.social
We propose a Generalized Sliced Wasserstein method that provides an approximated transport plan and which admits a differentiable approximation.
arxiv.org/abs/2505.22049 1/5
02.06.2025 14:40 — 👍 23 🔁 6 💬 1 📌 1
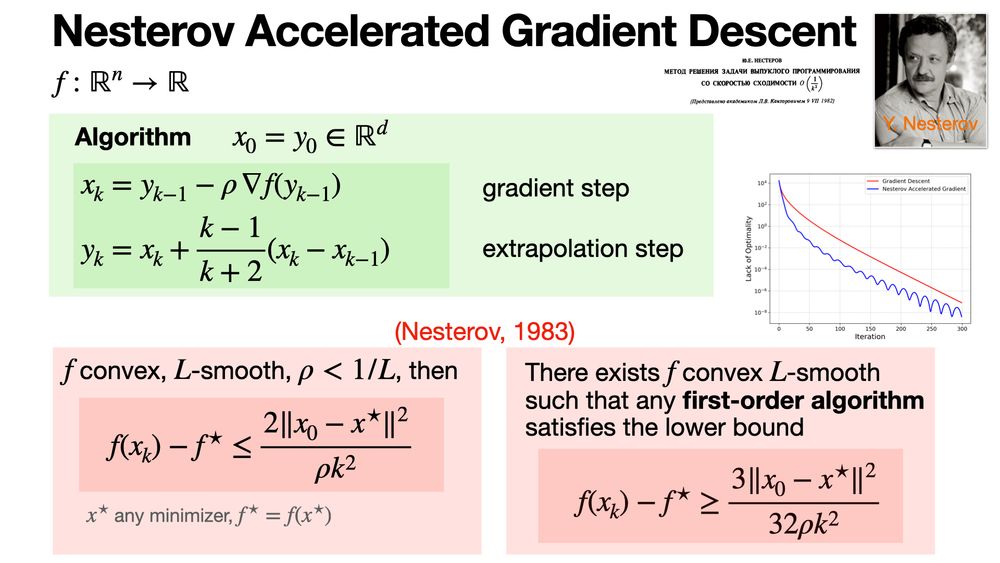
The Nesterov Accelerated Gradient (NAG) algorithm refines gradient descent by using an extrapolation step before computing the gradient. It leads to faster convergence for smooth convex functions, achieving the optimal rate of O(1/k^2). www.mathnet.ru/links/ceedfb...
25.04.2025 05:01 — 👍 17 🔁 3 💬 0 📌 0

Geometric and computational hardness of bilevel programming
We first show a simple but striking result in bilevel optimization: unconstrained $C^\infty$ smooth bilevel programming is as hard as general extended-real-valued lower semicontinuous minimization. We...
Our paper
**Geometric and computational hardness of bilevel programming**
w/ Jerôme Bolte, Tùng Lê & Edouard Pauwels
has been accepted to Mathematical Programming!
We study how difficult it may be to solve bilevel optimization beyond strongly convex inner problems
arxiv.org/abs/2407.12372
01.04.2025 15:55 — 👍 16 🔁 1 💬 2 📌 0

📣 New preprint 📣
Learning Theory for Kernel Bilevel Optimization
w/ @fareselkhoury.bsky.social E. Pauwels @michael-arbel.bsky.social
We provide generalization error bounds for bilevel optimization problems where the inner objective is minimized over a RKHS.
arxiv.org/abs/2502.08457
20.02.2025 13:55 — 👍 20 🔁 6 💬 1 📌 2

Complex step approximation is a numerical method to approximate the derivative from a single function evaluation using complex arithmetic. It is some kind of “poor man” automatic differentiation. https://nhigham.com/2020/10/06/what-is-the-complex-step-approximation/
17.02.2025 06:00 — 👍 24 🔁 4 💬 2 📌 1

Screenshot of the abstract of the paper
📢 New preprint 📢
Bilevel gradient methods and Morse parametric qualification
w/ J. Bolte, T. Lê, E. Pauwels
We study bilevel optimization with a nonconvex inner objective. To do so, we propose a new setting (Morse parametric qualification) to study bilevel algorithms.
arxiv.org/abs/2502.09074
14.02.2025 10:18 — 👍 16 🔁 3 💬 1 📌 1
My rant of the day: You can be rejected from an MSCA postdoctoral fellowship despite scoring almost the maximum in every category and receiving virtually no negative feedback. Before I explain why this is disastrous (assuming it is a common issue), a few comments.
10.02.2025 07:28 — 👍 18 🔁 6 💬 1 📌 0
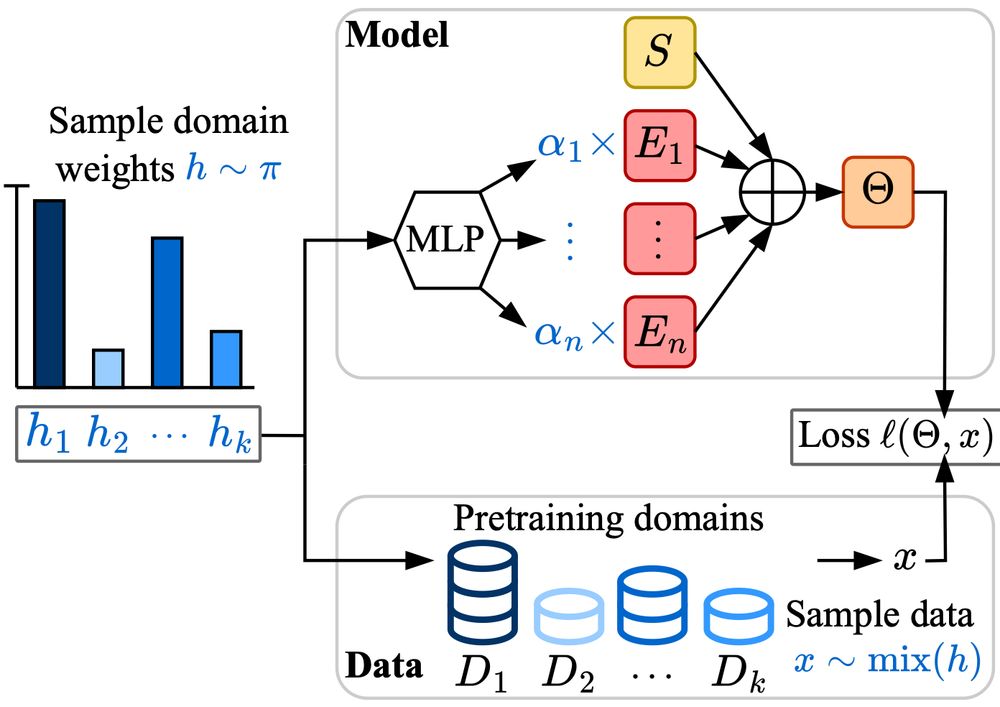
Excited to share Soup-of-Experts, a new neural network architecture that, for any given specific task, can instantiate in a flash a small model that is very good on it.
Made with ❤️ at Apple
Thanks to my co-authors David Grangier, Angelos Katharopoulos, and Skyler Seto!
arxiv.org/abs/2502.01804
05.02.2025 09:32 — 👍 12 🔁 4 💬 0 📌 0
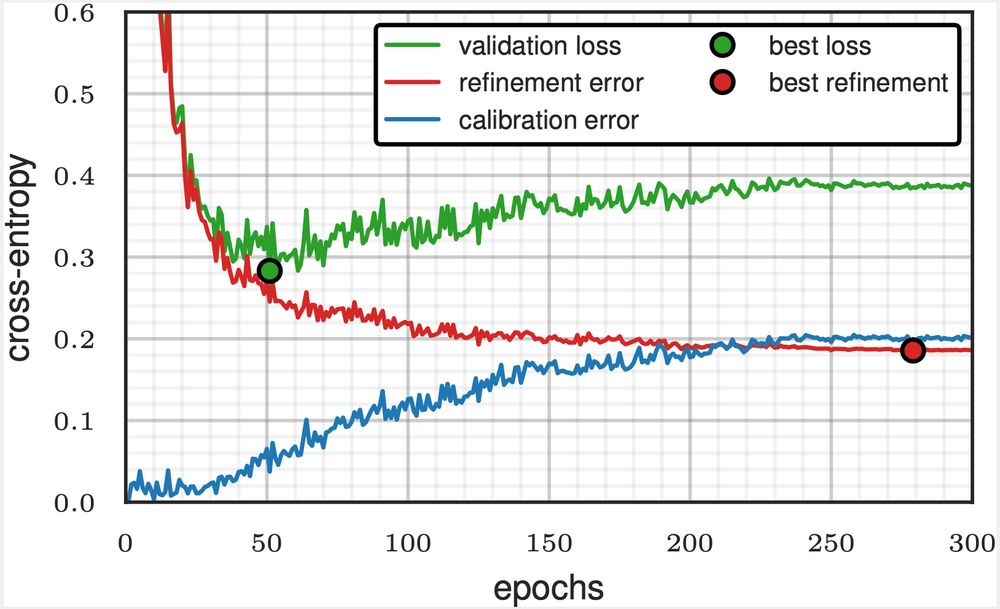
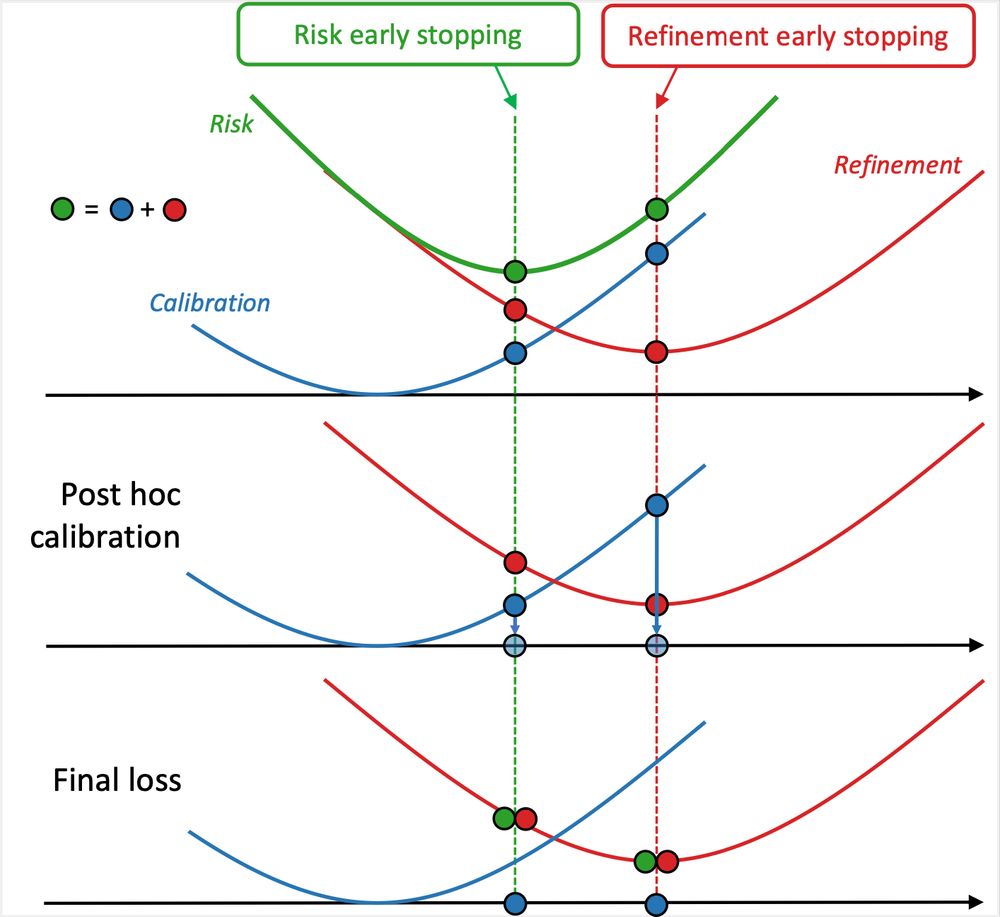
Early stopping on validation loss? This leads to suboptimal calibration and refinement errors—but you can do better!
With @dholzmueller.bsky.social, Michael I. Jordan, and @bachfrancis.bsky.social, we propose a method that integrates with any model and boosts classification performance across tasks.
03.02.2025 13:03 — 👍 18 🔁 9 💬 4 📌 0
How to compute Hessian-vector products? | ICLR Blogposts 2024
The product between the Hessian of a function and a vector, the Hessian-vector product (HVP), is a fundamental quantity to study the variation of a function. It is ubiquitous in traditional optimizati...
Conventional wisdom in ML is that the computation of full Jacobians and Hessians should be avoided. Instead, practitioners are advised to compute matrix-vector products, which are more in line with the inner workings of automatic differentiation (AD) backends such as PyTorch and JAX.
30.01.2025 14:32 — 👍 8 🔁 1 💬 1 📌 0
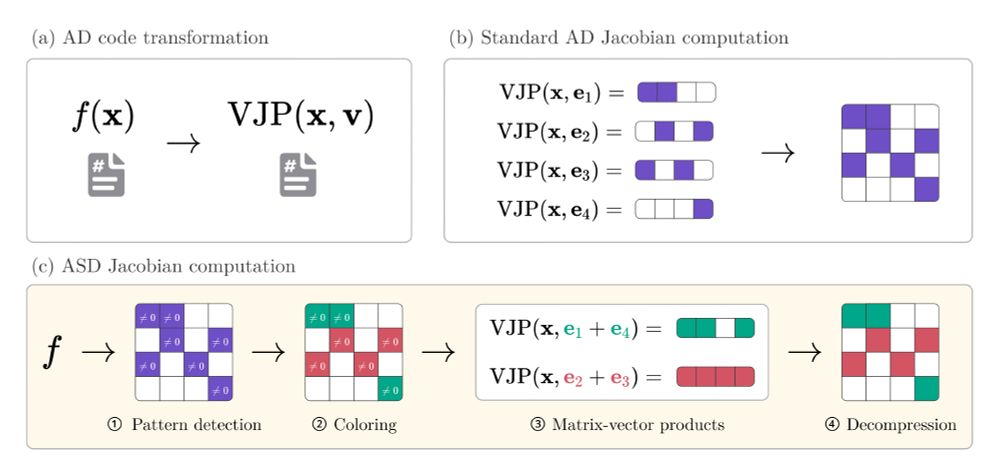
Figure comparing automatic differentiation (AD) and automatic sparse differentiation (ASD).
(a) Given a function f, AD backends return a function computing vector-Jacobian products (VJPs). (b) Standard AD computes Jacobians row-by-row by evaluating VJPs with all standard basis vectors. (c) ASD reduces the number of VJP evaluations by first detecting a sparsity pattern of non-zero values, coloring orthogonal rows in the pattern and simultaneously evaluating VJPs of orthogonal rows. The concepts shown in this figure directly translate to forward-mode, which computes Jacobians column-by-column instead of row-by-row.
You think Jacobian and Hessian matrices are prohibitively expensive to compute on your problem? Our latest preprint with @gdalle.bsky.social might change your mind!
arxiv.org/abs/2501.17737
🧵1/8
30.01.2025 14:32 — 👍 142 🔁 29 💬 3 📌 4

The Mathematics of Artificial Intelligence: In this introductory and highly subjective survey, aimed at a general mathematical audience, I showcase some key theoretical concepts underlying recent advancements in machine learning. arxiv.org/abs/2501.10465
22.01.2025 09:11 — 👍 147 🔁 43 💬 2 📌 1

The Cheap Gradient Principle (Baur—Strassen, 1983) states that computing gradients via automatic differentiation is efficient: the gradient of a function f can be obtained with a cost proportional to evaluating f
16.01.2025 06:00 — 👍 33 🔁 2 💬 2 📌 1
The Marchenko–Pastur law describes the limiting spectral distribution of eigenvalues of large random covariance matrices. The theorem proves that as dimensions grow, the empirical spectral distribution converges weakly to this law. https://buff.ly/406Xaxg
22.01.2025 06:00 — 👍 13 🔁 3 💬 0 📌 0
⭐️⭐️ Internship positions ⭐️⭐️
1) NLP and predictive ML to improve the management of stroke, in a multi-disciplinary and stimulating environment under the joint supervision of @adrien3000 from the @TeamHeka, me from @soda_INRIA and Eric Jouvent from @APHP team.inria.fr/soda/files/...
10.01.2025 14:16 — 👍 1 🔁 1 💬 1 📌 0
When optimization problems have multiple minima, algorithms favor specific solutions due to their implicit bias. For ordinary least squares (OLS), gradient descent inherently converges to the minimal norm solution among all possible solutions. https://fa.bianp.net/blog/2022/implicit-bias-regression/
19.12.2024 06:00 — 👍 24 🔁 5 💬 2 📌 0

[NOUVELLE PRESIDENTE A L'ACADEMIE DES SCIENCES]
Françoise Combes élue présidente pour 2025-2026. Elle succède à Alain Fischer et devient la 2e femme à présider cette illustre institution, après Marianne Grunberg-Manago.
@combesfrancoise.bsky.social
@collegedefrance.bsky.social
17.12.2024 12:54 — 👍 20 🔁 11 💬 0 📌 0
Automatic differentiation in forward mode computes derivatives by breaking down functions into elem operations and propagating derivatives alongside values. It’s efficient for functions with fewer inputs than outputs and for Jacobian-vect prod, using for instance dual numbers.
13.12.2024 06:00 — 👍 37 🔁 10 💬 2 📌 0

Congratulations to Dr. Matthieu Cordonnier for his thesis on convergence properties of large random graph supervised by N. Tremblay, @nicolaskeriven.bsky.social and myself. Matthieu is on the job market now for a postdoc, feel free to reach him!
03.12.2024 12:45 — 👍 7 🔁 2 💬 0 📌 0
Assistant professor at Ecole polytechnique.
Optimization, Federated Learning, Reinforcement Learning, Privacy
PhD student @ University of Toronto
FORM Lab
Portfolio Optimization and Optimization methods
Research Associate @The Alan Turing Institute | Probability | Spatio-temporal | Generative Models | Stochastic Processes | Cats | PhD in Mathematics.
Algorithm Auditing | CS PhD student @ INRIA/IRISA/PEReN | Visiting UofT @ CleverHans Lab !
Team leader (tenured) at RIKEN AIP. Opinions my own. https://emtiyaz.github.io
🌉 bridged from https://mastodon.social/@emtiyaz on the fediverse by https://fed.brid.gy/
PhD Student at Valeo.ai and Telecom Paris
Post-doc @ Télécom SudParis
PhD student at École polytechnique. Optimization, machine learning, robustness
renaudgaucher.github.io
PhD student in computer vision at Imagine, ENPC and EFEO.
PhD student at Université Côte d’Azur
PhD student in Machine Learning at Inria
Postdoctoral researcher @ UC Berkeley, Statistics department | PhD in statistics @ Inria, @ École polytechnique
PhD student in Machine Learning @Warsaw University of Technology and @IDEAS NCBR
Math Assoc. Prof. (on leave, Aix-Marseille, France)
Interest: Prob / Stat / ANT. See: https://sites.google.com/view/sebastien-darses/research?authuser=0
Teaching Project (non-profit): https://highcolle.com/
PhD student at INRIA Paris. Working on calibration of machine learning classifiers.
PhD student at @bifold.berlin, Machine Learning Group, TU Berlin.
Automatic Differentiation, Explainable AI and #JuliaLang.
Open source person: adrianhill.de
Researcher at Criteo. Interested in Bandits, Privacy, Competitive Analysis, Reinforcement Learning.
https://hugorichard.github.io/




























