Thanks, my dear investor!
18.10.2025 08:42 — 👍 0 🔁 0 💬 0 📌 0
Huge thanks to all my great collaborators, @mgui7.bsky.social, @joh-schb.bsky.social , Xiaopei Yang, Yusong Li, Felix Krause, Olga Grebenkova, @vtaohu.bsky.social, and Björn Ommer at @compvis.bsky.social.
18.10.2025 03:00 — 👍 2 🔁 0 💬 0 📌 0
I am excited to connect or catch up in person at #ICCV2025. I am also seeking full-time or internship opportunities 🧑🏻💻 starting June 2026.
18.10.2025 03:00 — 👍 2 🔁 0 💬 1 📌 0

2️⃣ ArtFM: Stochastic Interpolants for Revealing Stylistic Flows across the History of Art 🎨
TL;DR: Modeling how artistic style evolves over 500 years without relying on ground-truth pairs.
📍 Poster Session 2
🗓️ Tue, Oct 21 — 3:00 PM
🧾 Poster #80
🔗 compvis.github.io/Art-fm/
18.10.2025 03:00 — 👍 1 🔁 0 💬 1 📌 0

1️⃣ SCFlow: Implicitly Learning Style and Content Disentanglement with Flow Models 🔄
TL;DR: We learn disentangled representations implicitly by training only on merging them.
📍 Poster Session 4
🗓️ Wed, Oct 22 — 2:30 PM
🧾 Poster #3
🔗 compvis.github.io/SCFlow/
18.10.2025 03:00 — 👍 1 🔁 0 💬 1 📌 1
I’m thrilled to share that I’ll present two first-authored papers at #ICCV2025 🌺 in Honolulu together with @mgui7.bsky.social ! 🏝️
(Thread 🧵👇)
18.10.2025 03:00 — 👍 5 🔁 3 💬 1 📌 1

🤔 What happens when you poke a scene — and your model has to predict how the world moves in response?
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
15.10.2025 01:56 — 👍 23 🔁 8 💬 1 📌 1
Jokes aside, I understand the submission load is massive, but shifting the burden of filtering invalid or duplicate entries onto reviewers isn’t a good incentive. It is 2025, and simple automated checks should be easy to employ, help the process, and respect reviewers’ time.
04.08.2025 14:51 — 👍 1 🔁 0 💬 0 📌 0
I just wrapped up my bidding process for AAAI 26, which is always an enjoyable experience. This year, I came across submissions titled things like “000ASD”, “testy”, “123321241”, and even cases with identical titles and abstracts but different submission numbers.
04.08.2025 14:51 — 👍 1 🔁 0 💬 1 📌 0
this sounded way to intimate
04.08.2025 14:45 — 👍 1 🔁 0 💬 0 📌 0

Our work received an invited talk at the Imageomics-AAAI-25 workshop of #AAAI25. @vtaohu.bsky.social will be representing us there. Without me being there, I still would like to share our poster with you :D
We also have another oral presentation for DepthFM on March 1, 2:30 pm-3:45 pm.
28.02.2025 17:03 — 👍 3 🔁 1 💬 0 📌 0
(reference source in the Alt text of the figures due to character limit)
08.01.2025 16:07 — 👍 0 🔁 0 💬 0 📌 0

Interestingly, LLM-assigned descriptions behave similarly indistinctively as randomly assigned descriptions.

We also achieve competitive results in the conventional eval setting.
🚀 We introduced a training-free approach to select small yet meaningful neighborhoods of discriminative descriptions that improve classification accuracy. We validated our findings across seven datasets, showing consistent gains without distorting the underlying VLM embedding space.
08.01.2025 15:54 — 👍 0 🔁 0 💬 1 📌 0

Interestingly, LLM-assigned descriptions behave similarly indistinctively as randomly assigned descriptions in this case.
🤔 To check out what happened, we proposed a new evaluation scenario to isolate the semantic impact by eliminating noise augmentation, ensuring only meaningful descriptions are useful. Random strings and unrelated texts degrade performance, while our assigned descriptions show clear advantages.
08.01.2025 15:54 — 👍 0 🔁 0 💬 1 📌 0

random string or unrelated text can have a similar effect, source: arxiv.org/abs/2306.07282
🤯 However, another recent study showed that descriptions augmented by unrelated text or noise could achieve similar performances. This raises the question: Does genuine semantics drive this gain, or is it an ensembling effect (similar to Multi-Crop test-time augmentation in the vision case)?
08.01.2025 15:54 — 👍 0 🔁 0 💬 1 📌 0
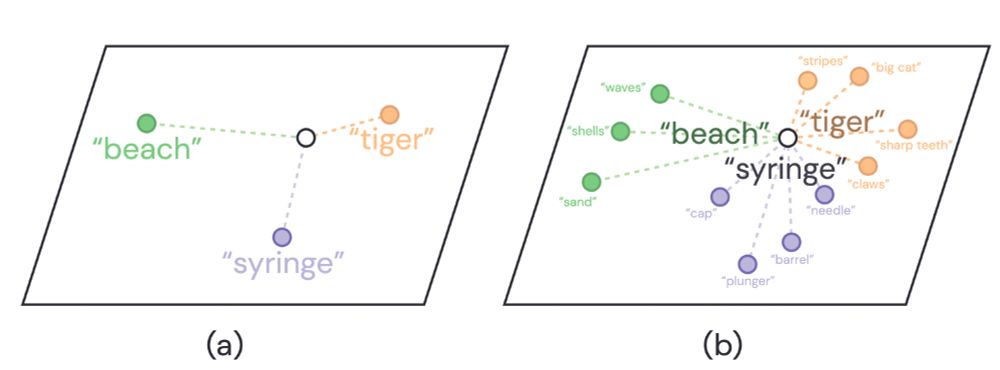
prompting LLMs for additional descriptions, source: arxiv.org/abs/2210.07183
Studies have shown that VLMs performance can be boosted by prompting LLMs for more detailed descriptions. Then use these descriptions to augment the original classname during inference, such as “tiger, a big cat; with sharp teeth” instead of simply “tiger”.
08.01.2025 15:54 — 👍 0 🔁 0 💬 1 📌 0
This work was co-led by x.com/LennartRietdorf, and collaborated with Dmytro Kotovenko, @vtaohu.bsky.social, and Björn Ommer.
08.01.2025 15:54 — 👍 1 🔁 0 💬 1 📌 0
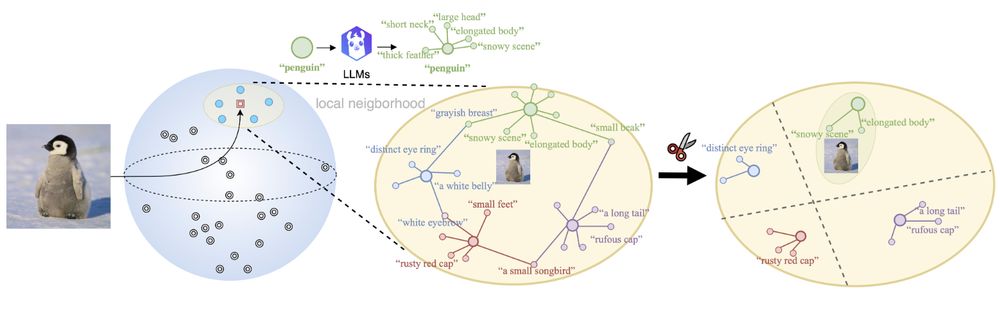
Our method pipeline
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
08.01.2025 15:54 — 👍 15 🔁 8 💬 1 📌 0
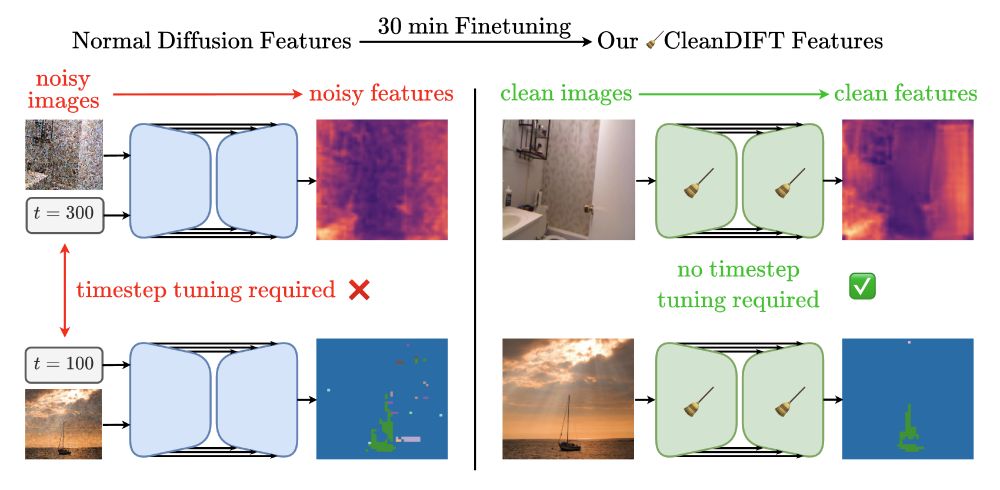
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
04.12.2024 23:31 — 👍 41 🔁 10 💬 2 📌 5
⛵️ Research Resident @ Midjourney
🇪🇺 Member @ellis.eu
🤖 Generative NNs, Deep Learning, ProbML, Simulation Intelligence
🎓 PhD+MSc Computer Science, MSc Psychology
🏡 https://marvin-schmitt.com
Official account for the IEEE/CVF International Conference on Computer Vision. #ICCV2025 Honolulu 🇺🇸 Co-hosted by @natanielruiz @antoninofurnari @yaelvinker @CSProfKGD
Professor of Psychology and Philosophy at the University of Illinois Urbana-Champaign. I build computational models and conduct experiments to understand how neural computing architectures give rise to symbolic thought.
PhD student at University of Copenhagen @belongielab.org | #nlp #computervision | ELLIS student @ellis.eu
🌐 https://jiaangli.github.io/
Niantic Spatial, Research.
Throws machine learning at traditional computer vision pipelines to see what sticks. Differentiates the non-differentiable.
📍Europe 🔗 http://ebrach.github.io
ELLIS PhD Fellow @belongielab.org | @aicentre.dk | University of Copenhagen | @amsterdamnlp.bsky.social | @ellis.eu
Multi-modal ML | Alignment | Culture | Evaluations & Safety| AI & Society
Web: https://www.srishti.dev/
Principal Research Manager & Project lead @ Microsoft Research AI for Science; AI for materials; Previously @ MIT, DeepMind, Google X. Views my own.
PhD Candidate @ MoML Tübingen
ELLIS PhD student at TU Munich & Helmholtz AI
Generative Modeling - Optimal Transport - Representation Learning
https://lucaeyring.com/
Student Researcher @ RAI Institute, MSc CS Student @ ETH Zurich
visual computing, 3D vision, spatial AI, machine learning, robot perception.
📍Zurich, Switzerland
ELLIS PhD student at ETH & Oxford. Ex-intern at Meta. 3D Vision, Machine Learning, Photogrammetry. ywyue.github.io
a mediocre combination of a mediocre AI scientist, a mediocre physicist, a mediocre chemist, a mediocre manager and a mediocre professor.
see more at https://kyunghyuncho.me/
Research Scientist in Computer Vision and Generative AI
PhD Student @ LMU Munich
https://ffundel.de/
Music, audio, and deep learning research at Stability AI ~ Building bridges between audio signal processing wisdom and deep learning.
artintech.substack.com
www.jordipons.me
Researcher (OpenAI. Ex: DeepMind, Brain, RWTH Aachen), Gamer, Hacker, Belgian.
Anon feedback: https://admonymous.co/giffmana
📍 Zürich, Suisse 🔗 http://lucasb.eyer.be
Professor at University of Technology Nuremberg
Head of Fundamental AI Lab
Interpretable Deep Networks. http://baulab.info/ @davidbau
Associate Professor in EECS at MIT. Neural nets, generative models, representation learning, computer vision, robotics, cog sci, AI.
https://web.mit.edu/phillipi/




















