An academic poster titled "Words that work: Using large language models to generate and refine hypotheses" by Rafael M. Batista & James Ross.
The poster presents a framework that combines Large Language Models (LLMs), Machine Learning (ML), and human evaluation to generate interpretable hypotheses from text data. A central diagram shows a three-step process: 1. Hypothesize (using an LLM to generate a hypothesis from text pairs), 2. Intervene (rewriting text to incorporate the hypothesized feature), and 3. Predict (using an ML model to measure the effect of the change).
The framework was applied to a dataset of news headlines to find what drives engagement. The poster lists generated hypotheses, such as "Framing a message with an element of surprise" or "Incorporating the concept of parody" increases engagement.
A section on out-of-sample testing shows a regression table with statistically significant results for several hypotheses, including Surprise, Parody/Sarcasm, and Physical Reaction. A bar chart on the left illustrates the additional explanatory power gained from the newly discovered features compared to previously known ones. A QR code is in the top right corner.
This alt-text was written by AI.
Here is a poster I presented today at the Human-AI Complementarity workshop hosted by the NSF #AI Institute for Societal Decision Making
You can read the latest version of the paper here: www.rafaelmbatista.com/jmp/
This is joint work with the wonderful @jamesross0.bsky.social
25.09.2025 19:36 — 👍 4 🔁 1 💬 0 📌 0
Saw Ben presenting this today. It’s really neat work.
Ben is finishing up his PhD at Cornell (advised by Jon Kleinberg) and is currently on the job market
25.09.2025 19:04 — 👍 7 🔁 1 💬 0 📌 0
Thanks Suresh! It’s still work in progress so let us know if you have any feedback.
15.08.2025 00:14 — 👍 1 🔁 0 💬 0 📌 0
This is quite clever and useful (read the full thread + the paper). I think/hope it opens up the path to a parallel study of their evolution on the epistemic/semantic space (i.e. what things they get better/worse at over time, what the utility gradients... 1/
via @tedunderwood.me
14.08.2025 17:33 — 👍 3 🔁 1 💬 1 📌 0
It should be in the thread somewhere!
arxiv.org/pdf/2508.06811
14.08.2025 16:36 — 👍 1 🔁 0 💬 1 📌 0
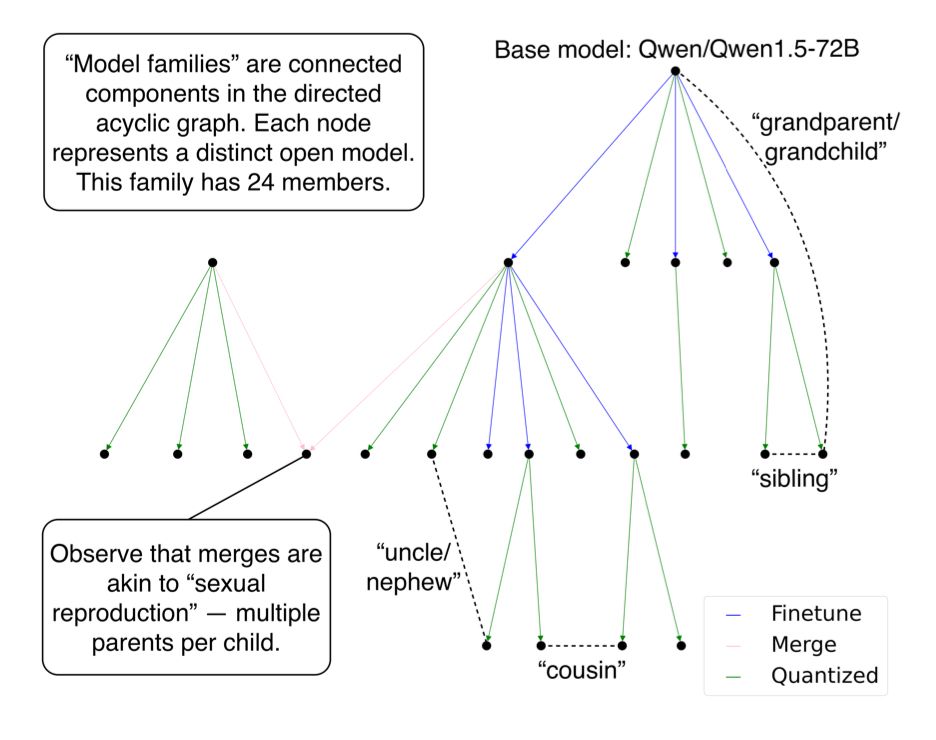
A schematic showing the different model relations in a given family (or connected component) in the Hugging Face graph.
We describe these details in the paper, e.g. in the schematic below.
14.08.2025 16:26 — 👍 1 🔁 0 💬 1 📌 0
One could imagine a future scenario in which merges lead to a phase transition in the HF graph where all families end up "marrying" creating a single connected component. We're not there now.
14.08.2025 16:26 — 👍 0 🔁 0 💬 1 📌 0
Thanks! Yes - model merges are akin to sexual reproduction where there are multiple parents, so any graph that includes merges would not be a tree. All other relations have one parent. We leave for future work dynamics arising from merges, and they are a small minority of relations as of now.
14.08.2025 16:26 — 👍 1 🔁 0 💬 1 📌 0
Oops-- empty tag. My collaborator's name is Hamidah Oderinwale.
14.08.2025 15:08 — 👍 0 🔁 0 💬 0 📌 0
This is just the start. We hope our dataset & methods open the door to a science of AI ecosystems.
If you care about open-source AI, governance, or the weird ways technology evolves, give it a read.
📄Paper: arxiv.org/pdf/2508.06811
14.08.2025 15:06 — 👍 1 🔁 0 💬 1 📌 0

The title page of our paper.
Big picture: By treating ML models like organisms in an ecosystem, we can:
🌱 Understand the pressures shaping AI development
🔍 Spot patterns before they become industry norms
🛠 Inform governance & safety strategies grounded in real data
14.08.2025 15:06 — 👍 2 🔁 0 💬 1 📌 0

A directed graph representing the typical direction of drift. For example, a directed edge pointing from gemma to mit suggests that more models mutate from gemma to mit than from mit to gemma. Color coding suggests that the general trend is commercial licenses mutate to other types of licenses. Of all creative commons licenses, the two most permissive varieties are downstream from those with more terms and restrictions.
We found optimal evolutionary orderings over traits:
🔹 Feature extraction tends to be upstream from text generation. Text generation is upstream from text classification.
🔹 Certain license types precede others (e.g., llama3 → apache-2.0)
Here we show the top-20 licenses transitions over fine-tunes.
14.08.2025 15:06 — 👍 0 🔁 0 💬 1 📌 0
The license drift to permissiveness suggests open-source preferences outweigh regulatory pressures to comply with licenses.
The English drift suggests a massive market for English products.
The docs drift could be explained as a preference for efficiency — or laziness.
14.08.2025 15:06 — 👍 0 🔁 0 💬 1 📌 0
Three major drifts we found:
1️⃣ Licenses: from corporate to other types. We often see use restrictions mutate to permissive or copyleft (even when counter to upstream license terms)
2️⃣ Languages: from multilingual → English-only
3️⃣ Docs: from long & detailed → short & templated
14.08.2025 15:06 — 👍 1 🔁 1 💬 1 📌 0
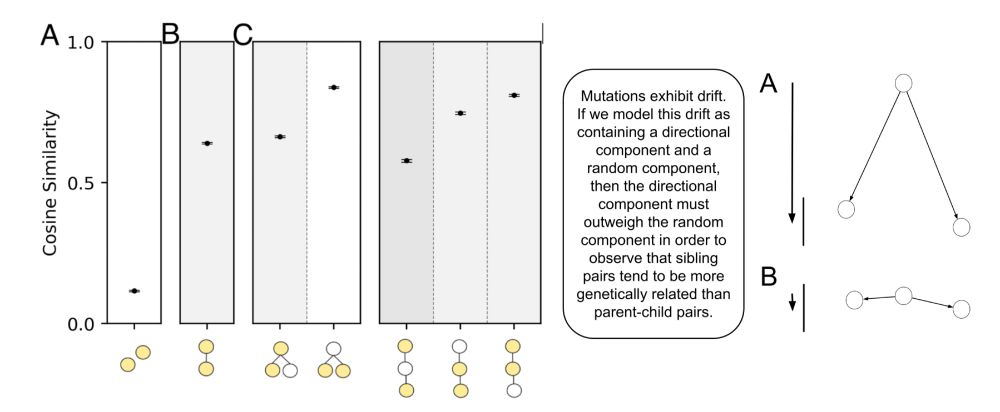
Some of our reported measurements showing that two related models have considerable more similarity in their data than any two (not-necessarily-related) models. Similarities are measured for pairs of models belonging to different subtree topologies. Interestingly, pairs of siblings are more related than parent-child pairs, even though they're further in distance over the tree. A diagram attempts to explain this as fast, directed mutation of traits.
In biology, traits get passed from parent to child — mutations are slow & often modeled as random.
In AI model families, mutations are fast and directed. Two sibling models tend to resemble each other more than they resemble their shared parent.
14.08.2025 15:06 — 👍 1 🔁 0 💬 1 📌 0

The "diff" in model data between two snippets of metadata, one (top) belonging to a base model and the other (bottom) belonging to one of its finetunes. Insertions, deletions and substitutions are shown in green, red and yellow respectively. The figure is supposed to evoke DNA sequencing.
We measured “genetic similarity” between models from snippets of text - the metadata and model cards.
Models in the same finetuning family do resemble each other… but the evolution is weird. For example, traits drift in the same directions again and again.
14.08.2025 15:06 — 👍 1 🔁 0 💬 1 📌 0
We reconstructed model family trees by tracing fine-tunes, adaptations, quantizations and merges.
Some trees are small: one parent, a few children. Others sprawl into thousands of descendants across ten+ generations.
14.08.2025 15:06 — 👍 0 🔁 0 💬 1 📌 0

The 2500th, 250th, 50th, and 25th largest model families on Hugging Face. They show varying numbers of generations (between 3 and 8) and different edge types, including adapters, finetunes, merges, and quantizations.
In a new paper with @didaoh and Jon Kleinberg, we mapped the family trees of 1.86 million AI models on Hugging Face — the largest open-model ecosystem in the world.
AI evolution looks kind of like biology, but with some strange twists. 🧬🤖
14.08.2025 15:06 — 👍 31 🔁 9 💬 4 📌 2
This is just the start. We hope our dataset & methods open the door to a science of AI ecosystems.
If you care about open-source AI, governance, or the weird ways technology evolves, give it a read.
📄Paper: arxiv.org/pdf/2508.06811
14.08.2025 14:59 — 👍 1 🔁 0 💬 1 📌 0
The title page of our paper.
Big picture: By treating ML models like organisms in an ecosystem, we can:
🌱 Understand the pressures shaping AI development
🔍 Spot patterns before they become industry norms
🛠 Inform governance & safety strategies grounded in real data
14.08.2025 14:59 — 👍 1 🔁 0 💬 1 📌 0
A directed graph representing the typical direction of drift. For example, a directed edge pointing from gemma to mit suggests that more models mutate from gemma to mit than from mit to gemma. Color coding suggests that the general trend is commercial licenses mutate to other types of licenses. Of all creative commons licenses, the two most permissive varieties are downstream from those with more terms and restrictions.
We found optimal evolutionary orderings over traits:
🔹 Feature extraction tends to be upstream from text generation. Text generation is upstream from text classification.
🔹 Certain license types precede others (e.g., llama3 → apache-2.0)
Here we show the top-20 licenses transitions over fine-tunes.
14.08.2025 14:59 — 👍 0 🔁 0 💬 1 📌 0
The license drift to permissiveness suggests open-source preferences outweigh regulatory pressures to comply with licenses.
The English drift suggests a massive market for English products.
The docs drift could be explained as a preference for efficiency — or laziness.
14.08.2025 14:59 — 👍 0 🔁 0 💬 1 📌 0
Three major drifts we found:
1️⃣ Licenses: from corporate to other types. We often see use restrictions mutate to permissive or copyleft (even when counter to upstream license terms)
2️⃣ Languages: from multilingual → English-only
3️⃣ Docs: from long & detailed → short & templated
14.08.2025 14:59 — 👍 0 🔁 0 💬 1 📌 0
Some of our reported measurements showing that two related models have considerable more similarity in their data than any two (not-necessarily-related) models. Similarities are measured for pairs of models belonging to different subtree topologies. Interestingly, pairs of siblings are more related than parent-child pairs, even though they're further in distance over the tree. A diagram attempts to explain this as fast, directed mutation of traits.
In biology, traits get passed from parent to child — mutations are slow & often modeled as random.
In AI model families, mutations are fast and directed. Two sibling models tend to resemble each other more than they resemble their shared parent.
14.08.2025 14:59 — 👍 1 🔁 0 💬 1 📌 0
I think this technology is radically changing the practice of research. There are a billion research ethics questions it raises!
03.06.2025 12:52 — 👍 0 🔁 0 💬 0 📌 0
I used to think that AI prompting had no place in the research process and I was afraid to use AI for anything. Now, AI has permeated my paper-writing process, from brainstorming to code writing (eg, tab on cursor) to proof strategizing to LaTeX formatting to grammar checking and beyond.
03.06.2025 12:52 — 👍 1 🔁 0 💬 1 📌 0
Scientist, Inventor, author of the NTQR Python package for AI safety through formal verification of unsupervised evaluations. On a mission to eliminate Majority Voting from AI systems. E Pluribus Unum.
Assistant Professor at ASU WP Carey
website: https://papachristoumarios.github.io/
Opinions are my own.
Senior Lecturer (≡ associate professor) in applied maths, investigating the evolution and ecology of cancer. Dad of two small kids. On sabbatical @isemevol.bsky.social 🇫🇷 (otherwise @citystgeorges.bsky.social 🇬🇧)
robjohnnoble.github.io
MIT postdoc, incoming UIUC CS prof
katedonahue.me
Associate Professor, Yale Statistics & Data Science. Social networks, social and behavioral data, causal inference, mountains. https://jugander.github.io/
Machine-learning engineer and journalist, A.I. Initiatives @nytimes.com
My work: https://www.nytimes.com/by/dylan-freedman
Contact: dylan.freedman@nytimes.com, dylanfreedman.39 (Signal)
🏃🏻 🎹
Postdoc at UW NLP 🏔️. #NLProc, computational social science, cultural analytics, responsible AI. she/her. Previously at Berkeley, Ai2, MSR, Stanford. Incoming assistant prof at Wisconsin CS. lucy3.github.io/prospective-students.html
Assistant Professor at the University of Alberta. Amii Fellow. Human-centered privacy enhanced data science e.g., ML, MPC, PSI, etc.
My group is PUPS, Practical Usable Privacy and Security
https://bkacsmar.github.io//
Postdoctoral Fellow @ Princeton CITP. ex-Cornell PhD, future UIUC asst prof (fall 2026).
Looking at AI's impact on information ecosystems and news consumption. social computing, computational social science & journalism
mariannealq.com
Cornell Tech professor (information science, AI-mediated Communication, trustworthiness of our information ecosystem). New York City. Taller in person. Opinions my own.
PhD student at Cornell Tech | he/him | cities + equity + spatial everything | fan of cats and Taylor Swift | gsagostini.github.io
CS PhD student at Cornell Tech. Interested in interactions between algorithms and society. Princeton math '22.
kennypeng.me
she/her 🌈 PhD student in cs at Princeton researching ethics of algorithmic decision-making
https://www.poetryfoundation.org/poetry-news/63112/the-ford-faberge-by-marianne-moore
Postdoc @NYU Law and Cornell Tech. Writing about generative AI, copyright, and tech law >> katrinageddes.com
Technology policy expert; law professor: author and speaker.