
Been thinking about the trends at the intersection of AI and RecSys. Where are we heading. Based on my own work, extensive research, and lots of analysis/thinking, I have put together my thoughts in a detailed article on substack.
Link: open.substack.com/pub/januverm...
29.01.2026 10:39 — 👍 0 🔁 0 💬 0 📌 0
When we try to fight Cold Shyness with willpower, we usually lose. The brain is too good at bargaining for comfort. The thing that fixes it is low-stakes repetition.
I wrote about why I stopped trying to "Win January" and started treating it as a training block for a February 1st "official" start.
05.01.2026 18:13 — 👍 0 🔁 0 💬 0 📌 0

There is a specific kind of friction that hits on January 1st. I call it "Cold Shyness." It’s that reluctance to be out there—whether physically in the cold or metaphorically in a new skill—exposed and uncomfortable.
05.01.2026 18:13 — 👍 1 🔁 0 💬 1 📌 0
Whether through multi-task learning, auxiliary objectives, or simply smarter input design, giving models context unlocks generalization, robustness, and sometimes surprising insights.
It’s a good reminder: The best models don’t just predict, they understand
11.07.2025 12:23 — 👍 0 🔁 0 💬 0 📌 0
Auxiliary Tasks: When training for sentiment analysis, add an auxiliary task like predicting part-of-speech tags. A better understanding of grammar leads to a better understanding of sentiment.
11.07.2025 12:23 — 👍 0 🔁 0 💬 1 📌 0
Additional Contextual Data e.g. search queries in recommendations models: A user's search history is pure gold. A streaming service that sees you're searching for "Oscar-winning movies" can offer far more relevant suggestions than one relying on watch history alone.
11.07.2025 12:23 — 👍 0 🔁 0 💬 1 📌 0
Multi-Objective Training: Don't just predict customer purchase; also predict the likelihood of a return and a positive review. This creates a more holistic and useful e-commerce model.
11.07.2025 12:23 — 👍 0 🔁 0 💬 1 📌 0
Add. Related. Context.
Often, the most significant performance gains come from enriching models with related, contextual info. Models get better by being exposed to auxiliary signals that deepen their understanding of the task.
11.07.2025 12:23 — 👍 0 🔁 0 💬 1 📌 0
Covers the significance of Anfinsen’s experiment, the role of the CASP competition, and why protein structure prediction was considered an AI-complete problem. This sets the stage for understanding how AlphaFold-2 achieved its breakthrough.
09.07.2025 10:15 — 👍 0 🔁 0 💬 1 📌 0

My latest blog post dives into the protein folding problem - a fundamental question in molecular biology that puzzled scientists for decades, until deep learning models like AlphaFold changed the game. I walk through the biological and computational roots of the problem.
09.07.2025 10:15 — 👍 2 🔁 0 💬 1 📌 0

Part III involves using frontier models to generate (synthetic) ‘reasoning’ for user engagement based on past interactions and then use the reasoning-augmented data to SFT Qwen 1.5B model. Comparable or better results with just 10% of the interaction open.substack.com/pub/januverma/…
12.02.2025 21:58 — 👍 0 🔁 0 💬 0 📌 0

Large Language Models for Recommender Systems II - Scaling
Do scaling laws extend to recommendation?
Part II of my explorations with LLMs for Recommendation tasks involves experimenting with base models of varying sizes from 0.5B to 14B params(Qwen 2.5 Series) and incorporating user attributes.
januverma.substack.com/p/large-language-models-for-recommender-35c
04.02.2025 14:31 — 👍 0 🔁 0 💬 1 📌 0

Large Language Models for Recommender Systems
Can LLMs reason over user behaviour data to decipher preferences?
First experiment is on building a proof of concept for LLM recommender by supervised fine-tuning (SFT) a small-scale LLM (Llama 1B). januverma.substack.com/p/large-lang...
04.02.2025 14:27 — 👍 0 🔁 0 💬 1 📌 0
Large Language Models for Recommender Systems
Can LLMs reason over user behaviour data to decipher preferences?
Recently, I’ve been exploring the potential of LLMs for recommendation tasks. Sharing the first report of my project where I experiment with the ability of Llama 1B model to understand user preferences from their past behavior.
open.substack.com/pub/januverm...
24.01.2025 18:03 — 👍 0 🔁 0 💬 0 📌 0
Have we swapped “reasoning” for “agentic” as the new shibboleth
16.01.2025 16:17 — 👍 1 🔁 0 💬 0 📌 0
Just came back after a month in India, no-laptop family time. Any tips on how to motivate myself to do any work are highly appreciated 🙏
10.01.2025 11:57 — 👍 1 🔁 0 💬 1 📌 0
The queen of examples and counterexamples!
08.12.2024 01:50 — 👍 44 🔁 9 💬 1 📌 0
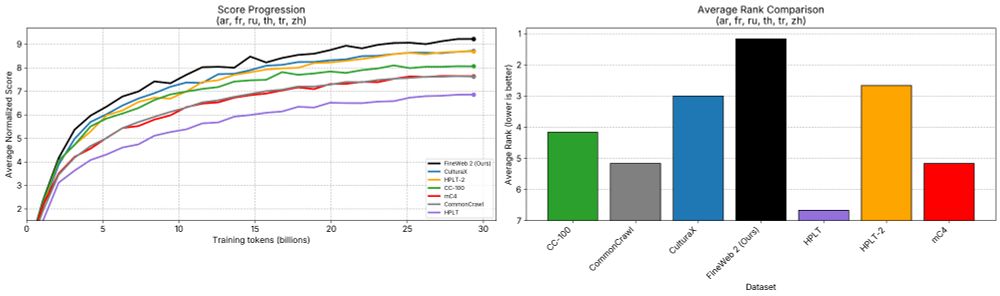
The FineWeb team is happy to finally release "FineWeb2" 🥂🥳
FineWeb 2 extends the data driven approach to pre-training dataset design that was introduced in FineWeb 1 to now covers 1893 languages/scripts
Details: huggingface.co/datasets/Hug...
A detailed open-science tech report is coming soon
08.12.2024 09:08 — 👍 106 🔁 13 💬 3 📌 2
Nothing like waking up to see your models training in a nice way. #neuralnets
04.12.2024 07:43 — 👍 0 🔁 0 💬 0 📌 0
Or they are too narcissistic to even notice the work/life of others. I feel there could be a coping mechanism to make their view quite myopic - ignorance is a bliss, I guess.
03.12.2024 07:18 — 👍 1 🔁 0 💬 0 📌 0

Taxi Driver knew better
02.12.2024 16:04 — 👍 0 🔁 0 💬 0 📌 0
Can’t wait for new stuff in the RLHF book. Part of my holidays reading plan.
02.12.2024 16:00 — 👍 1 🔁 0 💬 0 📌 0
YouTube video by Yoav Artzi
Jonathan Berant (Tel Aviv University / Google) / Towards Robust Language Model Post-training
I am seriously behind uploading Learning Machines videos, but I did want to get @jonathanberant.bsky.social's out sooner than later. It's not only a great talk, it also gives a remarkably broad overview and contextualization, so it's an excellent way to ramp up on post-training
youtu.be/2AthqCX3h8U
02.12.2024 03:45 — 👍 53 🔁 12 💬 1 📌 0
And a never ending pit. Where do you stop with prompt refinement and based on what criteria is surely messy.
01.12.2024 10:37 — 👍 0 🔁 0 💬 0 📌 0
Won’t help with my reputation but since I worked on social network analysis/regulation: if Bluesky ever is a success, they are extremely likely to retrain AI models (not necessarily LLM) on user data.
29.11.2024 18:53 — 👍 60 🔁 19 💬 6 📌 7
Oh that’s so interesting. I do think given the political landscape, it is hard to have a consensus on what is a lie or who you believe.
30.11.2024 08:59 — 👍 0 🔁 0 💬 1 📌 0
Superciliously super silly.
Researching planning, reasoning, and RL in LLMs @ Reflection AI. Previously: Google DeepMind, UC Berkeley, MIT. I post about: AI 🤖, flowers 🌷, parenting 👶, public transit 🚆. She/her.
http://www.jesshamrick.com
Neuroscientist: consciousness, perception, and Dreamachines. Author of Being You - A New Science of Consciousness.
Staff Research Scientist at Google DeepMind. Artificial and biological brains 🤖 🧠
Research on AI and biodiversity 🌍
Asst Prof at MIT CSAIL,
AI for Conservation slack and CV4Ecology founder
#QueerInAI 🏳️🌈
Senior Staff Research Scientist, Google DeepMind
Affiliated Lecturer, University of Cambridge
Associate, Clare Hall
GDL Scholar, ELLIS @ellis.eu
🇷🇸🇲🇪🇧🇦
🧙🏻♀️ scientist at Meta NYC | http://bamos.github.io
Assistant professor at Yale Linguistics. Studying computational linguistics, cognitive science, and AI. He/him.
PhD student at UC Berkeley. NLP for signed languages and LLM interpretability. kayoyin.github.io
🏂🎹🚵♀️🥋
AI, sociotechnical systems, social purpose. Research director at Google DeepMind. Cofounder and Chair at Deep Learning Indaba. FAccT2025 co-program chair. shakirm.com
Physics, philosophy, complexity. @jhuartssciences.bsky.social & @sfiscience.bsky.social. Host, #MindscapePodcast. Married to @jenlucpiquant.bsky.social.
Latest books: The Biggest Ideas in the Universe.
https://preposterousuniverse.com/
founder & ceo @blockpartyapp.com: helping you deep clean your socials and live a better online life
harvard bkc affiliate. cofounder project include. early eng at pinterest, quora, usds. stanford bs ee and ms cs. 2022 time woman of the year.
Writing about robots https://itcanthink.substack.com/
RoboPapers podcast https://robopapers.substack.com/
All opinions my own
Mathematician at UCLA. My primary social media account is https://mathstodon.xyz/@tao . I also have a blog at https://terrytao.wordpress.com/ and a home page at https://www.math.ucla.edu/~tao/
Senior Research Scientist at NVIDIA | Computer Vision | AI for science
I make sure that OpenAI et al. aren't the only people who are able to study large scale AI systems.
Senior Research Scientist @MBZUAI. Focused on decision making under uncertainty, guided by practical problems in healthcare, reasoning, and biology.
CEO & co-founder at .txt. I wander.
Research Engineer at Google DeepMind
A special snowflake existing in 196883 dimensions
#ActuallyAutistic He/Him























