Instead of behavior cloning, what if you asked an LLM to write code to describe how an agent was acting, and used this to predict their future behavior?
Our new paper "Modeling Others' Minds as Code" shows this outperforms BC by 2x, and reaches human-level performance in predicting human behavior.
03.10.2025 19:01 — 👍 13 🔁 2 💬 0 📌 0
My husband presenting his work on caregiving 😍
01.08.2025 00:03 — 👍 12 🔁 0 💬 0 📌 0
By optimizing for intrinsic curiosity, the LLM learns how to ask a series of questions over the course of the conversation to improve the accuracy of its user model. This generates conversations which reveal significantly more information about the user.
08.07.2025 23:06 — 👍 4 🔁 0 💬 0 📌 0
Excited to release our latest paper on a new multi-turn RL objective for training LLMs to *learn how to learn* to adapt to the user. This enables it to adapt and personalize to novel users, whereas the multi-turn RLHF baseline fails to generalize effectively to new users.
08.07.2025 23:05 — 👍 12 🔁 3 💬 2 📌 0
This work shows the benefit of RL training for improving reasoning skills when there is no possibility for data leakage. AND how continuously evolving multi-agent competition leads to the development of emergent skills that generalize to novel tasks.
01.07.2025 20:24 — 👍 9 🔁 0 💬 0 📌 0
We analyze the results and find that LLMs learn emergent reasoning patterns like case-by-case analysis and expected value calculation that transfer to improve performance on math questions.
01.07.2025 20:24 — 👍 7 🔁 0 💬 1 📌 0
In our latest paper, we discovered a surprising result: training LLMs with self-play reinforcement learning on zero-sum games (like poker) significantly improves performance on math and reasoning benchmarks, zero-shot. Whaaat? How does this work?
01.07.2025 20:23 — 👍 59 🔁 7 💬 2 📌 2
Just posted a talk I gave about this work! youtu.be/mxWJ9k2XKbk
12.06.2025 17:08 — 👍 11 🔁 1 💬 0 📌 1
RLHF is the main technique for ensuring LLM safety, but it provides no guarantees that they won’t say something harmful.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
12.06.2025 17:07 — 👍 16 🔁 3 💬 1 📌 1
RLHF is the main technique for ensuring LLM safety, but it provides no guarantees that they won’t say something harmful.
Instead, we use online adversarial training to achieve theoretical safety guarantees and substantial empirical safety improvements over RLHF, without sacrificing capabilities.
12.06.2025 17:07 — 👍 16 🔁 3 💬 1 📌 1
Oral @icmlconf.bsky.social !!! Can't wait to share our work and hear the community's thoughts on it, should be a fun talk!
Can't thank my collaborators enough: @cogscikid.bsky.social y.social @liangyanchenggg @simon-du.bsky.social @maxkw.bsky.social @natashajaques.bsky.social
09.06.2025 16:32 — 👍 9 🔁 2 💬 0 📌 0
RLDM2025SocInfWorkshop
// RLDM 2025 Workshop \\
Reinforcement learning as a model of social behaviour and inference: progress and pitfalls
12.06.2025 // 9am-1pm
At @rldmdublin2025.bsky.social this week? Check out our social learning workshop from @amritalamba.bsky.social and I tomorrow! Inc. talks from @natashajaques.bsky.social, @nitalon.bsky.social, @carocharp.bsky.social, @kartikchandra.bsky.social & more!
Full schedule: sites.google.com/view/rldm202...
11.06.2025 06:49 — 👍 17 🔁 8 💬 2 📌 1
Way to go KJ for producing such an insightful paper in the first few months of your PhD!
19.04.2025 05:03 — 👍 2 🔁 0 💬 0 📌 0
Human-AI cooperation is important, but existing work trains on the same 5 Overcooked layouts, creating brittle strategies.
Instead, we find that training on billions of procedurally generated tasks trains agents to learn general cooperative norms that transfer to humans... like avoiding collision
19.04.2025 05:02 — 👍 17 🔁 4 💬 1 📌 0
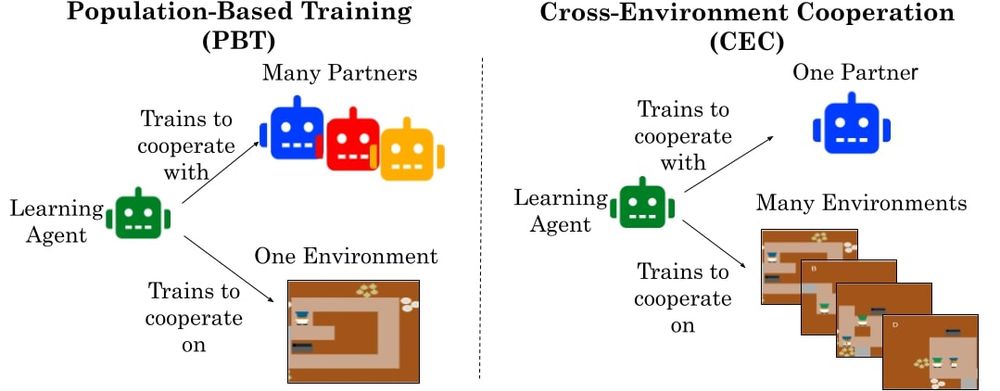
Our new paper (first one of my PhD!) on cooperative AI reveals a surprising insight: Environment Diversity > Partner Diversity.
Agents trained in self-play across many environments learn cooperative norms that transfer to humans on novel tasks.
shorturl.at/fqsNN%F0%9F%...
19.04.2025 00:06 — 👍 25 🔁 7 💬 1 📌 5

Got a weird combination of mail today.
12.04.2025 17:04 — 👍 8 🔁 0 💬 0 📌 0
I had a ton of fun using this as a kid. I actually made my high school English class project a giant hypercard-based video game where I drew each frame in Paint and hid buttons behind the hand-drawn elements that let you navigate the world. That was so fun...😍
28.03.2025 19:57 — 👍 2 🔁 0 💬 0 📌 0
YouTube video by Natasha Jaques
Reinforcement Learning (RL) for LLMs
Recorded a recent "talk" / rant about RL fine-tuning of LLMs for a guest lecture in Stanford CSE234: youtube.com/watch?v=NTSY.... Covers some of my lab's recent work on personalized RLHF, as well as some mild Schmidhubering about my own early contributions to this space
27.03.2025 21:31 — 👍 51 🔁 10 💬 5 📌 1
next Canadian government should think of boosting research funding up here and trying to grab as many American postdocs and researchers as possible
12.03.2025 13:08 — 👍 16654 🔁 2185 💬 619 📌 183
Yes! Or you could focus on developing better MARL algorithms for the corporations that let them cooperate to solve the social dilemma more effectively. Similar to MARL benchmarks like Melting Pot but for a more impactful domain
16.02.2025 23:27 — 👍 1 🔁 0 💬 0 📌 0
AI has shown great potential in boosting efficiency. But can it help human society make better decisions as a whole? 🤔 In this project, using MARL, we explore this by studying the impact of an ESG disclosure mandate—a highly controversial policy. (1/6)
13.02.2025 06:24 — 👍 2 🔁 1 💬 1 📌 0
In contrast, MARL enables testing new policies with many more agents over a long time horizon.
We hope this benchmark will enable researchers in the RL and MARL communities to develop sophisticated cooperation algorithms in the context of a societally impactful problem!
13.02.2025 06:42 — 👍 4 🔁 0 💬 0 📌 0
I’m really excited about this, as I think MARL provides a new tool in the toolbox for investigating this problem. Existing work on ESG disclosures focuses on empirical studies (can’t test counterfactual policies), or analytical economics models (limited to 2 players or short time intervals)
13.02.2025 06:41 — 👍 4 🔁 1 💬 1 📌 0
...providing corporations with more reliable information about climate risks — and we show that this significantly improves corporations’ ability to mitigate climate change, even without the influence of investors!
13.02.2025 06:39 — 👍 3 🔁 0 💬 1 📌 0
The parameters of the environment are carefully benchmarked to real-world data (e.g. from IPCC reports), and many of our experiments reveal findings consistent with empirical work on climate change and ESG disclosures. But we can also test new policy interventions, such as..
13.02.2025 06:39 — 👍 3 🔁 0 💬 1 📌 0
overall climate risks increase, leading to lower market wealth. By introducing climate-conscious investor agents to simulate the possible effects of ESG disclosures, we show that investors can actually incentivize profit-motivated companies to invest in climate mitigation.
13.02.2025 06:38 — 👍 4 🔁 1 💬 1 📌 0
Our latest work uses multi-agent reinforcement learning to model corporate investment in climate change mitigation as a social dilemma. We create a new benchmark, and show that corporations are greedily motivated to pollute without mitigating their emissions, but if all companies defect...
13.02.2025 06:38 — 👍 35 🔁 5 💬 2 📌 0
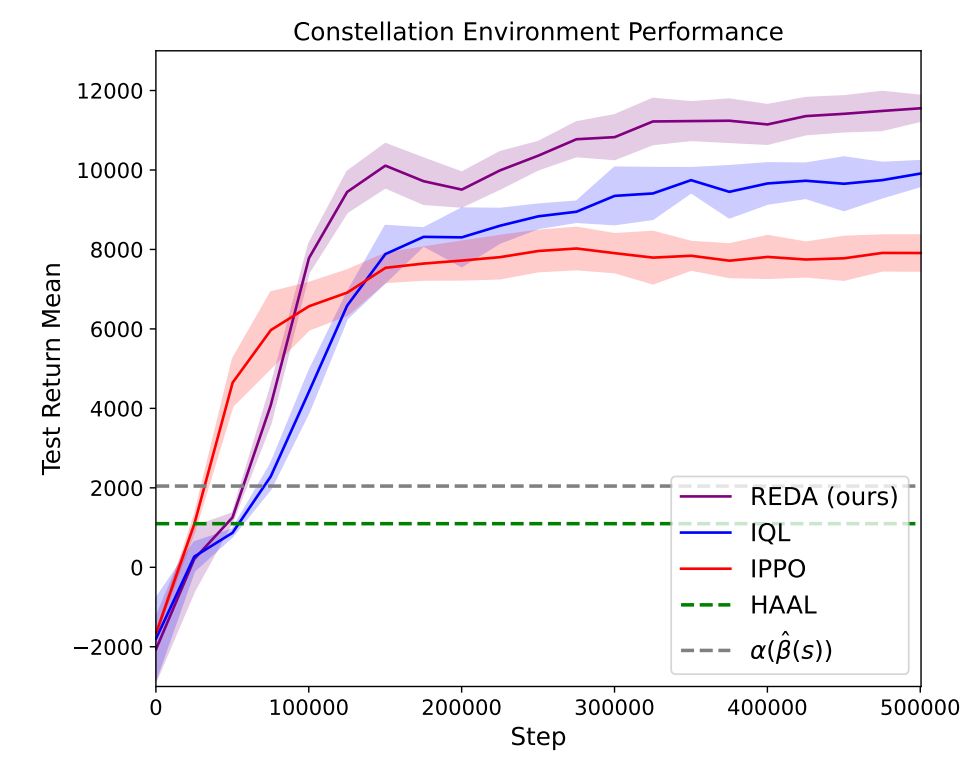
Impressive results that strongly outperform the best classical techniques. Several MARL methods work well, showing the promise of MARL for combinatorial optimization and systems problems, as in our earlier work on MARL for Microprocessor Design arxiv.org/abs/2211.16385 3/3
02.01.2025 22:33 — 👍 12 🔁 0 💬 0 📌 0
The classical solver can give an optimal, conflict-free assignment for a single timestep if it's given known utility values, but can't plan assignments over time. So, we learn the future estimated payoff for each single-timestep assignment using RL! 2/3
02.01.2025 22:32 — 👍 12 🔁 1 💬 1 📌 0
The Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University.
Reinforcement Learning PhD @NUSingapore | Undergrad @PKU1898 | Building autonomous decision making systems | Ex intern @MSFTResearch @deepseek_ai | DeepSeek-V2, DeepSeek-VL, DeepSeek-Prover
PhD student @ UWCSE/UWNLP · Incoming @ Meta FAIR · I do LLM + RL
Assistant Professor, MIT | Co-founder & Chair, Climate Change AI | MIT TR35, TIME100 AI | she/they
Full Time: Prof @ University of Washington
Intrusion, Inclusion, and Dilution FTW
Machine Learning, {Org, Med, Comp} Chem, RL/Planning, AI-assisted Scientific Discovery & Creativity, Music. ELLIS Scholar. Team Lead at Microsoft Research AI for Science. 2xDad
Guitarist, Researcher Google DeepMind. Opinions are my own.
Machine learning researcher
@Google DeepMind. My opinions do not necessarily represent my employer. Prefer email over DMs.
https://scholar.google.com/citations?hl=e&user=ghbWy-0AAAAJ
https://www.cs.toronto.edu/~gdahl/
Research director @Inria, Head of @flowersInria
lab, prev. @MSFTResearch @SonyCSLParis
Artificial intelligence, cognitive sciences, sciences of curiosity, language, self-organization, autotelic agents, education, AI and society
http://www.pyoudeyer.com
Improving Reinforcement Learning with language interaction and humans in the loop.
PhD in Artificial Intelligence, University of Manchester (UK)
Founder of elsci.org
tech veteran turned ml researcher @uw | prev @Amazon AGI & @CarnegieMellon | My code and myself, at least one of them should be running.
ML, Gen AI, Expressive Technologies, and Games! @Google sites.google.com/view/sherol
Director, MIT Computational Psycholinguistics Lab. President, Cognitive Science Society. Chair of the MIT Faculty. Open access & open science advocate. He.
Lab webpage: http://cpl.mit.edu/
Personal webpage: https://www.mit.edu/~rplevy
San Diego Dec 2-7, 25 and Mexico City Nov 30-Dec 5, 25. Comments to this account are not monitored. Please send feedback to townhall@neurips.cc.
Masters Student who ❤️ 🤖 @ UW! I’m Member of Weird Lab
Bringing the sergey posts until he does it himself.
Robotics. Reinforcement learning. AI.
CEO & co-founder @far.ai non-profit | PhD from Berkeley | Alignment & robustness
Professor of Psychology & Human Values at Princeton | Cognitive scientist curious about technology, narratives, & epistemic (in)justice | They/She 🏳️🌈
www.crockettlab.org
Co-Founder & CEO, Sakana AI 🎏 → @sakanaai.bsky.social
https://sakana.ai/careers





















