🧠⚙️ Interested in decision theory+cogsci meets AI? Want to create methods for rigorously designing & evaluating human-AI workflows?
I'm recruiting PhDs to work on:
🎯 Stat foundations of multi-agent collaboration
🌫️ Model uncertainty & meta-cognition
🔎 Interpretability
💬 LLMs in behavioral science
05.11.2025 16:40 — 👍 30 🔁 13 💬 1 📌 0

I’m recruiting students this upcoming cycle at UIUC! I’m excited about Qs on societal impact of AI, especially human-AI collaboration, multi-agent interactions, incentives in data sharing, and AI policy/regulation (all from both a theoretical and applied lens). Apply through CS & select my name!
06.11.2025 18:52 — 👍 38 🔁 17 💬 1 📌 0

The ‘Worst Test in Medicine’ is Driving America’s High C-Section Rate
if you think about AI, healthcare, women's health, or all of the above, i highly recommend this article on the role of fetal heart rate monitors in the rise of C-sections:
www.nytimes.com/2025/11/06/h...
06.11.2025 18:32 — 👍 5 🔁 1 💬 0 📌 0
Super cool, and something I wish existed within machine learning for healthcare too! I'm often wondering what people are actually doing in practice and assembling evidence for my guesses.
03.11.2025 23:48 — 👍 4 🔁 0 💬 0 📌 0
Cornell University, Empire AI Fellows Program
Job #AJO30971, Postdoctoral Fellow, Empire AI Fellows Program, Cornell University, New York, New York, US
Cornell (NYC and Ithaca) is recruiting AI postdocs, apply by Nov 20, 2025! If you're interested in working with me on technical approaches to responsible AI (e.g., personalization, fairness), please email me.
academicjobsonline.org/ajo/jobs/30971
28.10.2025 18:19 — 👍 31 🔁 20 💬 1 📌 2
@michelleding.bsky.social has been doing amazing work laying out the complex landscape of "deepfake porn" and distilling the unique challenges in governing it. We hope this work informs future AI governance efforts to address the severe harms of this content - reach out to us to chat more!
25.04.2025 18:42 — 👍 4 🔁 2 💬 0 📌 0
p.s. we pronounce SSME as "Sesame" but you're welcome to your favorite pronunciation :)
17.10.2025 16:29 — 👍 0 🔁 0 💬 0 📌 0
Thanks also to our wonderful set of co-authors - Manish Raghavan (@manishraghav.bsky.social) , John Guttag, Bonnie Berger, and Emma Pierson (@emmapierson.bsky.social)-- without whom this work would not be possible!
17.10.2025 16:29 — 👍 1 🔁 0 💬 1 📌 0
Last but not least, thanks to @shuvoms.bsky.social,
who co-led this work with me, and is an excellent thinking partner. Collaborate with him if you can!!
17.10.2025 16:29 — 👍 0 🔁 0 💬 1 📌 0
The paper includes much more, including theoretical connections to the literature on semi-supervised mixture models. Lots of exciting directions ahead – come chat with me and Shuvom at NeurIPS this December in San Diego!
📄 Paper: arxiv.org/abs/2501.11866
💻 Code: github.com/divyashan/SSME
17.10.2025 16:29 — 👍 0 🔁 0 💬 1 📌 0
Across 8 tasks, 4 metrics, and dozens of classifiers, SSME consistently outperforms prior work, reducing estimation error by 5.1× vs. using labeled data alone and 2.4× vs. the next-best method!
17.10.2025 16:29 — 👍 0 🔁 0 💬 1 📌 0
SSME starts with a set of classifiers, unlabeled data, and bit of labeled data, and estimates the joint distribution of classifier scores and ground truth labels using a mixture model. SSME benefits from three sources of info: multiple classifiers, unlabeled data, and classifier scores.
17.10.2025 16:29 — 👍 0 🔁 0 💬 1 📌 0

New #NeurIPS2025 paper: how should we evaluate machine learning models without a large, labeled dataset? We introduce Semi-Supervised Model Evaluation (SSME), which uses labeled and unlabeled data to estimate performance! We find SSME is far more accurate than standard methods.
17.10.2025 16:29 — 👍 22 🔁 7 💬 1 📌 3
thank you, gabriel!! glad i've gotten to learn so much about maps from you :')
15.10.2025 01:57 — 👍 2 🔁 0 💬 0 📌 0
thank you, Erica 🥹 so glad we got to work together this year!
14.10.2025 17:59 — 👍 1 🔁 0 💬 0 📌 0
thank you, Emma!!! likewise, i'm so grateful for our collaborations over the years!
14.10.2025 16:10 — 👍 1 🔁 0 💬 0 📌 0
thank you, Kenny!!! that's so nice of you to say.
14.10.2025 16:03 — 👍 0 🔁 0 💬 0 📌 0
Divya Shanmugam
personal website
for an up-to-date review of recent and ongoing work, you can learn more at dmshanmugam.github.io :)
14.10.2025 15:55 — 👍 0 🔁 0 💬 0 📌 0
I'll be at INFORMS, ML4H, and NeurIPS later this year, presenting on recent work related to challenges of imperfect data & models in healthcare (and what we can do about them) -- more on these pieces of work soon!!
14.10.2025 15:54 — 👍 0 🔁 0 💬 1 📌 0
I am on the job market this year! My research advances methods for reliable machine learning from real-world data, with a focus on healthcare. Happy to chat if this is of interest to you or your department/team.
14.10.2025 15:45 — 👍 27 🔁 12 💬 2 📌 4
Urban Data Science & Equitable Cities | EAAMO Bridges
EAAMO Bridges Urban Data Science & Equitable Cities working group: biweekly talks, paper studies, and workshops on computational urban data analysis to explore and address inequities.
Are you a researcher using computational methods to understand cities?
@mfranchi.bsky.social @jennahgosciak.bsky.social and I organize an EAAMO Bridges working group on Urban Data Science and we are looking for new members!
Fill the interest form on our page: urban-data-science-eaamo.github.io
03.09.2025 15:05 — 👍 8 🔁 8 💬 1 📌 1
can't recommend highly enough!
22.08.2025 15:42 — 👍 2 🔁 0 💬 0 📌 0
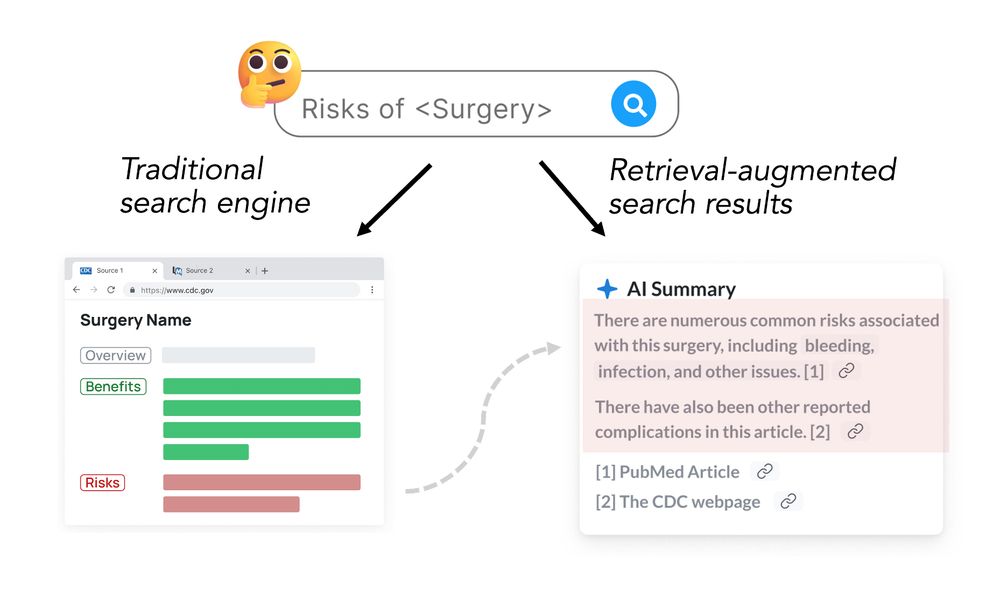
A person searching for risks of surgery. A traditional search engine would surface websites that would likely include both pros and cons of the surgery. However, RAG results only excerpt the cons.
Excited to be at #ICML2025 to present our paper on 'pragmatic misalignment' in (deployed!) RAG systems: narrowly "accurate" responses that can be profoundly misinterpreted by readers.
It's especially dangerous for consequential domains like medicine! arxiv.org/pdf/2502.14898
15.07.2025 17:15 — 👍 13 🔁 2 💬 0 📌 1

A poster for the paper "Position: Strong Consumer Protection is an Inalienable Defense for AI Safety in the United States"
I'll be presenting a position paper about consumer protection and AI in the US at ICML. I have a surprisingly optimistic take: our legal structures are stronger than I anticipated when I went to work on this issue in Congress.
Is everything broken rn? Yes. Will it stay broken? That's on us.
14.07.2025 13:01 — 👍 19 🔁 5 💬 1 📌 0

"Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese" Abstract:
While the capabilities of Large Language Models (LLMs) have been studied in both Simplified and Traditional Chinese, it is yet unclear whether LLMs exhibit differential performance when prompted in these two variants of written Chinese. This understanding is critical, as disparities in the quality of LLM responses can perpetuate representational harms by ignoring the different cultural contexts underlying Simplified versus Traditional Chinese, and can exacerbate downstream harms in LLM-facilitated decision-making in domains such as education or hiring. To investigate potential LLM performance disparities, we design two benchmark tasks that reflect real-world scenarios: regional term choice (prompting the LLM to name a described item which is referred to differently in Mainland China and Taiwan), and regional name choice (prompting the LLM to choose who to hire from a list of names in both Simplified and Traditional Chinese). For both tasks, we audit the performance of 11 leading commercial LLM services and open-sourced models -- spanning those primarily trained on English, Simplified Chinese, or Traditional Chinese. Our analyses indicate that biases in LLM responses are dependent on both the task and prompting language: while most LLMs disproportionately favored Simplified Chinese responses in the regional term choice task, they surprisingly favored Traditional Chinese names in the regional name choice task. We find that these disparities may arise from differences in training data representation, written character preferences, and tokenization of Simplified and Traditional Chinese. These findings highlight the need for further analysis of LLM biases; as such, we provide an open-sourced benchmark dataset to foster reproducible evaluations of future LLM behavior across Chinese language variants (this https URL).
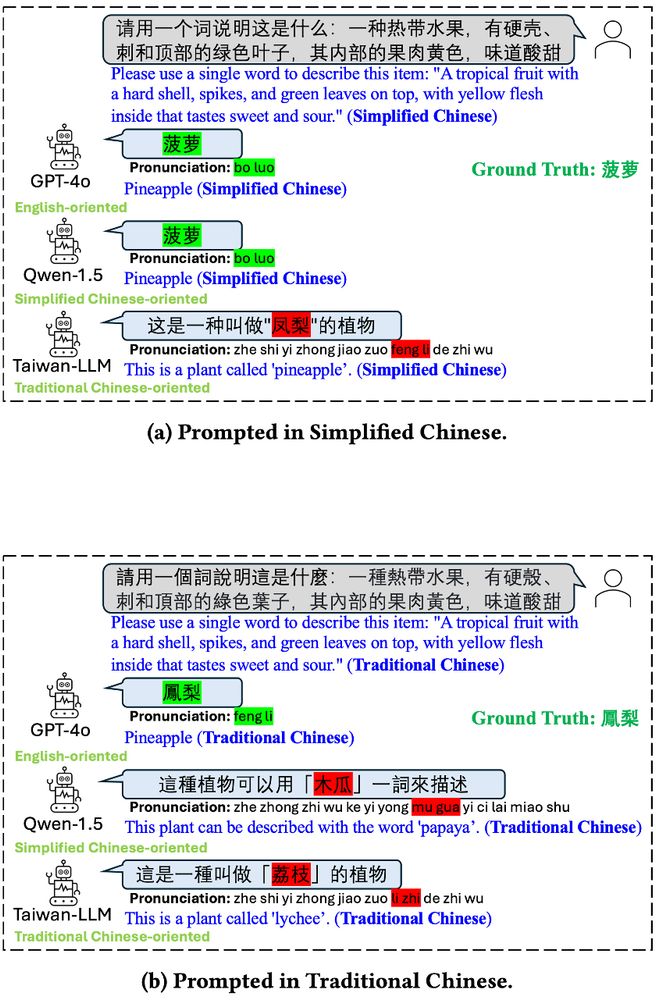
Figure showing that three different LLMs (GPT-4o, Qwen-1.5, and Taiwan-LLM) may answer a prompt about pineapples differently when asked in Simplified Chinese vs. Traditional Chinese.
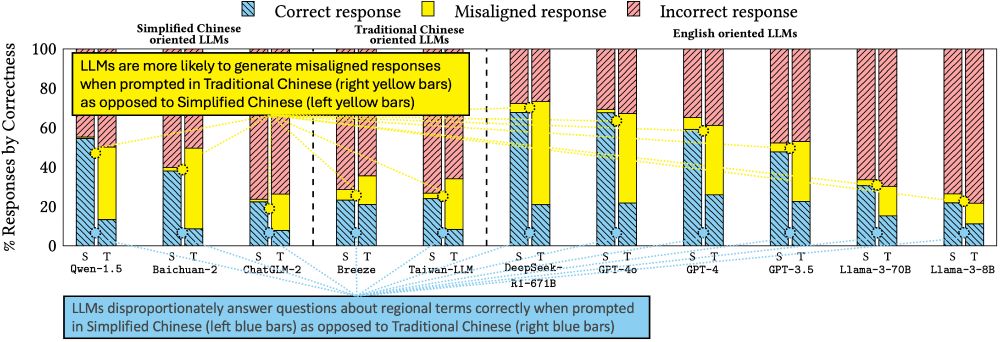
Figure showing that LLMs disproportionately answer questions about regional-specific terms (like the word for "pineapple," which differs in Simplified and Traditional Chinese) correctly when prompted in Simplified Chinese as opposed to Traditional Chinese.
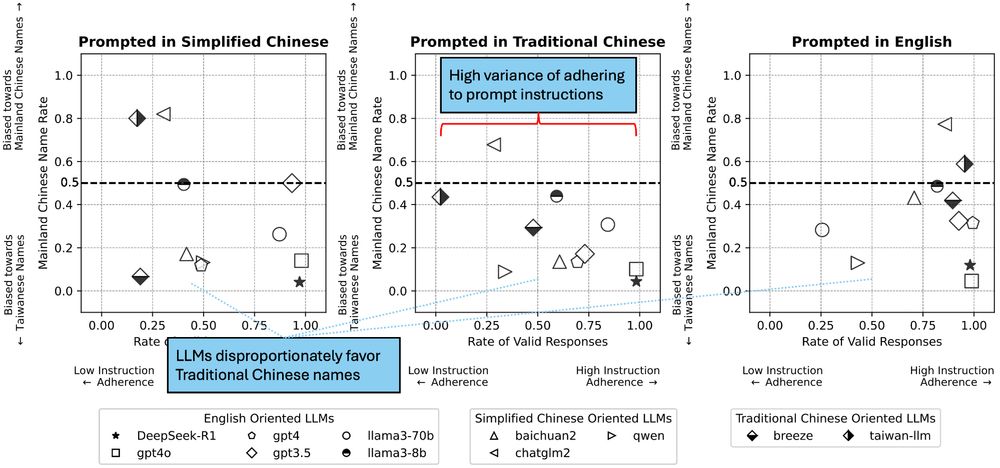
Figure showing that LLMs have high variance of adhering to prompt instructions, favoring Traditional Chinese names over Simplified Chinese names in a benchmark task regarding hiring.
🎉Excited to present our paper tomorrow at @facct.bsky.social, “Characterizing Bias: Benchmarking Large Language Models in Simplified versus Traditional Chinese”, with @brucelyu17.bsky.social, Jiebo Luo and Jian Kang, revealing 🤖 LLM performance disparities. 📄 Link: arxiv.org/abs/2505.22645
22.06.2025 21:15 — 👍 17 🔁 4 💬 1 📌 3
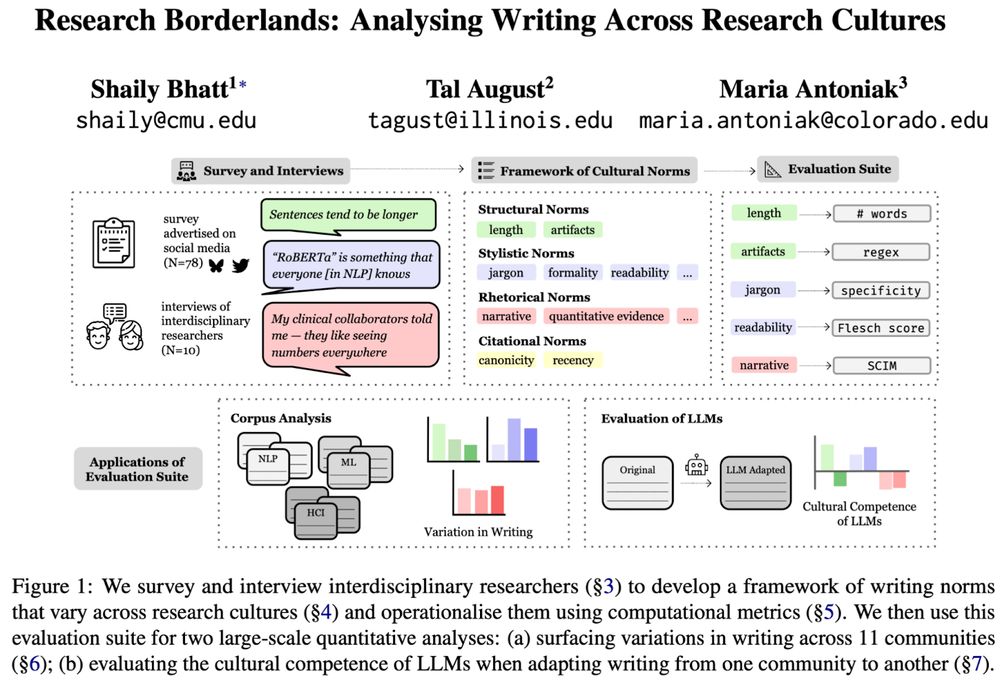
An overview of the work “Research Borderlands: Analysing Writing Across Research Cultures” by Shaily Bhatt, Tal August, and Maria Antoniak. The overview describes that We survey and interview interdisciplinary researchers (§3) to develop a framework of writing norms that vary across research cultures (§4) and operationalise them using computational metrics (§5). We then use this evaluation suite for two large-scale quantitative analyses: (a) surfacing variations in writing across 11 communities (§6); (b) evaluating the cultural competence of LLMs when adapting writing from one community to another (§7).
🖋️ Curious how writing differs across (research) cultures?
🚩 Tired of “cultural” evals that don't consult people?
We engaged with interdisciplinary researchers to identify & measure ✨cultural norms✨in scientific writing, and show that❗LLMs flatten them❗
📜 arxiv.org/abs/2506.00784
[1/11]
09.06.2025 23:29 — 👍 74 🔁 30 💬 1 📌 5
and... here is the actual GIF 🙈
14.06.2025 17:04 — 👍 3 🔁 1 💬 0 📌 0
it brings me tremendous joy you noticed!!!
14.06.2025 15:05 — 👍 0 🔁 0 💬 0 📌 0
Last but not least, thanks to Helen Lu, @swamiviv1, and John Guttag, my wonderful collaborators on this work! One of my last from the PhD 🥹
14.06.2025 15:00 — 👍 1 🔁 0 💬 0 📌 0
Official social media for the Urban Data working group. Researchers at the intersection of data, cities, people, and space. Read more and join us at https://urban-data-science-eaamo.github.io
Yale SOM professor & Bulls fan. I study consumer finance, and econometrics is a big part of my research identity. He/him/his
Assistant prof at Columbia IEOR developing AI for decision-making in planetary health.
https://lily-x.github.io
PhD Student in Social Data Science, University of Copenhagen
AI & Society | Algorithmic Fairness | ML | Education Data Science
https://tereza-blazkova.github.io/
PhD student at Columbia University working on human-AI collaboration, AI creativity and explainability. prev. intern @GoogleDeepMind, @AmazonScience
asaakyan.github.io
I’m not like the other Bayesians. I’m different.
Thinks about philosophy of science, AI ethics, machine learning, models, & metascience. postdoc @ Princeton.
PhD student @ Northeastern University, Clinical NLP
https://hibaahsan.github.io/
she/her
Information Science PhD student at Cornell
MIT postdoc, incoming UIUC CS prof
katedonahue.me
Postdoc @ UC Berkeley. 3D Vision/Graphics/Robotics. Prev: CS PhD @ Stanford.
janehwu.github.io
AI/ML, Responsible AI @Nvidia
Associate Professor in EECS at MIT. Neural nets, generative models, representation learning, computer vision, robotics, cog sci, AI.
https://web.mit.edu/phillipi/
Health policy, technology, labor, and democracy.
Political economy of health & collective governance for tech.
MD/MPH. He/him/his. ਸਰਬੱਤ ਦਾ ਭਲਾ
Let’s build a healthier world together!
PGY3 @uofa_neurology | Visiting Scientist @mitcriticaldata | MSc @ihpmeuoft | MD @uoftmedicine | trying to fix the medical knowledge system
Safe and robust AI/ML, computational sustainability. Former President AAAI and IMLS. Distinguished Professor Emeritus, Oregon State University. https://web.engr.oregonstate.edu/~tgd/
Senior Research Scientist @MBZUAI. Focused on decision making under uncertainty, guided by practical problems in healthcare, reasoning, and biology.