TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
TREAD: Token Routing for Efficient Architecture-agnostic Diffusion Training
Finally, Felix will present his work on making diffusion transformer training extremely efficient, going from costing multiple months of rent to less than a single night at a conference hotel!
compvis.github.io/tread/
19.10.2025 18:13 — 👍 1 🔁 0 💬 0 📌 0
Stefan and Timy will be talking about how we can achieve extremely efficient motion prediction in open-set settings: bsky.app/profile/stef...
19.10.2025 18:12 — 👍 1 🔁 0 💬 1 📌 0
Pingchuan and Ming will be presenting two works on modeling the evolution of artistic style and disentangled representation learning.
See the following thread for more details bsky.app/profile/pima...
19.10.2025 18:10 — 👍 1 🔁 0 💬 1 📌 0

Excited to share that we'll be presenting four papers at the main conference at ICCV 2025 this week!
Come say hi in Honolulu!
👋 Pingchuan, Ming, Felix, Stefan, Timy, and Björn Ommer will be attending.
19.10.2025 18:05 — 👍 2 🔁 1 💬 1 📌 0

🎉 From @elsa-ai.eu: 15 new members join the European Lighthouse on Secure & Safe AI—expanding reach across Europe and deepening ties with the @ellis.eu ecosystem.
Everything you need to know 👉 elsa-ai.eu/elsa-welcome...
17.10.2025 07:05 — 👍 3 🔁 2 💬 0 📌 0
Fascinating approach — encoding an entire image into a single continuous latent token via self-supervised representation learning.
RepTok 🦎 highlights how compact generative representations can retain both realism and semantic structure.
17.10.2025 11:59 — 👍 2 🔁 0 💬 0 📌 0

🤔 What happens when you poke a scene — and your model has to predict how the world moves in response?
We built the Flow Poke Transformer (FPT) to model multi-modal scene dynamics from sparse interactions.
It learns to predict the 𝘥𝘪𝘴𝘵𝘳𝘪𝘣𝘶𝘵𝘪𝘰𝘯 of motion itself 🧵👇
15.10.2025 01:56 — 👍 24 🔁 8 💬 1 📌 1

𝗖𝗮𝗹𝗹 𝗳𝗼𝗿 𝗳𝘂𝗹𝗹𝘆 𝗳𝘂𝗻𝗱𝗲𝗱 𝗣𝗵𝗗 𝗣𝗼𝘀𝗶𝘁𝗶𝗼𝗻𝘀: We are offering several PhD positions across our various research areas, open to highly qualified candidates.
‼️ The application portal will be open from 15 October to 14 November 2025.
Find out more: mcml.ai/opportunitie...
10.10.2025 06:57 — 👍 6 🔁 6 💬 0 📌 1

🎧 ELLIOT on the airwaves!
How do we build open and trustworthy AI in Europe?
🎙️ In a recent radio interview, Luk Overmeire from VRT shared insights on ELLIOT, #FoundationModels and the role of public broadcasters in shaping human-centred AI.
📻 Interview in Dutch: mimir.mjoll.no/shares/JRqlO...
03.07.2025 10:38 — 👍 1 🔁 1 💬 0 📌 0

🎉 The ELLIOT project Kick-off Meeting was successfully hosted by CERTH-ITI, in Thessaloniki! 🏛️
30 partners from 12 countries 🌍 launched this exciting journey to advance open, trustworthy AI and #FoundationModels across Europe. 🤖
Stay tuned for more updates on #AIresearch and #TrustworthyAI! 💡
11.07.2025 07:09 — 👍 4 🔁 3 💬 0 📌 0
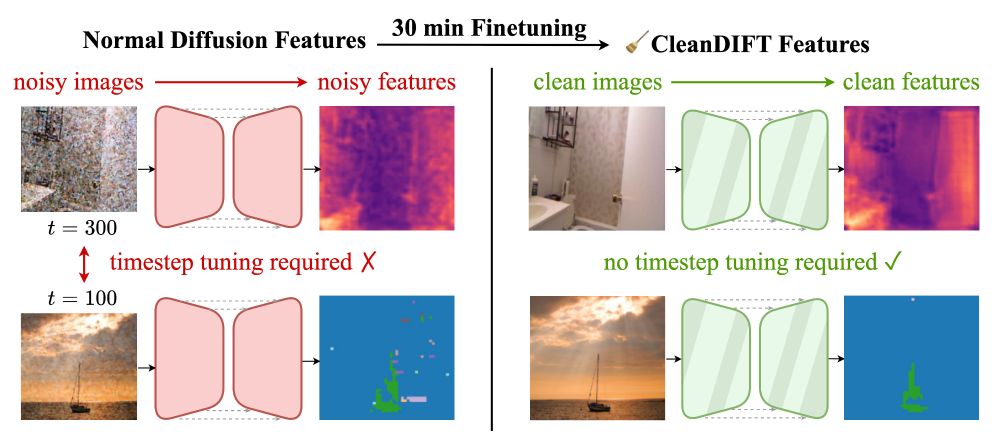
CleanDIFT: Diffusion Features without Noise
CleanDIFT enables extracting Noise-Free, Timestep-Independent Diffusion Features
🧹 CleanDiFT: Diffusion Features without Noise
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
09.06.2025 07:58 — 👍 8 🔁 3 💬 1 📌 0

🎉 Excited to share that our lab has three papers accepted at CVPR 2025!
Come say hi in Nashville!
👋 Johannes, Ming, Kolja, Stefan, and Björn will be attending.
09.06.2025 07:28 — 👍 1 🔁 2 💬 1 📌 0

📢 ELLIOT is coming! A €25M #HorizonEurope project to develop open, trustworthy Multimodal Generalist Foundation Models, #MGFM, for real-world applications. Starting July, it brings 30 partners from 12 countries to shape Europe’s #AI future.
🔍 Follow for updates on #OpenScience & #FoundationModels.
12.06.2025 07:35 — 👍 4 🔁 3 💬 0 📌 0

Subject-Specific Concept Control
We reveal that certain directions in CLIP text embeddings permit detailed attribute control in text-to-image models.
Continuous Subject-Specific Attribute Control in T2I Models by Identifying Semantic Directions
@stefanabaumann.bsky.social, Felix Krause, Michael Neumayr, @rmsnorm.bsky.social, Melvin Sevi, @vtaohu.bsky.social, Björn Ommer
P. Sess 3 (ExHall D): Sat 10:30-12:30, #246
compvis.github.io/attribute-co...
09.06.2025 08:08 — 👍 2 🔁 0 💬 0 📌 0
GitHub - CompVis/diff2flow: [CVPR 2025] Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment
[CVPR 2025] Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment - CompVis/diff2flow
Diff2Flow: Training Flow Matching Models via Diffusion Model Alignment
@joh-schb.bsky.social*, @mgui7.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Poster Session 6 (ExHall D): Sunday 16:00-18:00, # 208
github.com/CompVis/diff...
09.06.2025 08:03 — 👍 2 🔁 0 💬 1 📌 0
CleanDIFT: Diffusion Features without Noise
CleanDIFT enables extracting Noise-Free, Timestep-Independent Diffusion Features
🧹 CleanDiFT: Diffusion Features without Noise
@rmsnorm.bsky.social*, @stefanabaumann.bsky.social*, @koljabauer.bsky.social*, @frankfundel.bsky.social, Björn Ommer
Oral Session 1C (Davidson Ballroom): Friday 9:00
Poster Session 1 (ExHall D): Friday 10:30-12:30, # 218
compvis.github.io/cleandift/
09.06.2025 07:58 — 👍 8 🔁 3 💬 1 📌 0
🎉 Excited to share that our lab has three papers accepted at CVPR 2025!
Come say hi in Nashville!
👋 Johannes, Ming, Kolja, Stefan, and Björn will be attending.
09.06.2025 07:28 — 👍 1 🔁 2 💬 1 📌 0

Grand Opening of the AI-HUB@LMU. The AI-HUB@LMU is a platform that for the first time unites all 18 faculties of the #LMU as a joint scientific community.
📅January 29, 2025, 6:00 PM
📍 Große Aula, LMU Munich
Full program here: www.ai-news.lmu.de/grand-openin...
20.01.2025 11:59 — 👍 4 🔁 1 💬 0 📌 0
YouTube video by DLD Conference
Building a New Foundation Model (Björn Ommer) | DLD25
www.youtube.com/watch?v=bCy6...
20.01.2025 10:01 — 👍 10 🔁 2 💬 0 📌 0


Attending my first corporate-sponsored business conference: there’s a live band playing between talks to keep the energy up.
Meanwhile, academic conferences are struggling to afford coffee breaks. Want this for EPSA!
@compvis.bsky.social
16.01.2025 09:27 — 👍 8 🔁 1 💬 1 📌 0
bsky.app/profile/pima...
09.01.2025 15:56 — 👍 2 🔁 0 💬 0 📌 0
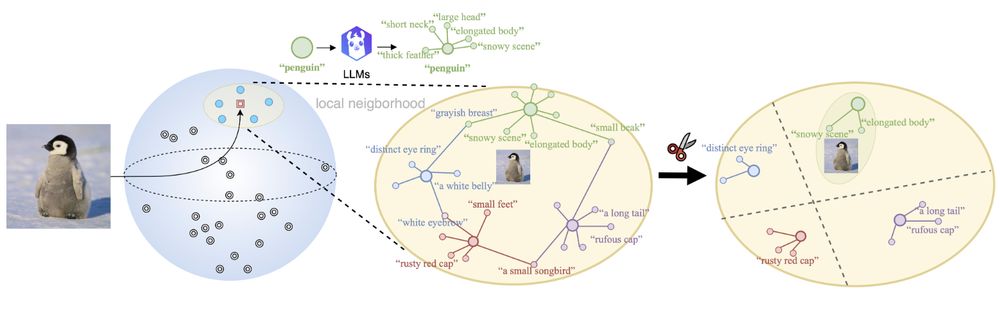
Our method pipeline
🤔When combining Vision-language models (VLMs) with Large language models (LLMs), do VLMs benefit from additional genuine semantics or artificial augmentations of the text for downstream tasks?
🤨Interested? Check out our latest work at #AAAI25:
💻Code and 📝Paper at: github.com/CompVis/DisCLIP
🧵👇
08.01.2025 15:54 — 👍 15 🔁 8 💬 1 📌 0
Did you know you can distill the capabilities of a large diffusion model into a small ViT? ⚗️
We showed exactly that for a fundamental task:
semantic correspondence📍
A thread 🧵👇
06.12.2024 14:35 — 👍 4 🔁 2 💬 1 📌 2
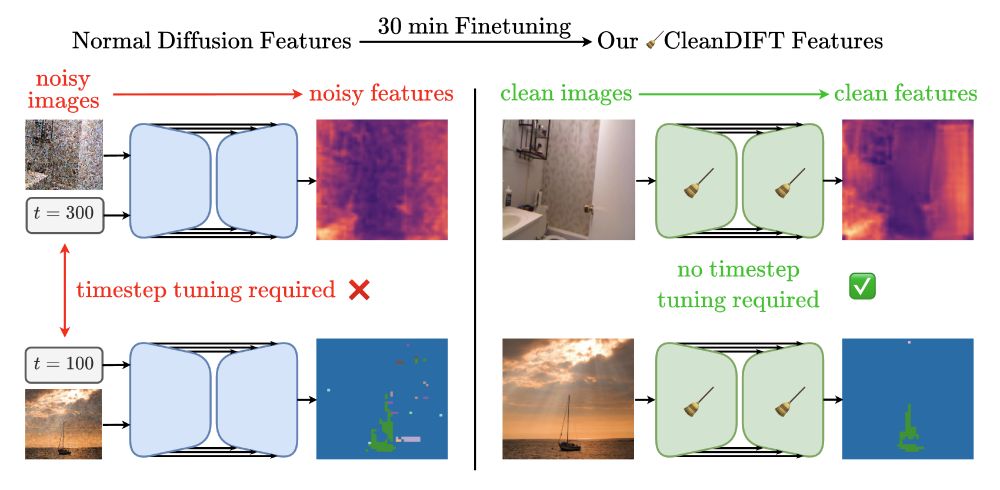
🤔 Why do we extract diffusion features from noisy images? Isn’t that destroying information?
Yes, it is - but we found a way to do better. 🚀
Here’s how we unlock better features, no noise, no hassle.
📝 Project Page: compvis.github.io/cleandift
💻 Code: github.com/CompVis/clea...
🧵👇
04.12.2024 23:31 — 👍 42 🔁 10 💬 2 📌 5