I am recruiting graduate students for the experimental side of my lab @mcgill.ca for admission in Fall 2026!
Get in touch if you're interested in how brain circuits implement distributed computation, including dopamine-based distributed RL and probabilistic representations.
19.11.2025 18:04 — 👍 33 🔁 24 💬 1 📌 0

Checking out the Princeton trails on our lab retreat
03.11.2025 17:44 — 👍 28 🔁 1 💬 0 📌 0

📄 Paper: arxiv.org/abs/2507.07207
💻 Code: github.com/smonsays/sca...
04.11.2025 14:34 — 👍 2 🔁 0 💬 0 📌 0

But, not all training distributions enable compositional generalization -- even with scale.
Strategically choosing the training data matters a lot.
04.11.2025 14:34 — 👍 1 🔁 0 💬 1 📌 0

We prove that MLPs can implement a general class of compositional tasks ("hyperteachers") using only a linear number of neurons in the number of modules, beating the exponential!
04.11.2025 14:34 — 👍 1 🔁 0 💬 1 📌 0

It turns out that simply scaling multilayer perceptrons / transformers can lead to compositional generalization.
04.11.2025 14:34 — 👍 1 🔁 0 💬 1 📌 0

Most natural data has compositional structure. This leads to a combinatorial explosion that is impossible to fully cover in the training data.
It might be tempting to think that we need to equip neural network architectures with stronger symbolic priors to capture this compositionality, but do we?
04.11.2025 14:34 — 👍 1 🔁 0 💬 1 📌 0
Plots showing how scaling model size and data size leads to compositional generalization

A generated image composition of a clock inside a treasure chest inside a transparent cube.
Does scaling lead to compositional generaliztation?
Our #NeurIPS2025 Spotlight paper suggests that it can -- with the right training distribution.
🧵 A short thread:
04.11.2025 14:34 — 👍 14 🔁 1 💬 1 📌 0

Nassau Hall. Photo credit to Debbie and John O'Boyle
I'm joining Princeton University as an Associate Professor of Computer Science and Psychology this fall! Princeton is ambitiously investing in AI and Natural & Artificial Minds, and I'm excited for my lab to contribute. Recruiting postdocs and Ph.D. students in CS and Psychology — join us!
12.06.2025 14:29 — 👍 47 🔁 2 💬 4 📌 0

Are transformers smarter than you? Hypernetworks might explain why.
Come checkout our Oral at #ICLR tomorrow (Apr 26th, poster at 10:00, Oral session 6C in the afternoon).
openreview.net/forum?id=V4K...
25.04.2025 04:50 — 👍 10 🔁 0 💬 1 📌 0
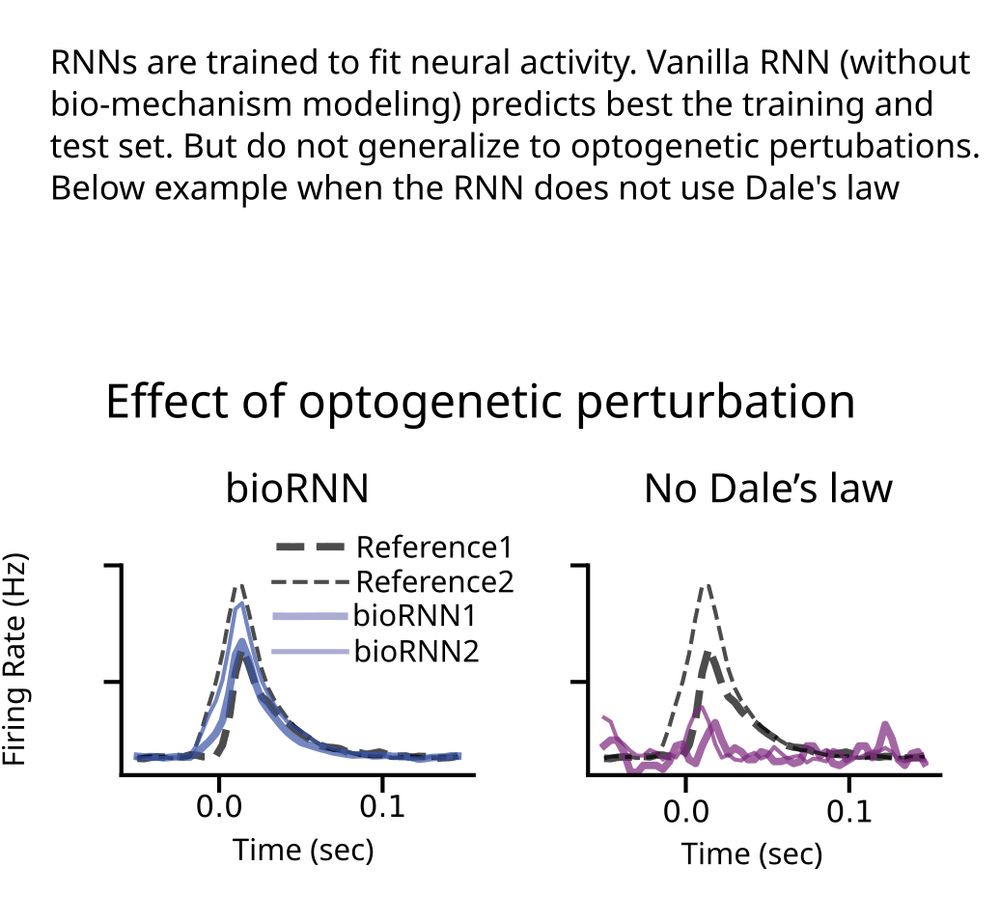
Pre-print 🧠🧪
Is mechanism modeling dead in the AI era?
ML models trained to predict neural activity fail to generalize to unseen opto perturbations. But mechanism modeling can solve that.
We say "perturbation testing" is the right way to evaluate mechanisms in data-constrained models
1/8
08.01.2025 16:33 — 👍 116 🔁 46 💬 4 📌 2

2024: A Review of the Year in Neuroscience
Feeling a bit wired
Cutting it a bit fine, but here’s my review of the year in neuroscience for 2024
The eighth of these, would you believe? We’ve got dark neurons, tiny monkeys, the most complete brain wiring diagram ever constructed, and much more…
Published on The Spike
Enjoy!
medium.com/the-spike/20...
30.12.2024 16:00 — 👍 190 🔁 73 💬 7 📌 18
An introduction to reinforcement learning for neuroscience | Published in Neurons, Behavior, Data analysis, and Theory
By Kristopher T. Jensen. Reinforcement learning for neuroscientists
I wrote an introduction to RL for neuroscience last year that was just published in NBDT: tinyurl.com/5f58zdy3
This review aims to provide some intuition for and derivations of RL methods commonly used in systems neuroscience, ranging from TD learning through the SR to deep and distributional RL!
21.12.2024 17:59 — 👍 129 🔁 31 💬 6 📌 0

Monster Models
Systems-level biology is hard because systems-level engineering is hard.
Stitching component models into system models has proven difficult in biology. But how much easier has it been in engineering? www.argmin.net/p/monster-mo...
20.12.2024 15:29 — 👍 12 🔁 2 💬 3 📌 1
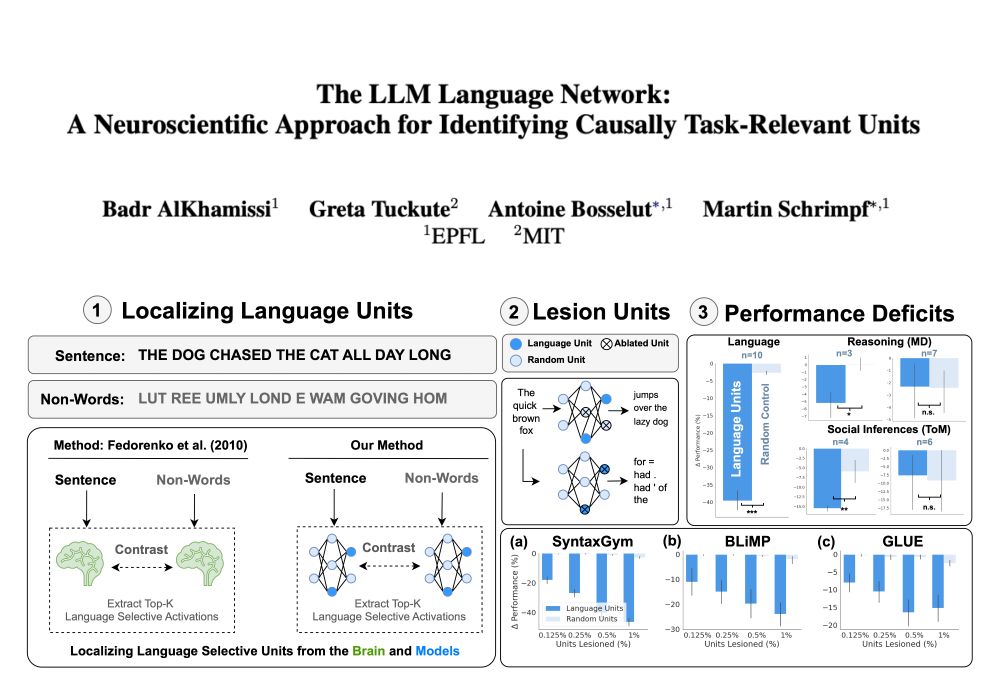
🚨 New Paper!
Can neuroscience localizers uncover brain-like functional specializations in LLMs? 🧠🤖
Yes! We analyzed 18 LLMs and found units mirroring the brain's language, theory of mind, and multiple demand networks!
w/ @gretatuckute.bsky.social, @abosselut.bsky.social, @mschrimpf.bsky.social
🧵👇
19.12.2024 15:06 — 👍 105 🔁 27 💬 2 📌 5
1/ Okay, one thing that has been revealed to me from the replies to this is that many people don't know (or refuse to recognize) the following fact:
The unts in ANN are actually not a terrible approximation of how real neurons work!
A tiny 🧵.
🧠📈 #NeuroAI #MLSky
16.12.2024 20:03 — 👍 151 🔁 38 💬 21 📌 17
For my first post on Bluesky .. I'll start by announcing our 2025 edition of EEML which will be in Sarajevo :) ! I'm really excited about it and hope to see many of you there. Please follow the website (and Bluesky account) for more details which are coming soon ..
15.12.2024 18:39 — 👍 32 🔁 7 💬 1 📌 0
Have you had private doubts whether we'll ever understand the brain? Whether we'll be able explain psychological phenomena in an exhaustive way that ranges from molecules to membranes to synapses to cells to cell types to circuits to computation to perception and behavior?
14.11.2024 05:18 — 👍 39 🔁 12 💬 1 📌 1

The broader spectrum of in-context learning
The ability of language models to learn a task from a few examples in context has generated substantial interest. Here, we provide a perspective that situates this type of supervised few-shot learning...
What counts as in-context learning (ICL)? Typically, you might think of it as learning a task from a few examples. However, we’ve just written a perspective (arxiv.org/abs/2412.03782) suggesting interpreting a much broader spectrum of behaviors as ICL! Quick summary thread: 1/7
10.12.2024 18:17 — 👍 122 🔁 31 💬 2 📌 1

Thrilled to share our NeurIPS Spotlight paper with Jan Bauer*, @aproca.bsky.social*, @saxelab.bsky.social, @summerfieldlab.bsky.social, Ali Hummos*! openreview.net/pdf?id=AbTpJ...
We study how task abstractions emerge in gated linear networks and how they support cognitive flexibility.
03.12.2024 16:04 — 👍 65 🔁 15 💬 2 📌 1
Would love to be added as well :)
20.11.2024 20:50 — 👍 0 🔁 0 💬 0 📌 0
Great thread from @michaelhendricks.bsky.social!
Reminds me of something Larry Abbott once said to me at a summer school:
Many physicists come into neuroscience assuming that the failure to find laws of the brain was just because biologists aren't clever enough. In fact, there are no laws.
🧠📈 🧪
13.11.2024 18:49 — 👍 68 🔁 9 💬 4 📌 1

(1/5) Very excited to announce the publication of Bayesian Models of Cognition: Reverse Engineering the Mind. More than a decade in the making, it's a big (600+ pages) beautiful book covering both the basics and recent work: mitpress.mit.edu/978026204941...
18.11.2024 16:25 — 👍 521 🔁 119 💬 15 📌 15
🙋♂️
16.11.2024 15:30 — 👍 1 🔁 0 💬 0 📌 0
To help find people at the intersection of neuroscience and AI. Of course let me know if I missed someone or you’d like to be added 🧪 🧠
#neuroskyence
go.bsky.app/CAfmKQs
13.11.2024 15:26 — 👍 50 🔁 18 💬 33 📌 0
I think you are already part of it - just double checked :)
13.11.2024 15:20 — 👍 1 🔁 0 💬 0 📌 0
Postdoc @ Princeton AI Lab
Natural and Artificial Minds
Prev: PhD @ Brown, MIT FutureTech
Website: https://annatsv.github.io/
The Kempner Institute for the Study of Natural and Artificial Intelligence at Harvard University.
asst prof @Stanford linguistics | director of social interaction lab 🌱 | bluskies about computational cognitive science & language
PhD student @csail.mit.edu 🤖 & 🧠
•PhD student @ https://www.ucl.ac.uk/gatsby 🧠💻
•Masters Theoretical Physics UoM|UCLA🪐
•Intern @zuckermanbrain.bsky.social|
@SapienzaRoma | @CERN | @EPFL
https://linktr.ee/Clementine_Domine
Director of Helmholtz Institute for Human-Centered AI in Munich.
Cognitive science, machine learning, large models.
https://hcai-munich.com
HFSP Postdoc Fellow at U Chicago in the Doiron lab | former PhD @MPI for Brain Research & TU Munich in the Gjorgjeva lab
https://www.christophmiehl.com/
PhD student at NYU. Interested in making machines insightful.
computational cog sci • problem solving and social cognition • asst prof at NYU • https://codec-lab.github.io/
Assistant professor at Yale Linguistics. Studying computational linguistics, cognitive science, and AI. He/him.
Across many scientific disciplines, researchers in the Bernstein Network connect experimental approaches with theoretical models to explore brain function.
neuromantic - ML and cognitive computational neuroscience - PhD student at Kietzmann Lab, Osnabrück University.
⛓️ https://init-self.com
Computer Security Researcher @ Cambridge (https://www.danielhugenroth.com) and Co-Founder @ Light Squares (https://www.lightsquares.dev)
PhD in AI @mila-quebec.bsky.social RLHF and language grounding, whatever that means. Whitespace aficianado. mnoukhov.github.io
Studying cognition in humans and machines https://scholar.google.com/citations?user=WCmrJoQAAAAJ&hl=en
Neuroscientist studying social behavior and decision making @ETH Zürich @Grewe lab
Outside of the lab, I love doing nature-inspired artistic projects! My most recent project: https://hellodino.ch 🦕🦕
Cognitive Scientist at Max Planck, Professor of Psychology
https://www.falkhuettig.com/
Author of 'Looking Ahead: The New Science of the Predictive Mind' published by Cambridge University Press on 6 March 2025.