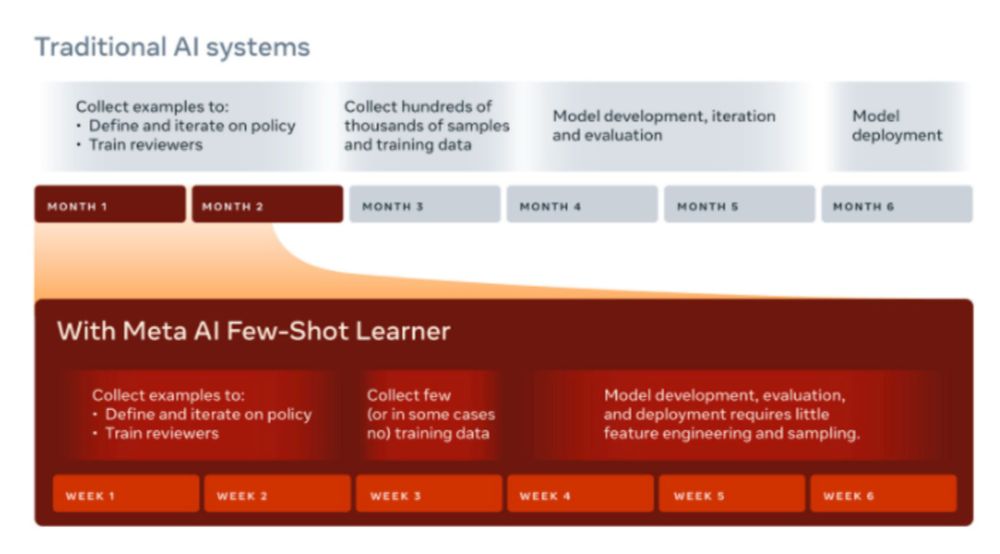
I just noticed this: Did Meta AI Few-Shot Learner's use of policy description inspire Anthropic's Constitutional AI, a year later?
ai.meta.com/blog/harmful...
www.anthropic.com/research/con...

@eify.bsky.social
I just noticed this: Did Meta AI Few-Shot Learner's use of policy description inspire Anthropic's Constitutional AI, a year later?
ai.meta.com/blog/harmful...
www.anthropic.com/research/con...
Not sure about that, but that NHS page still recommends it if you have been trained and feel confident.
12.12.2024 07:24 — 👍 0 🔁 0 💬 0 📌 0"If you have been trained in CPR, including rescue breaths, and feel confident using your skills, you should give chest compressions with rescue breaths".
You wrote "If you haven't learnt how to do CPR, learn how to do CPR". It's a fair interpretation that you meant the full package.
Is it worth the risk of COVID infection though?
Conditional probability of someone who needs CPR being COVID-positive is even higher than the unconditional probability.
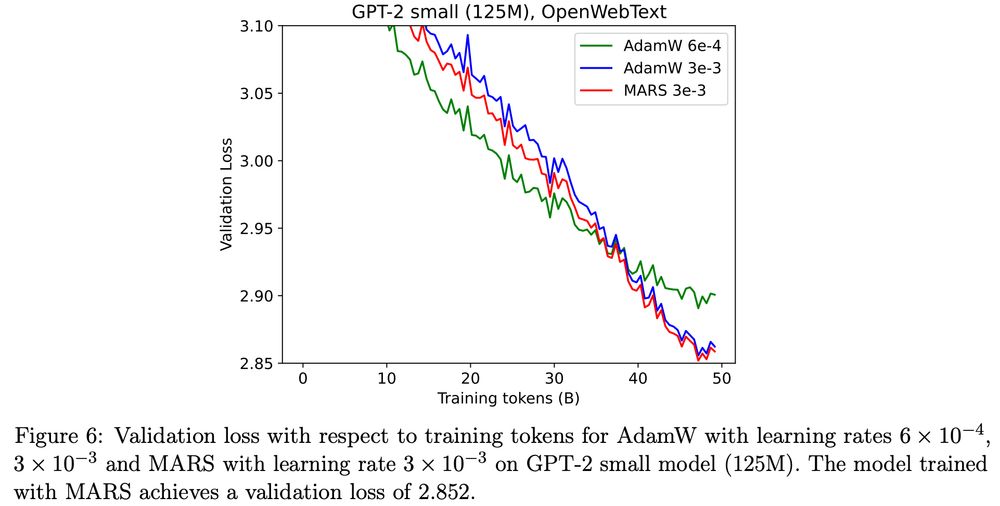
Figure 6: Validation loss with respect to training tokens for AdamW with learning rates 6 × 10−4, 3 × 10−3 and MARS with learning rate 3 × 10−3 on GPT-2 small model (125M). The model trained with MARS achieves a validation loss of 2.852.
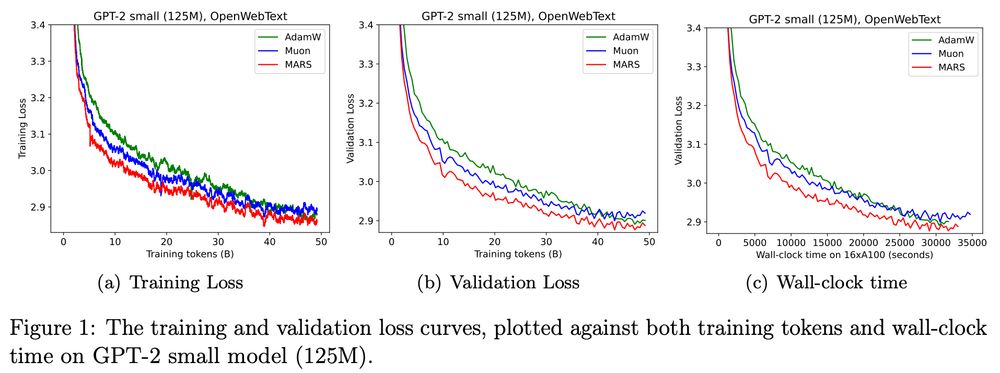
Figure 1: The training and validation loss curves, plotted against both training tokens and wall-clock time on GPT-2 small model (125M).
It seems that AdamW & MARS (arxiv.org/abs/2411.10438) effectively reach the same val loss for GPT-2 small with the optimal LR according to Appendix B, in contrast to Figure 1? @quanquangu.bsky.social
If MARS is less sensitive to LR that's also an advantage, but a different kind.
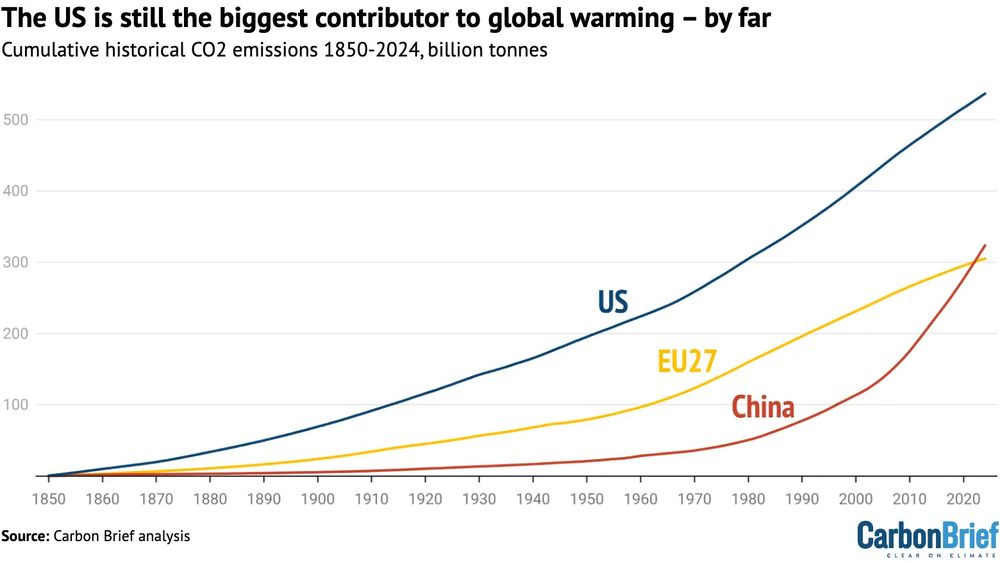
The US is still the biggest contributor to global warming - by far
Strange takeaway from that article, I have to say...
All the US have to do to help is to cut Chinese cleantech tariff.
www.theguardian.com/business/art...
Critical module of TensorFlow (TensorFlow Text) still doesn't support Python 3.12. I had to switch back to 3.11 😬
github.com/tensorflow/t...
That training run failed to converge anyway but TIL if you use multiprocessing to spawn new processes you can't edit .py file while the code is running: python interpreter needs to compile the source again to do that!
25.11.2024 20:41 — 👍 0 🔁 0 💬 0 📌 0
Perhaps worth mentioning:
www.nature.com/articles/d41...











