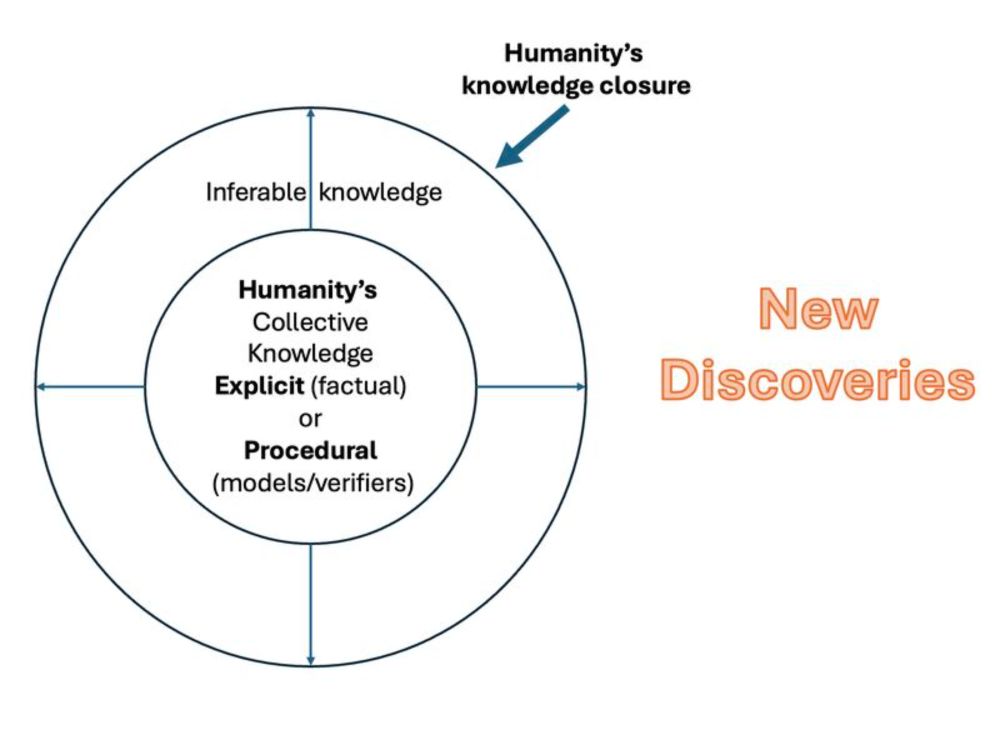
Does it really make sense to think of inference efficiency in terms of the number of tokens produced?
No. 👇
x.com/i/status/202...
16.02.2026 20:39 —
👍 2
🔁 0
💬 2
📌 0
Sorry, but I think you miss the point that most of the reasoning model revolution came exactly for tasks where there are verifiers--whether external/symbolic, or learned, or even hand-coded simulators. What do you think RLVR or Self Distillation are?
14.02.2026 04:25 —
👍 1
🔁 0
💬 1
📌 0
The lectures, 3hrs long with Q&A, are quite up-to-date and cover LLMs, LRMs, as well as the latest test-time scaling and post-training methods such as LLM-Process-Modulo and self-distillation.
13.02.2026 15:31 —
👍 2
🔁 0
💬 0
📌 0


Here are the recordings of two lectures on 𝗣𝗹𝗮𝗻𝗻𝗶𝗻𝗴 & 𝗥𝗲𝗮𝘀𝗼𝗻𝗶𝗻𝗴 𝗖𝗮𝗽𝗮𝗯𝗶𝗹𝗶𝘁𝗶𝗲𝘀 𝗼𝗳 𝗟𝗟𝗠𝘀/𝗟𝗥𝗠𝘀 that I gave this week at Melbourne ML Summer School (lnkd.in/g7rxg9sw).
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 1: youtube.com/watch?v=_PPV...
𝙇𝙚𝙘𝙩𝙪𝙧𝙚 2: youtube.com/watch?v=fKlm...
13.02.2026 15:31 —
👍 6
🔁 0
💬 1
📌 1
YouTube video by Subbarao Kambhampati
Anthropomorphization Sins in Modern AI (or Perils of Prematurely Applying Lens of Cognition to LLMs)
A common theme in our work these past few years has been pushing back on facile anthropomorphizations (and/or efforts that bring questionable/discredited Cognitive Science metaphors) to LLMs.. So I enjoyed giving this talk at @ivado.bsky.social yesterday... www.youtube.com/watch?v=CoyS...
28.01.2026 13:03 —
👍 4
🔁 0
💬 1
📌 0
YouTube video by Subbarao Kambhampati
On the Mythos of LRM "Thinking Tokens" (Talk @ Microsoft Research, India; 12/16/2025)
Three of my talks in India last month--at @iitdelhi.bsky.social,
@msftresearch.bsky.social India and at IndoML Symposium--were "On the Mythos of LRM Thinking Tokens." Here is a recording of one of them--the talk I gave at MSR India.
www.youtube.com/watch?v=fCQX...
06.01.2026 21:44 —
👍 0
🔁 0
💬 0
📌 0

Like I say, if a human--even a Terence Tao--makes an egregious mistake (e.g. the one below) once, our trust in them takes a nose dive. With LLMs, it is just "..but they do so well on IMO problems!"..
28.12.2025 15:23 —
👍 11
🔁 2
💬 2
📌 0
YouTube video by Subbarao Kambhampati
Talk on the semantics of "Thinking Traces" (Keynote at NeurIPS2025 MAR Workshop)
ICYMI, here is my keynote on the semantics of LRM "thinking traces" at #NeurIPS2025 workshop on Multimodal Algorithmic Reasoning. It's a unified view of the seven papers we presented at the conference workshops. Special thanks to the engaged audience..🙏
www.youtube.com/watch?v=rvby...
09.12.2025 13:11 —
👍 1
🔁 0
💬 0
📌 0

[On using Continuous Latent Space Vectors in the context windows of Transformers and LLMs] #SundayHarangue
👉 x.com/rao2z/status...
03.11.2025 15:16 —
👍 2
🔁 0
💬 0
📌 0
YouTube video by Subbarao Kambhampati
LRMs and Agentic AI (Talk at Samsung AI Forum)
My talk at Samsung AI Forum yesterday
www.youtube.com/watch?v=L2nA...
16.09.2025 17:39 —
👍 2
🔁 0
💬 0
📌 0

𝐏𝐞𝐫𝐟𝐨𝐫𝐦𝐚𝐭𝐢𝐯𝐞 𝐓𝐡𝐢𝐧𝐤𝐢𝐧𝐠? The anthropomorphization of LRM intermediate tokens as thinking begat a cottage industry to "get efficiency by shortening thinking." We ask: 𝗜𝘀 𝗖𝗼𝗧 𝗹𝗲𝗻𝗴𝘁𝗵 𝗿𝗲𝗮𝗹𝗹𝘆 𝗮 𝗿𝗲𝗳𝗹𝗲𝗰𝘁𝗶𝗼𝗻 𝗼𝗳 𝗽𝗿𝗼𝗯𝗹𝗲𝗺 𝗵𝗮𝗿𝗱𝗻𝗲𝘀𝘀 𝗼𝗿 𝗶𝘀 𝗶𝘁 𝗺𝗼𝗿𝗲 𝗽𝗲𝗿𝗳𝗼𝗿𝗺𝗮𝘁𝗶𝘃𝗲? 👉 www.linkedin.com/posts/subbar...
10.09.2025 16:50 —
👍 6
🔁 0
💬 0
📌 1

Computational Complexity is the wrong measure for LRMs (as it was for LLMs)--think distributional distance instead #SundayHarangue (yes, we're back!)
👉 x.com/rao2z/status...
13.07.2025 21:42 —
👍 2
🔁 0
💬 0
📌 0
A̶̶̶I̶̶̶ ̶ ̶ ̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶G̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶G̶e̶n̶e̶r̶a̶l̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)̶
̶̶̶A̶̶̶S̶̶̶I̶̶̶ ̶(̶A̶r̶t̶i̶f̶i̶c̶i̶a̶l̶ ̶S̶u̶p̶e̶r̶ ̶I̶n̶t̶e̶l̶l̶i̶g̶e̶n̶c̶e̶)
ASDI (Artificial Super Duper Intelligence)
Don't get stuck with yesterday's hypeonyms!
Dare to get to the next level!
#AIAphorisms
23.06.2025 22:36 —
👍 3
🔁 1
💬 0
📌 0

The lectures start with a "big picture" overview (Lecture 1); focus on standard LLMs and their limitations, and LLM-Modulo as a test-time scaling approach (Lecture 2); and end with a critical appraisal of the test-time scaling and RL post-training techniques (Lecture 3). 2/
19.06.2025 22:27 —
👍 0
🔁 0
💬 1
📌 0

ACDL Summer School Lectures on Planning/Reasoning Abilities of LLMs/LRMs - YouTube
For anyone interested, here are the videos of the three ~50min each lectures on the reasoning/planning capabilities of LLMs/LRMs that I gave at #ACDL2025 in Riva Del Sole resort last week. 1/
www.youtube.com/playlist?lis...
19.06.2025 22:27 —
👍 3
🔁 2
💬 1
📌 0
...it basically confirmed what is already well-established: LLMs (& LRMs & "LLM agents") have trouble w/ problems that require many steps of reasoning/planning.
See, e.g., lots of recent papers by Subbarao Kambhampati's group at ASU. (2/2)
09.06.2025 22:53 —
👍 52
🔁 5
💬 2
📌 0
An AGI-wannabe reasoning model whining that it couldn't handle a problem because its context window isn't big enough is like a superman-wannabe little kid protesting that he couldn't add those numbers because he doesn't have enough fingers and toes.. #AIAphorisms
16.06.2025 00:47 —
👍 3
🔁 0
💬 0
📌 0

Lucas Saldyt on X: "Neural networks can express more than they learn, creating expressivity-trainability gaps. Our paper, “Mind The Gap,” shows neural networks best learn parallel algorithms, and analyzes gaps in faithfulness and effectiveness. @rao2z https://t.co/8YjxPkXFu0" / X
Neural networks can express more than they learn, creating expressivity-trainability gaps. Our paper, “Mind The Gap,” shows neural networks best learn parallel algorithms, and analyzes gaps in faithfulness and effectiveness. @rao2z https://t.co/8YjxPkXFu0
The transformer expressiveness results are often a bit of a red herring as there tends to be a huge gap between what can be expressed in transformers, and what can be learned with gradient descent. Mind the Gap, a new paper with
Lucas Saldyt dives deeper into this issue 👇👇
x.com/SaldytLucas/...
30.05.2025 13:59 —
👍 3
🔁 0
💬 0
📌 1

Anthropomorphization of intermediate tokens as reasoning/thinking traces isn't quite a harmless fad, and may be pushing LRM research into questionable directions.. So we decided to put together a more complete argument. Paper 👉 arxiv.org/pdf/2504.09762 (Twitter thread: x.com/rao2z/status...)
28.05.2025 13:41 —
👍 10
🔁 1
💬 0
📌 1

This RLiNo? paper (arxiv.org/abs/2505.13697) lead by Soumya Samineni and Durgesh_kalwar dives into the MDP model used in the RL post-training methods inspired by DeepSeek R1, and asks if some of the idiosyncrasies of RL aren't just consequences of the simplistic structural assumptions made
25.05.2025 22:51 —
👍 4
🔁 0
💬 1
📌 0

Do Intermediate Tokens Produced by LRMs (need to) have any semantics? Our new study 👇
Thread 👉 x.com/rao2z/status...
21.05.2025 20:08 —
👍 8
🔁 0
💬 2
📌 0