Published: the paper 'On the uses and abuses of Regression Models: a Call for Reform of Statistical Practice and Teaching' by John Carlin and Margarita Moreno-Betancur in the latest issue of Statistics in Medicine onlinelibrary.wiley.com/doi/10.1002/... (1/8)
26.06.2025 12:23 — 👍 47 🔁 16 💬 3 📌 1

Should Graphs of Risk or Rate Ratios be Plotted on a Log Scale?
Should graphs of risk or rate ratios be plotted on a logarithmic scale? The conventional answer to this question seems to be yes (1), even to the extent th
Nice Simpsons reference, but symmetry is misleading. Consider this analogy: If you invest $100 in the stock market, you cannot lose more than 100% relative to that amount, but you can gain more than 100%. Additional reasons for leaving as ratios in link.
academic.oup.com/aje/article-...
21.06.2025 01:38 — 👍 1 🔁 0 💬 1 📌 0
Can’t imagine how random nonpositivity would be illustrated on a DAG. Could deterministic nonpositivity be illustrated similar to selection?
10.06.2025 20:35 — 👍 1 🔁 0 💬 1 📌 0
We must hold AI tools to the same standards as any other clinical intervention. Strong evidence builds trust and supports responsible adoption.
3/3
06.05.2025 14:12 — 👍 0 🔁 0 💬 0 📌 0
Hope and hype are not substitutes for evidence.
Nevertheless, healthcare AI tools are often promoted without the rigorous evaluation expected of other healthcare interventions. Understanding the benefits and harms is essential before deploying these tools at scale.
#Healthcare #AI
1/3
06.05.2025 14:12 — 👍 2 🔁 0 💬 1 📌 0

"People Profit from being ambiguous about their research goals"
Julia concludes by highlighting the need for structural change. Rigorous causal research takes time and thought. That's not possible if we're still expecting PhD students to publish 3-5 papers.
10.04.2025 15:21 — 👍 3 🔁 2 💬 1 📌 0

You know Pearl's causal ladder, but Julia introduced a different type of ladder : how can we get cutting edge causal inference methods into applications? #EuroCIM2025 so important!
10.04.2025 15:06 — 👍 13 🔁 3 💬 1 📌 0
This 'dataset first' approach leads some scientists to conduct weak research because 'this is the best we can do in our data'.
If a dataset is inappropriate for a particular question, the best you can do is NOT use it.
It shouldn't be our job, as scientists, to be showcasing datasets.
31.03.2025 12:18 — 👍 12 🔁 1 💬 1 📌 0

NEW PAPER in the @bmj.com "PROBAST+AI: an updated quality, risk of bias, and applicability assessment tool for prediction models using regression or #artificialintelligence methods"
www.bmj.com/content/388/...
#StatsSky #MLSky #AI #MethodologyMatters
24.03.2025 11:52 — 👍 28 🔁 11 💬 1 📌 1

The Unbelievable Scale of AI’s Pirated-Books Problem
Meta pirated millions of books to train its AI. Search through them here.
NEW: LibGen contains millions of pirated books and research papers, built over nearly two decades. From court documents, we know that Meta torrented a version of it to build its AI. Today, @theatlantic.com presents an analysis of the data set by @alexreisner.bsky.social. Search through it yourself:
20.03.2025 11:38 — 👍 1519 🔁 857 💬 64 📌 561
Best wishes for a rapid and full recovery.
06.03.2025 17:39 — 👍 3 🔁 0 💬 0 📌 0

OpenAI plans to charge $20,000 per month for a PhD-level AI research agent.
To organizations considering this option from OpenAI: Why not hire a human PhD-level researcher instead?
To PhD-level researchers: Here is our fair market value according to OpenAI.
#EpiSky #StatsSky #AcademicSky
05.03.2025 18:04 — 👍 28 🔁 14 💬 4 📌 3
Interesting situation. Perhaps the journal or Editorial Board has a policy to help guide?
25.02.2025 23:58 — 👍 0 🔁 0 💬 0 📌 0

1/ When using observational data for #causalinference, emulating a target trial helps solve some problems... but not all problems.
In a new paper, we explain why and when the #TargetTrial framework is helpful.
www.acpjournals.org/doi/10.7326/...
Joint work with my colleagues @causalab.bsky.social
18.02.2025 13:08 — 👍 48 🔁 12 💬 3 📌 0
Just like the phrase, “…results should be interpreted cautiously.” As if results should ever be interpreted recklessly.
14.02.2025 21:50 — 👍 2 🔁 0 💬 0 📌 0
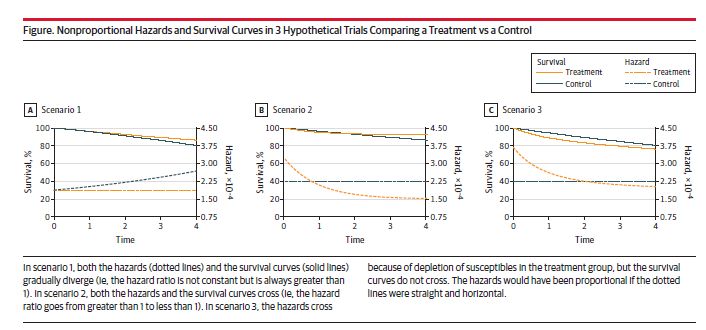
1/
If you were taught to test for proportional hazards, talk to your teacher.
The proportional hazards assumption is implausible in most #randomized and #observational studies because the hazard ratios aren't expected to be constant during the follow-up. So "testing" is futile.
But there is more 👇
03.02.2025 14:51 — 👍 80 🔁 19 💬 4 📌 1

NEW PAPER
Really glad to see this one in print: the harm due to class imbalance corrections in prediction models developed using ML/AI
Excellently led by @alcarriero.bsky.social
onlinelibrary.wiley.com/doi/epdf/10....
27.01.2025 08:01 — 👍 45 🔁 10 💬 0 📌 0

You aren't allowed to say “risk factor”
People often say their goal is to identify “risk factors”. But what does that mean? Some people use the term to indicate potential causes of outcomes. Then just say cause. Others use it to identify predictors of outcomes. Then just say predict. And, sadly, too many others use it as shorthand for factors that are “statistically associated” with outcomes. In this case, say nothing at all, since this “goal” has no clinical utility whatsoever (beyond what it might suggest about causation or prediction). So once you have framed your research question as description, prediction, causation or measurement, there is no longer a need to talk about risk factors. It's basically just a catch-all phrase to cover up muddy thinking.
Please stop telling me about risk factors. 🙏😖
(ICYMI)
statsepi.substack.com/p/sorry-what...
20.01.2025 07:27 — 👍 116 🔁 32 💬 9 📌 6
I’m with you and advocate for further inquiry. I also agree that inference requires multiple sources, but the question is whether some studies are even useful for informing policy? Savitz wrote a nice article about the need for policy-relevant research.
academic.oup.com/aje/article/...
09.01.2025 17:43 — 👍 1 🔁 0 💬 2 📌 0
Sometimes the available studies are so flawed or do not address the question of interest well enough that meta-analysis is unwarranted and no amount of sensitivity analysis or post hoc remedies can redeem. In such cases, greater value to provide guidance about how to improve the quality of studies.
09.01.2025 12:37 — 👍 1 🔁 0 💬 1 📌 0

Eliminating Ambiguous Treatment Effects Using Estimands
Abstract. Most reported treatment effects in medical research studies are ambiguously defined, which can lead to misinterpretation of study results. This i
What effect is being estimated? Clarifying this question can help decision-makers better use the evidence. Recent developments in defining estimands (i.e., the effect of interest) can help.
Here’s a nice summary to help think about estimands:
academic.oup.com/aje/article/...
#EpiSky #CausalSky
02.01.2025 15:18 — 👍 2 🔁 1 💬 2 📌 2
Agree. Such analyses are conditional on knowing when the outcome (mortality) occurred and have little practical value for informing practice change. We cannot intervene after the outcome already occurred.
30.12.2024 15:50 — 👍 1 🔁 0 💬 0 📌 0
LLMs may be good for certain tasks, but encoding causal knowledge is not one of them.
18.12.2024 02:24 — 👍 4 🔁 0 💬 0 📌 0
Many measures used in evaluating AI prediction models do not measure the intended parameter. AUC, calibration plot, and decision curve analysis are recommended for evaluation.
16.12.2024 14:31 — 👍 1 🔁 0 💬 0 📌 0
No problem. Another consideration is that two things that seemingly occur simultaneously may be related to a known or unknown common cause rather than a bidirectional effect. You’re thus searching for a common cause or some time-varying effect. DAGs can encode either and help clarify assumptions.
16.12.2024 01:48 — 👍 2 🔁 0 💬 1 📌 0
Professor of Biostatistics. University of Melbourne & Murdoch Children’s Research Institute. Research in causal inference and missing data methods + child, lifecourse and social epidemiology
In charge of big tech coverage at Bloomberg
Author of NO FILTER: The Inside Story of Instagram
Email me at sfrier1 at Bloomberg dot net
President and CEO of @kff.org; Executive Publisher of @kffhealthnews.org
Freelance science journalist contributing to NYT, SciAm, Nature etc. Author of "Poached: Inside the Dark World of Wildlife Trafficking" (2018) and "I Feel Love: MDMA and the Quest for Connection in a Fractured World" (2023).
AStatA science policy: raising the profile of statistics in policymaking and advocating on interests of statisticians. Posts by Steve Pierson
Epidemiologist studying malnutrition and infectious disease. Program Director for PhD in Epidemiology & Translational Science at UCSF. Dog mom.
Statistician. Associate prof. at NYU Grossman Department of Population Health. Causal inference, machine learning, and semiparametric estimation.
https://idiazst.github.io/website/
Assistant Professor of Biostatistics at Columbia.
I study causal inference, graphical models, machine learning, algorithmic (un)fairness, social + environmental determinants of health, etc. Opinions my own.
http://www.dmalinsky.com
Epidemiologist at Bennett Institue for Applied Data Science, Nuffield Department of Primary Care Health Sciences, University of Oxford https://www.bennett.ox.ac.uk/
I use mathematics, computation, statistics, & machine learning to help think about biology, engineering, & other things. University of Auckland, NZ. Research: http://tinyurl.com/ojmscholar, Teaching: https://tinyurl.com/ojmteaching
Health policy, especially for stigmatized populations. Chief of health policy and econ at Weill Cornell and founding director of the Cornell Health Policy Center (CHPC).
Chair, Department of Computational Biomedicine at Cedars-Sinai Medical Center in Los Angeles. Director, Center for Artificial Intelligence Research & Education. Atari enthusiast. Retrocomputing. Maker.
Cancer epidemiologist | cancer survivorship
Training at the NCI, Johns Hopkins, Harvard
Psychiatry, Genetics, Epidemiology, Precision Medicine. Author of The Other Side of Normal. 3% Neanderthal.
Health systems researcher focused on health equity and collaborative equity.
Epidemiology @Aarhus & @Karolinska
Professor@ Albany College and Health Sciences| PHARMD, BCGP, FASCP, FNAP| RPD PGY2 Geriatrics| JGN Section Editor: Geropharm
BEMC is a platform for all interested in epidemiology to explore methods and share ideas in regular talks and journal club sessions
Our events are hybrid and open to epi methods enthusiasts around the world!
More info: https://bemcolloquium.com
#EpiSky