Co-first authors: @LeonGuertler @simon_ycl @zzlccc, advisor @natashajaques.bsky.social
Team: @QPHutu @danibalcells @mickel_liu C.Tan @shi_weiyan @mavenlin W.S.Lee
@NUSingapore @ASTARsg @Northeastern @UW 🚀
01.07.2025 20:13 — 👍 3 🔁 0 💬 0 📌 0
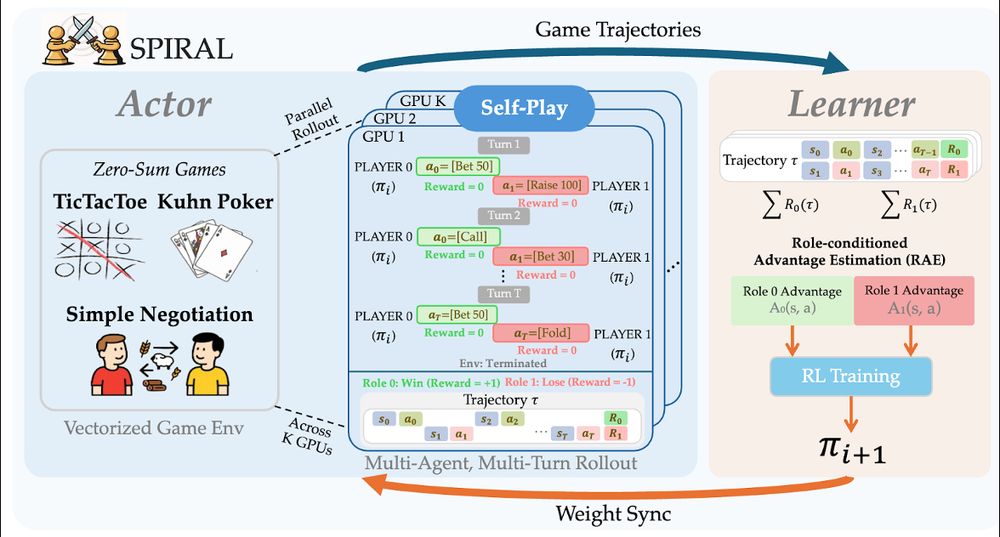
New paradigm: instead of curating problems, create environments where models discover reasoning through competition.
Self-play = autonomous improvement without human supervision. Simple games improve general reasoning!
01.07.2025 20:11 — 👍 5 🔁 1 💬 1 📌 1
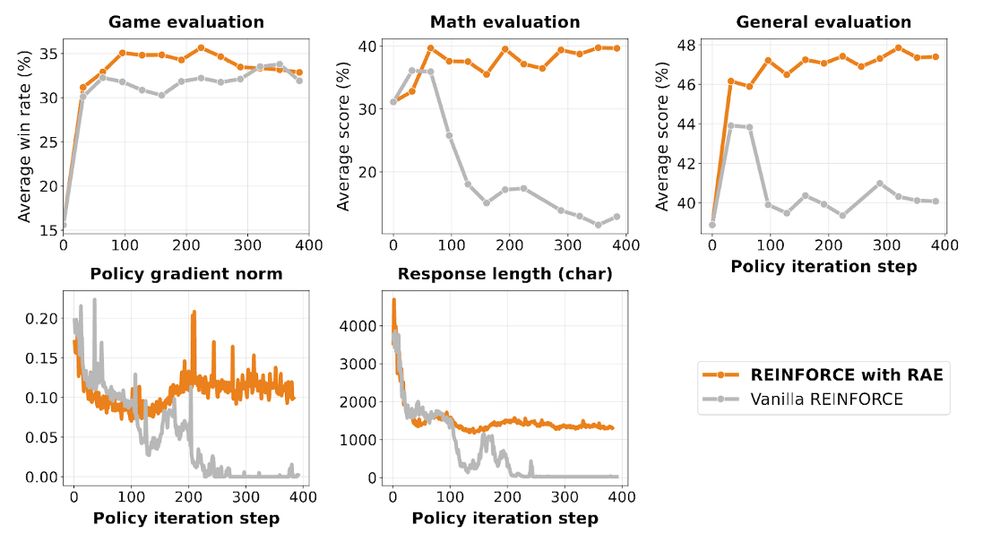
We developed Role-conditioned Advantage Estimation (RAE) to stabilize training.
Without RAE: "thinking collapse" - responses crash 3500→0 chars, math drops 66%
RAE keeps reasoning alive!
01.07.2025 20:11 — 👍 1 🔁 0 💬 1 📌 0
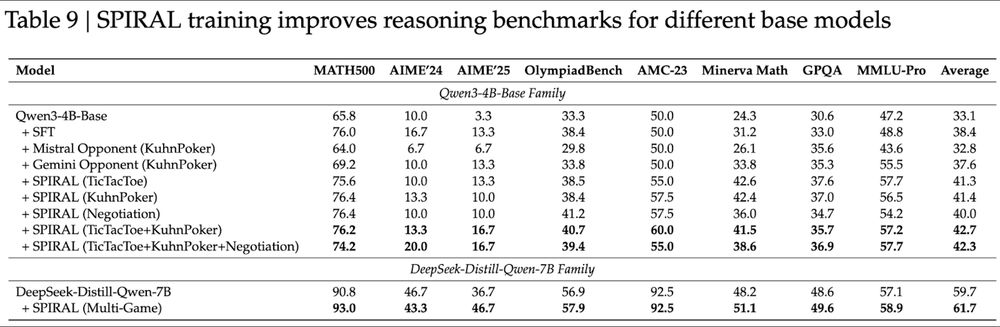
Multi-game magic:
Single game: ~41% reasoning average
Multi-game: 42.7% - skills synergize!
Even strong models improve:
DeepSeek-R1-Distill-Qwen-7B jumps 59.7%→61.7%. AIME'25 +10 points! 📈
01.07.2025 20:11 — 👍 2 🔁 0 💬 1 📌 0

Different games → different skills:
TicTacToe → spatial (56% on Snake)
Kuhn Poker → probabilistic (91.7% on Pig Dice!)
Simple Negotiation → strategic (55.8% on Truth & Deception)
Each game develops distinct abilities!
01.07.2025 20:11 — 👍 2 🔁 0 💬 1 📌 0
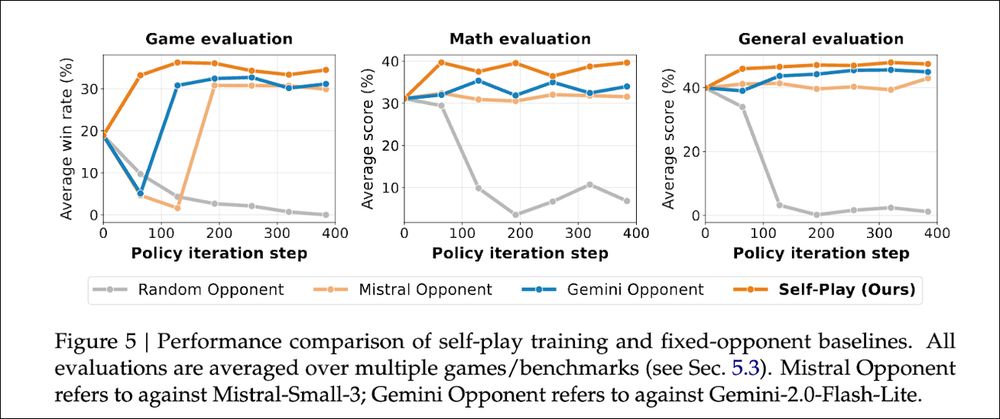
Why self-play? We compared approaches:
Self-play: 39.7% math, 47.8% general reasoning
Fixed opponents: Much worse
Random: Complete collapse
Key: as you improve, so does your opponent. Fixed opponents become too easy.
01.07.2025 20:11 — 👍 3 🔁 0 💬 1 📌 0
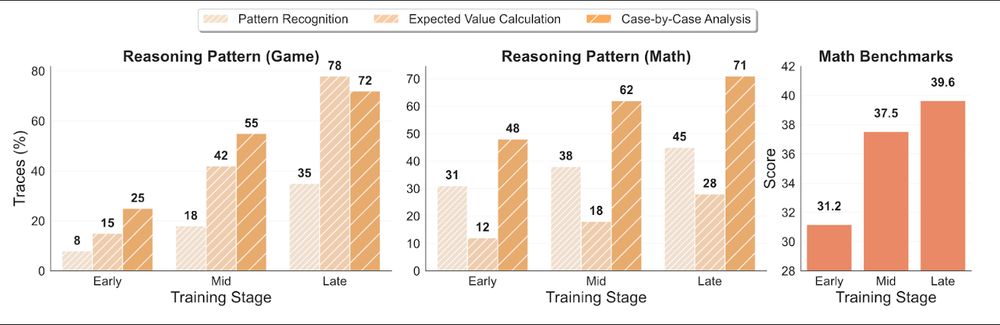
To understand poker→math transfer, we found 3 patterns:
📊 Expected Value Calculation
🔍 Case-by-Case Analysis
🎯 Pattern Recognition
These patterns from games transfer to math benchmarks. Games teach generalizable thinking!
01.07.2025 20:11 — 👍 2 🔁 0 💬 1 📌 1
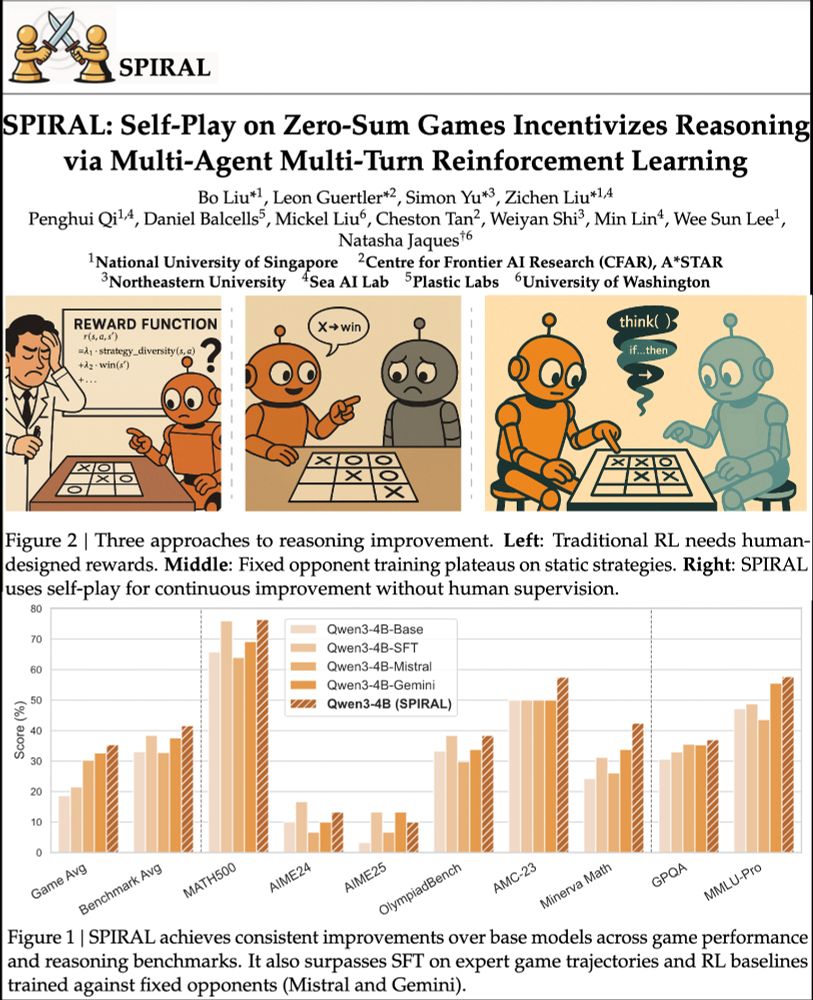
We're excited about self-play unlocking continuously improving agents. RL selects CoT patterns from LLMs. Games=perfect testing grounds.
SPIRAL: models learn via self-competition. Kuhn Poker → +8.7% math, +18.1 Minerva Math! 🃏
Paper: huggingface.co/papers/2506....
Code: github.com/spiral-rl/spiral
01.07.2025 20:11 — 👍 17 🔁 5 💬 2 📌 1
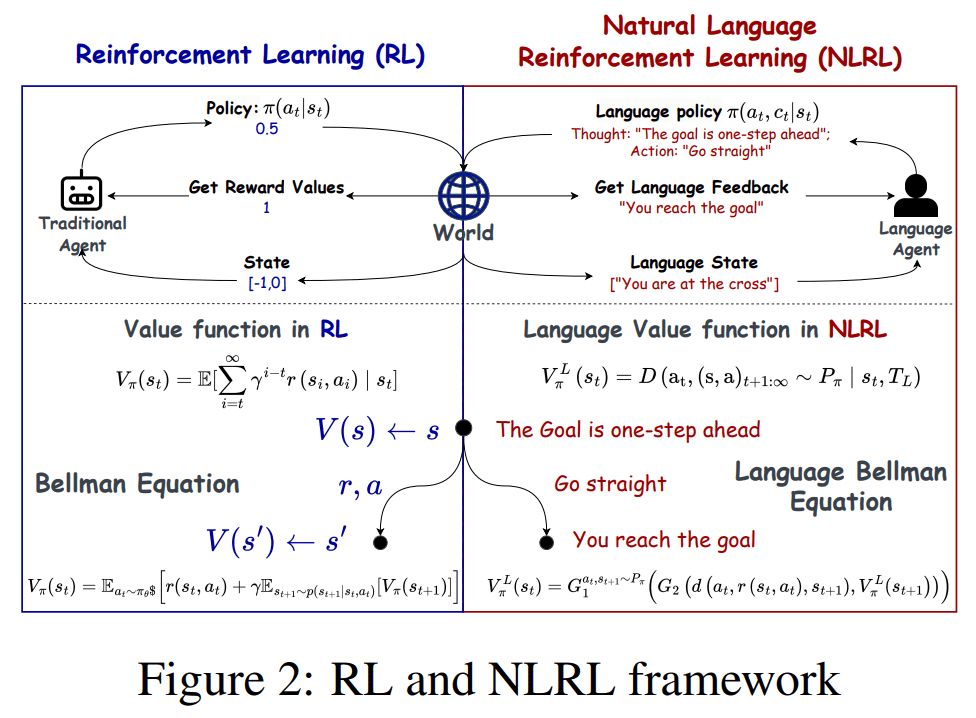
Natural Language Reinforcement Learning (NLRL) redefines Reinforcement Learning (RL).
NLRL's main idea:
The core parts of RL like goals, strategies, and evaluation methods are reimagined using natural language instead of rigid math.
Let's explore this approach more precisely🧵
29.11.2024 15:06 — 👍 2 🔁 1 💬 1 📌 1
Anti-cynic. Towards a weirder future. Reinforcement Learning, Autonomous Vehicles, transportation systems, the works. Asst. Prof at NYU
https://emerge-lab.github.io
https://www.admonymous.co/eugenevinitsky
Assistant Professor at UW and Staff Research Scientist at Google DeepMind. Social Reinforcement Learning in multi-agent and human-AI interactions. PhD from MIT. Check out https://socialrl.cs.washington.edu/ and https://natashajaques.ai/.
Compling PhD student @UT_Linguistics | prev. CS, Math, Comp. Cognitive Sci @cornell
Founder of the newsletter that explores AI & ML (https://www.turingpost.com)
- AI 101 series
- ML techniques
- AI Unicorns profiles
- Global dynamics
- ML History
- AI/ML Flashcards
Haven't decided yet which handle to maintain: this or @kseniase
Bot. I daily tweet progress towards machine learning and computer vision conference deadlines. Maintained by @chriswolfvision.bsky.social
Writing about robots https://itcanthink.substack.com/
RoboPapers podcast https://robopapers.substack.com/
All opinions my own
Information and updates about RLC 2026 at Montreal, Quebec, Canada, from August 16 to 19.
https://rl-conference.cc
Scientist @ DeepMind and Honorary Fellow @ U of Edinburgh.
RL, agency, philosophy, foundations, AI.
https://david-abel.github.io
Member of technical staff @periodiclabs
Open-source/open science advocate
Maintainer of torchrl / tensordict / leanrl
Former MD - Neuroscience PhD
https://github.com/vmoens
I can be described as a multi-agent artificial general intelligence.
www.jzleibo.com
Professor of Computer Science at Oxford. Senior Staff Research Scientist at Waymo.
AI professor at Caltech. General Chair ICLR 2025.
http://www.yisongyue.com
AI, RL, NLP, Games Asst Prof at UCSD
Research Scientist at Nvidia
Lab: http://pearls.ucsd.edu
Personal: prithvirajva.com
AI @ OpenAI, Tesla, Stanford
A LLN - large language Nathan - (RL, RLHF, society, robotics), athlete, yogi, chef
Writes http://interconnects.ai
At Ai2 via HuggingFace, Berkeley, and normal places
The Multi-disciplinary Conference on Reinforcement Learning and Decision Making.
11-14 June 2025.
Trinity College Dublin.
https://rldm.org/
Researcher in robotics and machine learning (Reinforcement Learning). Maintainer of Stable-Baselines (SB3).
https://araffin.github.io/
Research Scientist at Google DeepMind, interested in multiagent reinforcement learning, game theory, games, and search/planning.
Lover of Linux 🐧, coffee ☕, and retro gaming. Big fan of open-source. #gohabsgo 🇨🇦
For more info: https://linktr.ee/sharky6000



















