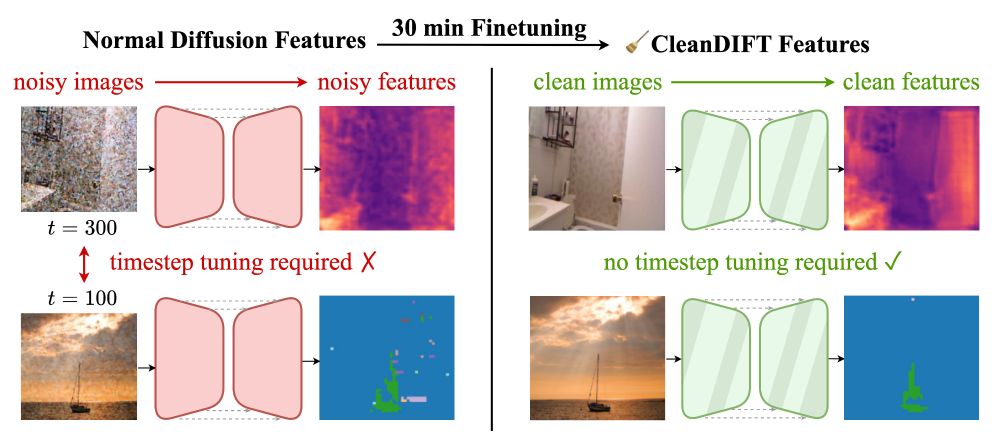
CleanDIFT: Diffusion Features without Noise
CleanDIFT enables extracting Noise-Free, Timestep-Independent Diffusion Features
🧹 CleanDiFT: Diffusion Features without Noise
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
09.06.2025 07:58 — 👍 8 🔁 3 💬 1 📌 0
Our paper is accepted at WACV 2025! 🤗
Check out DistillDIFT. Code & weights are now public:
👉 github.com/compvis/dist...
06.12.2024 14:35 — 👍 1 🔁 0 💬 0 📌 0

🔥 We achieve SOTA in unsupervised & weakly-supervised semantic correspondence at just a fraction of the computational cost.
06.12.2024 14:35 — 👍 1 🔁 0 💬 1 📌 0

✨ By training just a tiny LoRA adapter, we transfer the power of a large diffusion model (SDXL Turbo) into a small ViT (DINOv2).
🔄 All done unsupervised by retrieving pairs of similar images.
06.12.2024 14:35 — 👍 1 🔁 0 💬 1 📌 0
🚀 Meet DistillDIFT:
It distills the power of two vision foundation models into one streamlined model, achieving SOTA performance at a fraction of the computational cost.
No need for bulky generative combos—just pure efficiency. 💡
06.12.2024 14:35 — 👍 1 🔁 0 💬 1 📌 0
This work was co-lead by: @joh-schb.bsky.social @vtaohu.bsky.social
📷Project Page: compvis.github.io/distilldift
💻Code: github.com/compvis/dist...
📝 Paper: arxiv.org/abs/2412.03512
👇
06.12.2024 14:35 — 👍 1 🔁 0 💬 1 📌 0
Did you know you can distill the capabilities of a large diffusion model into a small ViT? ⚗️
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
06.12.2024 14:35 — 👍 4 🔁 2 💬 1 📌 2
Our paper is accepted at WACV 2025! 🤗
Check out DistillDIFT. Code & weights are now public:
👉 github.com/compvis/dist...
06.12.2024 12:23 — 👍 1 🔁 0 💬 0 📌 0

🔥 We achieve SOTA in unsupervised & weakly-supervised semantic correspondence at just a fraction of the computational cost.
06.12.2024 12:23 — 👍 0 🔁 0 💬 1 📌 0

✨ By training just a tiny LoRA adapter, we transfer the power of a large diffusion model (SDXL Turbo) into a small ViT (DINOv2).
🔄 All done unsupervised by retrieving pairs of similar images.
06.12.2024 12:23 — 👍 0 🔁 0 💬 1 📌 0
🚀 Meet DistillDIFT:
It distills the power of two vision foundation models into one streamlined model, achieving SOTA performance at a fraction of the computational cost.
No need for bulky generative combos—just pure efficiency. 💡
06.12.2024 12:23 — 👍 0 🔁 0 💬 1 📌 0
📷Project Page: compvis.github.io/distilldift
💻Code: github.com/compvis/dist...
📝 Paper: arxiv.org/abs/2412.03512
👇
06.12.2024 12:23 — 👍 0 🔁 0 💬 1 📌 0
https://code4conservation.de/
PhD Student at Ommer Lab, Munich (Stable Diffusion)
🎯 Working on getting my first 3M.
PhD Student for Unsupervised Segmentation & Representation Learning @ Ulm University 👁️👨💻
https://leonsick.github.io
Student Researcher @ RAI Institute, MSc CS Student @ ETH Zurich
visual computing, 3D vision, spatial AI, machine learning, robot perception.
📍Zurich, Switzerland
PhD Student at @compvis.bsky.social & @ellis.eu working on generative computer vision.
Interested in extracting world understanding from models and more controlled generation. 🌐 https://stefan-baumann.eu/
PhD Student @ CompVis group, LMU Munich
Working on diffusion & flow models🫶
Computer Vision and Learning research group @ LMU Munich, headed by Björn Ommer.
Generative Vision (Stable Diffusion, VQGAN) & Representation Learning
🌐 https://ommer-lab.com
official Bluesky account (check username👆)
Bugs, feature requests, feedback: support@bsky.app








