
We tend to conflate "autonomy" with "reliability" in AI agents. But autonomy without trust is catastrophically dangerous.
Our new paper formalizes UQ for LLM agents, proposes a new lens: agent uncertainty as a conditional uncertainty reduction process.
📄 huggingface.co/papers/2602....
07.02.2026 16:33 — 👍 4 🔁 1 💬 1 📌 0

🎭 How do LLMs (mis)represent culture?
🧮 How often?
🧠 Misrepresentations = missing knowledge? spoiler: NO!
At #CHI2026 we are bringing ✨TALES✨ a participatory evaluation of cultural (mis)reps & knowledge in multilingual LLM-stories for India
📜 arxiv.org/abs/2511.21322
1/10
02.02.2026 21:38 — 👍 45 🔁 21 💬 1 📌 2
#ChatGPT began to put ads in their response.
Check our paper on “how fair ranking can positively impact the LLM response and content/ad exposure”.
dl.acm.org/doi/10.1145/...
17.01.2026 06:20 — 👍 4 🔁 0 💬 0 📌 0
#chatGPT began to put ads in their response.
Check out our paper on “Ads detection and integration in the era of LLMs”.
ceur-ws.org/Vol-4038/pap...
17.01.2026 06:16 — 👍 1 🔁 0 💬 0 📌 0
as AI increasingly supports shopping and ads, it’s worth remembering that retrieval often shapes who gets exposure in final generated output. in a recent paper, @teknology.bsky.social uses methods from fair ranking to assess and address exposure bias in downstream generation.
841.io/doc/fairrag....
31.12.2025 14:00 — 👍 9 🔁 3 💬 0 📌 1

advertisement generation and detection in RAG
Excited to present at #CLEF2025 #Touché Lab (Session 2) shared task "Advertisement in RAG"🇪🇸!
@webis.de
🗓️Sept 9 (Tue)
⏲️5:20PM (CEST) / 11:20AM (EST)
📍Florentino Sanz Room
🧠https://arxiv.org/abs/2507.00509
Join us for insights on #RAG + advertising!
09.09.2025 00:02 — 👍 1 🔁 0 💬 0 📌 1

an aerial view of tokyo at night with lots of lights
ALT: an aerial view of tokyo at night with lots of lights
Some exciting news! 🤗 After 3 amazing years at TREC, the Tip-of-the-Tongue (ToT) shared task will be a core task at NTCIR-19 in 2026. The new track will focus on tip-of-the-tongue information needs in English and East Asian languages.
More details coming soon. See you all in Tokyo next year!
01.09.2025 16:12 — 👍 5 🔁 3 💬 0 📌 0
Gentle reminder 📢
All run submissions for the Tip-of-the-Tongue (ToT) Track are due next week Wednesday (Aug 27).
More info: trec-tot.github.io/guidelines
#TREC2025 #TRECToT #TREC2025ToT
19.08.2025 16:45 — 👍 2 🔁 2 💬 0 📌 1
This year's TREC Tip of the Tongue (ToT) track will be amazing! Based on our rigorous experiments on synthetic ToT query generation presented at #SIGIR2025, we extended the track to open domain ToT queries.
We provide codes for baseline systems, and submissions are due by August 27th!
04.08.2025 17:52 — 👍 1 🔁 1 💬 0 📌 0
Hello TREC-ToTers!
We have released the test queries for the TREC 2025 Tip-of-the-Tongue (TREC-ToT) Track. Please see the guidelines for more information: trec-tot.github.io/guidelines. Run submission deadline will tentatively be in August. #TREC2025 #TRECToT #TREC2025ToT
Please spread the word!
13.07.2025 16:47 — 👍 3 🔁 3 💬 0 📌 1
❓How do LLMs respond to fair ranking in RAG?
🤩 See how fair ranking boosts downstream utility while promoting fairer attribution of cited sources.
Catch our oral presentation at #ICTIR2025!
#SIGIR2025 @841io.bsky.social
12.07.2025 13:32 — 👍 7 🔁 0 💬 0 📌 1

Dory from finding nemo with the quote: "I remember it like it was yesterday. Of course, I dont remember yesterday."
Do not forget to participate in the #TREC2025 Tip-of-the-Tongue (ToT) Track :)
The corpus and baselines (with run files) are now available and easily accessible via the ir_datasets API and the HuggingFace Datasets API.
More details are available at: trec-tot.github.io/guidelines
27.06.2025 14:46 — 👍 11 🔁 7 💬 0 📌 0
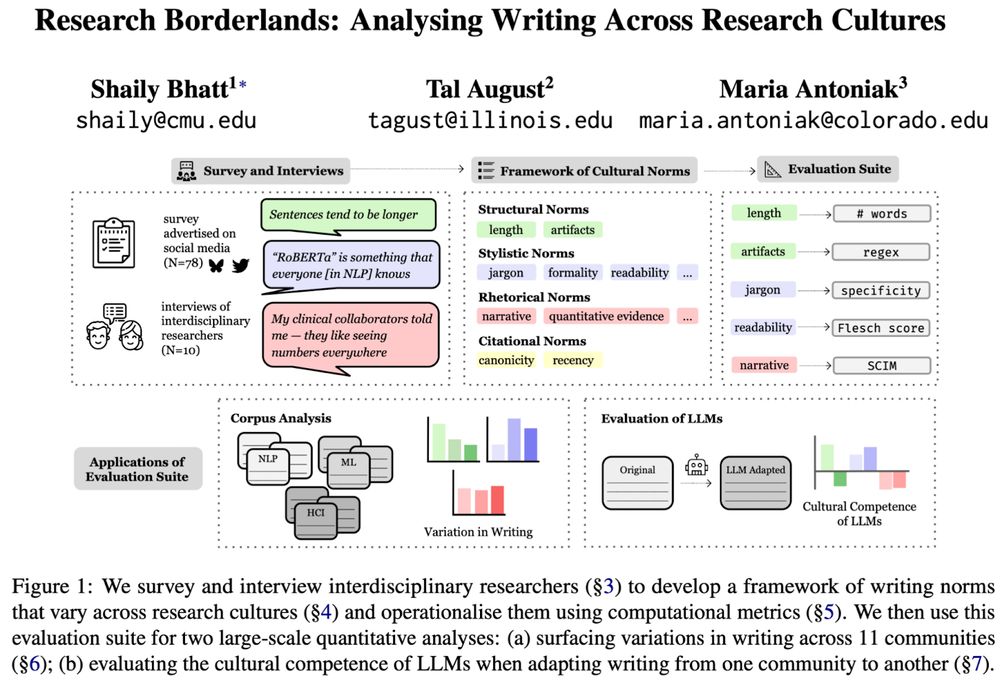
An overview of the work “Research Borderlands: Analysing Writing Across Research Cultures” by Shaily Bhatt, Tal August, and Maria Antoniak. The overview describes that We survey and interview interdisciplinary researchers (§3) to develop a framework of writing norms that vary across research cultures (§4) and operationalise them using computational metrics (§5). We then use this evaluation suite for two large-scale quantitative analyses: (a) surfacing variations in writing across 11 communities (§6); (b) evaluating the cultural competence of LLMs when adapting writing from one community to another (§7).
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
09.06.2025 23:29 — 👍 72 🔁 30 💬 1 📌 5
TREC 2025 Tip-of-the-Tongue (ToT) Track
Tip of the tongue: The phenomenon of failing to retrieve something from memory, combined with partial recall and the feeling that retrieval is imminent.
Hello TREC-ToTers! 👋🏽
Excited to announce the release of TREC 2025 Tip-of-the-Tongue (TREC-ToT) Track guidelines: trec-tot.github.io/guidelines. We will release test queries in July and run submission deadline will be in August. #TREC2025 #TRECToT #TREC2025ToT
Please register to participate:
09.05.2025 21:02 — 👍 4 🔁 2 💬 0 📌 1
Related paper here!
bsky.app/profile/841i...
29.04.2025 21:29 — 👍 0 🔁 0 💬 0 📌 0
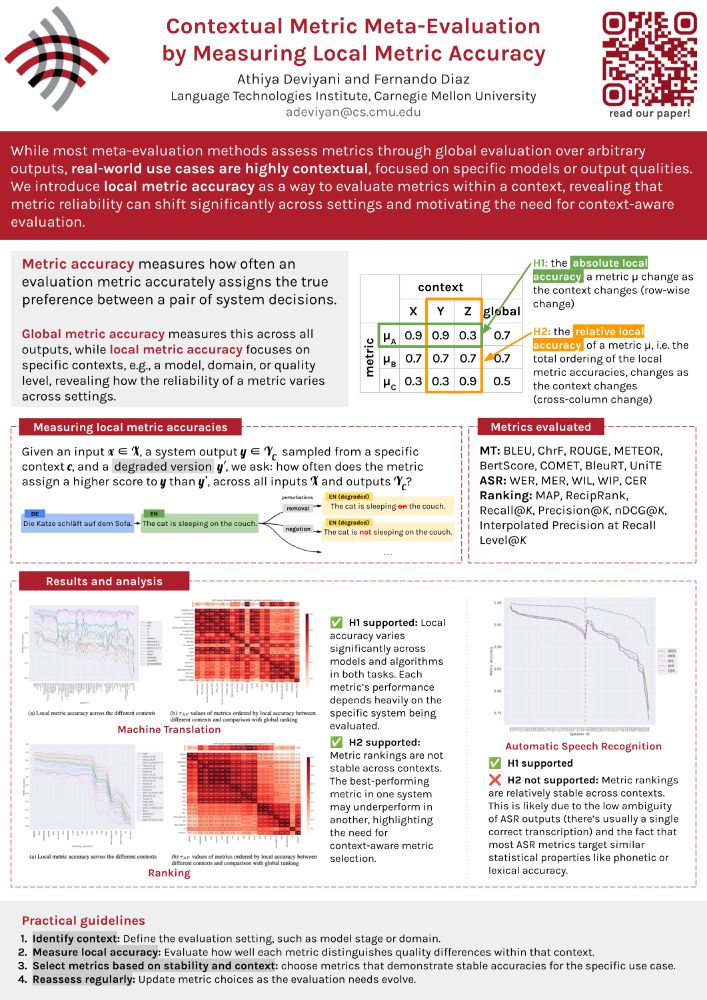
Ever trusted a metric that works great on average, only for it to fail in your specific use case?
In our #NAACL2025 paper (w/ @841io.bsky.social), we show why global evaluations are not enough and why context matters more than you think.
📄 aclanthology.org/2025.finding...
#NLP #Evaluation
(🧵1/9)
29.04.2025 17:10 — 👍 23 🔁 5 💬 1 📌 2
If you're working on a recall-oriented task or with ranking systems evaluated across varied users, content, or intents, check it out. 5/5
dl.acm.org/doi/10.1145/...
07.04.2025 16:15 — 👍 1 🔁 2 💬 0 📌 0

A ven diagram showing that the recall and robustness, each of which has many different conceptions, interest when thinking about recall as "totality" and robustness as "worst-case performance". It's in this intersection that lexicographic recall (lexirecall) lives.
📢 New Paper: "Recall, Robustness, and Lexicographic Evaluation" (ACM TORS)
F Diaz, M Ekstrand (@md.ekstrandom.net), B Mitra (@bmitra.bsky.social)
For IR, NLP, and ML researchers working on ranking systems evaluated for recall and robustness. 🧵 1/5 dl.acm.org/doi/10.1145/...
07.04.2025 16:15 — 👍 14 🔁 6 💬 1 📌 0
Here's an overview of TREC 2024 TOT track runs with the test queries:
trec.nist.gov/pubs/trec33/...
07.03.2025 16:29 — 👍 0 🔁 0 💬 0 📌 0
Yes! Thats exactly the case of TOT retrieval for academics :)
05.03.2025 22:08 — 👍 0 🔁 0 💬 0 📌 0
Overview
Tip of the tongue: The phenomenon of failing to retrieve something from memory, combined with partial recall and the feeling that retrieval is imminent.
These approaches powered the TREC 2024 TOT track test queries and will continue into the 2025 track (trec-tot.github.io).
Joyful collaboration with Yifan He @841io.bsky.social Jaime Arguello, and @bmitra.bsky.social !
#SIGIR #TREC #TOT
05.03.2025 01:37 — 👍 4 🔁 2 💬 1 📌 0
⚡️Multi-Domain Coverage
Combining both methods allows TOT query evaluation in multiple domains. We tested simulated evaluation in Movie, Landmark, and Person domains. Moreover, we build a broader, more inclusive TOT test collection.
05.03.2025 01:36 — 👍 2 🔁 1 💬 1 📌 0

Human TOT query elicitation interface
Solution2️⃣: Human-Elicitation
We designed an interface with visual prompts to induce a TOT state in human participants. Their queries closely match authentic TOT queries and captures genuine TOT experiences in a controlled setting.
05.03.2025 01:35 — 👍 3 🔁 1 💬 1 📌 0

System rank correlation as a validation method for synthetic TOT queries.
Solution1️⃣: LLM-Elicitation
We built a TOT user simulator to produce synthetic queries. Results show high system rank correlation and linguistic similarity compared to real queries. This scalable simulated evaluation method overcomes data scarcity by simulating new queries on demand.
05.03.2025 01:35 — 👍 3 🔁 1 💬 1 📌 0
🤔Why the Problem?
TOT query data collection relies heavily on community question answering websites (e.g., Reddit). This causes data availability issues and domain bias (most TOT queries end up being about movies or books).
05.03.2025 01:33 — 👍 4 🔁 1 💬 1 📌 0
👅Tip-of-the-Tongue (TOT) search is a complex form of known-item search, shaped by the expression of partial recall, personal context, and uncertain memories. However, TOT research has long been hindered by the scarcity of high-quality TOT queries.
05.03.2025 01:33 — 👍 5 🔁 1 💬 1 📌 0
AI agents as first-class retrieval targets.
AgentSearch Workshop @.
PhD Student at UCL, Bloomberg Data Science Ph.D. Fellow
CS Professor at UQAM, synthetic data, privacy, data science in general
aka Boe
big fan of the earth
UW CSE
boezzz.com
Waiting on a robot body. All opinions are universal and held by both employers and family. ML/NLP professor.
nsaphra.net
multi-model @ ¬◇ | ex ai safety @LTI, CMU
SIGIR is the Association for Computing Machinery’s Special Interest Group on Information Retrieval. Since 1963, we have promoted research, development and education in the area of search and other information access technologies.
Visit: https://sigir.org/
PhD student at the CIR Group, TH Köln, Germany
Postdoc at the University of Edinburgh | PhD, University of Amsterdam | Former Applied Scientist Intern at Amazon
Offizieller Account der Universität Tübingen.
Impressum: https://uni-tuebingen.de/impressum/
Datenschutz: https://uni-tuebingen.de/impressum/bluesky-hinweise/
Machine learning and information retrieval researcher. | Assistant professor at Radboud University Nijmegen and visiting research scholar at Google DeepMind. | Previously at Google Research, Twitter and University of Amsterdam.
Research in NLP (mostly LM interpretability & explainability).
Assistant prof at UMD CS + CLIP.
Previously @ai2.bsky.social @uwnlp.bsky.social
Views my own.
sarahwie.github.io
Posting about research fby and events and news relevant for the Amsterdam NLP community. Account maintained by @wzuidema@bsky.social
📚 Researcher • 💻 Developer • 🇪🇺 European
PhD student for health-related information retrieval at @uni-jena.de × @webis.de
Prof at Saarland. NLP and machine learning.
Theory and interpretability of LLMs.
https://www.mhahn.info
#NLP Postdoc at Mila - Quebec AI Institute and McGill University | Former PhD @ University of Copenhagen (CopeNLU)
🌐 karstanczak.github.io
PhD student @ltiatcmu.bsky.social. he/him



























