
Highly recommend @yabramuvdi.bsky.social new Substack on Large Language Models (in Spanish) substack.com/@yabramuvdi. I have learned so much working with Yabra over the years, and I think you will too!
22.03.2025 15:09 — 👍 1 🔁 0 💬 0 📌 0
@stephenekhansen.bsky.social
Highly recommend @yabramuvdi.bsky.social new Substack on Large Language Models (in Spanish) substack.com/@yabramuvdi. I have learned so much working with Yabra over the years, and I think you will too!
22.03.2025 15:09 — 👍 1 🔁 0 💬 0 📌 0
More generally, establishing procedures for valid inference in the growing world of AI-generated indicators is a major future challenge.
arxiv.org/abs/2402.15585
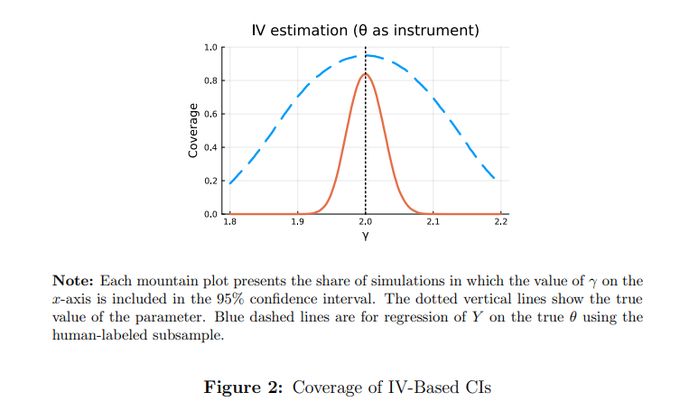
We also show that an IV strategy that uses a human-labeled sample to purge the measurement error in generated variables works poorly when the number of labels is small relative to the unlabeled data.
12.12.2024 10:44 — 👍 0 🔁 0 💬 1 📌 0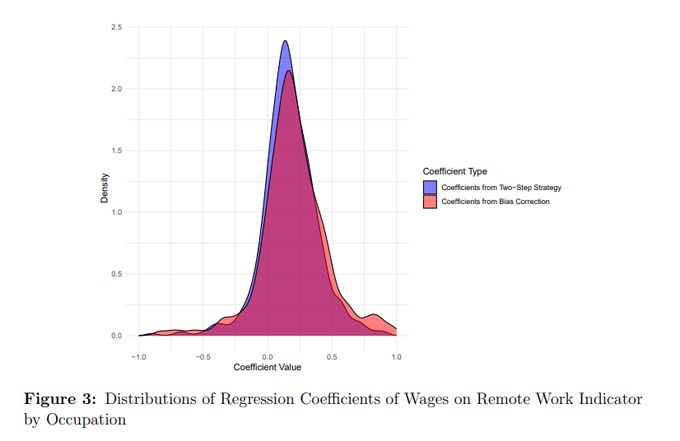
We provide an illustration of how bias correction increases the estimated impact of remote work on wages across occupations.
12.12.2024 10:44 — 👍 0 🔁 0 💬 1 📌 0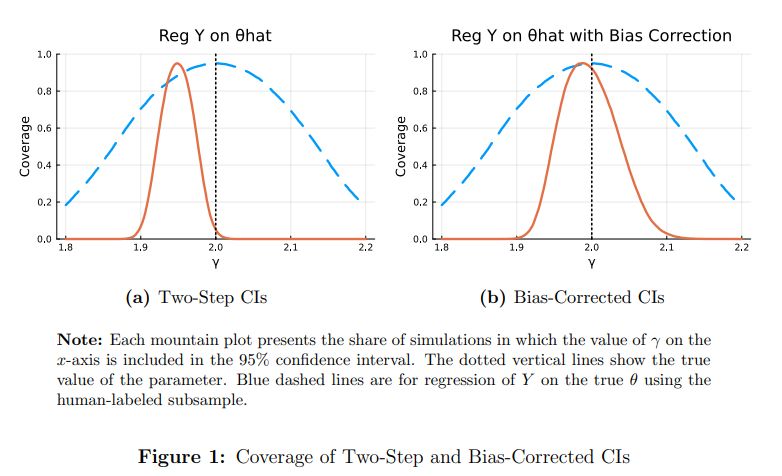
We provide a simple bias correction formula that applied researchers can easily use. This restores valid inference and has quantitatively important effects even when AI/LLM are extremely accurate.
12.12.2024 10:44 — 👍 0 🔁 0 💬 1 📌 0We consider the realistic case where algorithms become more precise as the sample size increases. In this setting, **point estimates are biased** but **standard errors are correct**.
This is the opposite of the typical generated regressor problem.
Suppose we treat an AI-generated variable as "data" in a regression model.
One intuition is that measurement error biases coefficient estimates. Another is that ignoring uncertainty biases standard errors. Which is it?
📢 **new results**
LLMs and AI can be used to extract measures from text like sentiment, beliefs, and uncertainty.
What can go wrong when plugging these measures into regressions and how to fix the problem?
Read more below and check out arxiv.org/abs/2402.15585 for details
#EconSky
Oh no, my cover is blown!
j/k, thank you Fatih. Hoping this new place has more econ/ML content and fewer Joe Rogan clips.



















