a man in a suit is making a funny face and says `` mind blown '' while standing in a bar .
ALT: a man in a suit is making a funny face and says `` mind blown '' while standing in a bar .
🧵1/12 What if the DMN, limbic system, hippocampus, neural oscillations, gradients, dementia syndromes, mixed pathology, and aphantasia all fall out of the same generative brain computation? 🤯#endalz
Introducing #SLOD (preprint): a new #NeuroAI framework w/ @drbreaky.bsky.social
18.01.2026 21:38 — 👍 17 🔁 9 💬 1 📌 3

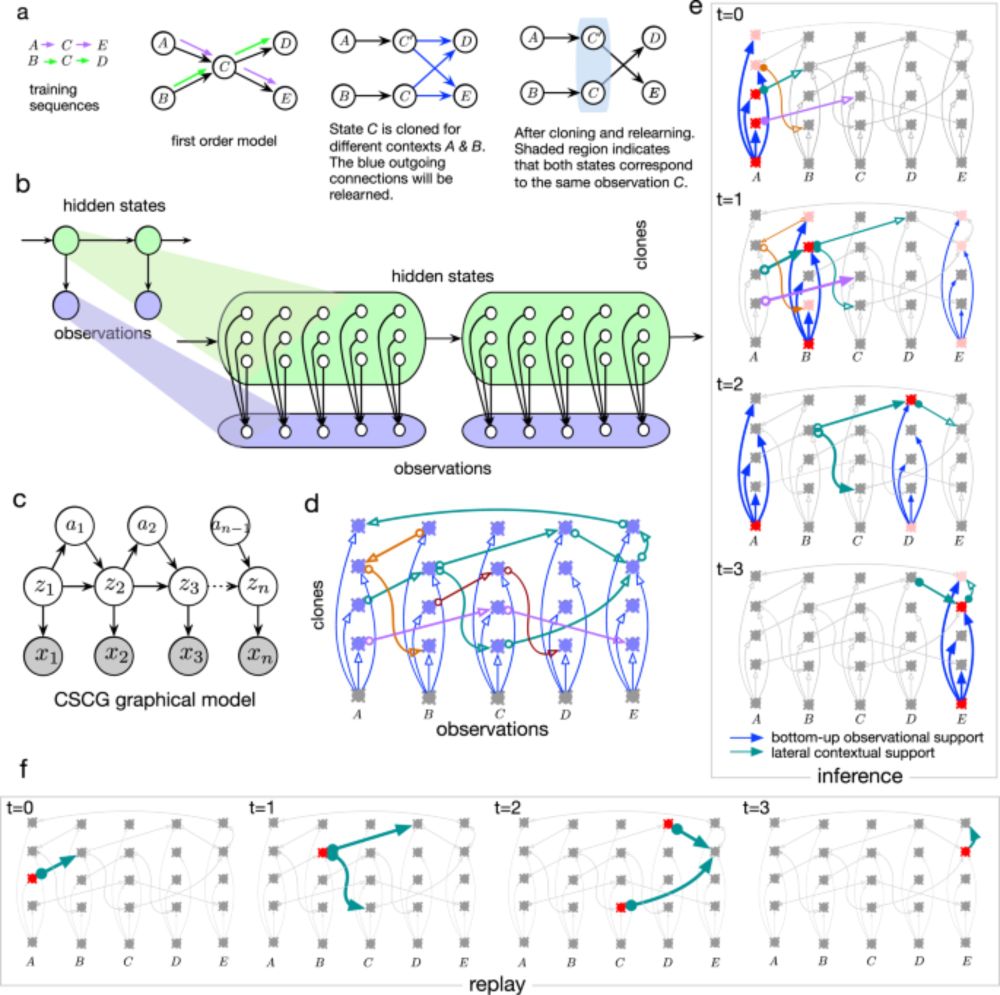
6/12 The clone-structured cognitive graph (CSCG) framework pioneered by @dileeplearning.bsky.social offers a natural computational mapping for how latent diffusion could be implemented biologically along hippocampal circuitry.
18.01.2026 21:38 — 👍 3 🔁 1 💬 1 📌 0
On cognitive maps, LLMs, world models, and understanding
No abstract available.
4/4 “Language is a mechanism to control other people’s mental simulations.” Dileep George, @dileeplearning, of @GoogleDeepMind at the Simons Institute workshop on The Future of Language Models and Transformers. Video: simons.berkeley.edu/talks/dileep...
27.12.2025 13:53 — 👍 3 🔁 1 💬 0 📌 0

1/4 Do LLMs understand? "They understand in a way that’s very different from how humans understand," Dileep George, @dileeplearning.bsky.social, of Google DeepMind at the Simons Institute workshop on The Future of Language Models and Transformers. Video: simons.berkeley.edu/talks/dileep...
27.12.2025 13:53 — 👍 17 🔁 1 💬 1 📌 0

Quick notes from vibe-coding a comic website
Hate less, vibe more!
blog.dileeplearning.com/p/quick-note...
TLDR: It was fun and the process felt 'magical' at times. If you have lots of small project ideas you want to prototype, vibe-coding is a fun way to do that as long as you are willing to settle for 'good enough'.
20.10.2025 16:19 — 👍 4 🔁 0 💬 0 📌 0

AGI Comics — #1: Artificial General Productivity
A comic series.
New and improved and 10000% vibe-coded! Check out www.agicomics.net
20.10.2025 00:25 — 👍 1 🔁 0 💬 0 📌 0

Paradigms of Intelligence Team
Advance our understanding of how intelligence evolves to develop new technologies for the benefit of humanity and other sentient life - Paradigms of Intelligence Team
1/4) I’m excited to announce that I have joined the Paradigms of Intelligence team at Google (github.com/paradigms-of...)! Our team, led by @blaiseaguera.bsky.social, is bringing forward the next stage of AI by pushing on some of the assumptions that underpin current ML.
#MLSky #AI #neuroscience
23.09.2025 15:06 — 👍 180 🔁 11 💬 23 📌 2
Jesus Christ.
17.09.2025 17:46 — 👍 3504 🔁 1392 💬 47 📌 51
Yes, it counts.
18.09.2025 05:56 — 👍 1 🔁 0 💬 0 📌 0
1/
🚨 New preprint! 🚨
Excited and proud (& a little nervous 😅) to share our latest work on the importance of #theta-timescale spiking during #locomotion in #learning. If you care about how organisms learn, buckle up. 🧵👇
📄 www.biorxiv.org/content/10.1...
💻 code + data 🔗 below 🤩
#neuroskyence
17.09.2025 19:32 — 👍 132 🔁 56 💬 10 📌 6
Thank you! Looks like I was able to fix it by adding one more rule to the domain forwarding setup at squarespace.
17.09.2025 18:00 — 👍 1 🔁 0 💬 1 📌 0
Hmmm….i need to vibe fix this….tomorrow!
17.09.2025 10:11 — 👍 1 🔁 0 💬 1 📌 0

AGI Comics — #23: Artificial General Productivity
A comic series.
#AGIComics now has a website! And it is 100% vibe coded!
Check out agicomics.net
17.09.2025 10:01 — 👍 11 🔁 1 💬 2 📌 0

Illustration of the brain in blue and yellow
12 leading neuroscientists tackle a big question: Will we ever understand the brain?
Their reflections span philosophy, complexity, and the limits of scientific explanation.
www.sainsburywellcome.org/web/blog/wil...
Illustration by @gilcosta.bsky.social & @joanagcc.bsky.social
06.08.2025 08:41 — 👍 15 🔁 3 💬 2 📌 2
🎯
05.06.2025 21:53 — 👍 11 🔁 2 💬 0 📌 0
Ohh ok I realize that @tyrellturing.bsky.social mentioned evolution. Fine then. But then which neuroscientist believes this?
15.05.2025 18:04 — 👍 3 🔁 0 💬 1 📌 0
Hmm…I don’t think it’s impossible.
Evolution could create structures in the brain that are in correspondence with structure in the world.
15.05.2025 18:02 — 👍 5 🔁 1 💬 1 📌 0

Good conclusion :-).
15.05.2025 01:22 — 👍 1 🔁 0 💬 1 📌 0

somehow chatGPT understand my opinion about successor representations? 4/
15.05.2025 01:22 — 👍 0 🔁 0 💬 1 📌 0

I didn't mention partial observability specifically, so it is impressive that this was picked up. Looks like we did something right in our CSCG paper in making this explicit? 3/
15.05.2025 01:22 — 👍 0 🔁 0 💬 1 📌 0

It is quite impressive that chatGPT picked up these nuances, picks up a relevant quote from the paper and even emphasizes portions of the response. 2/
15.05.2025 01:22 — 👍 0 🔁 0 💬 1 📌 0

This paper turned up on a feed, I was intrigued by it and started reading...
..but then I was quite baffled because our CSCG work seem to have tackled many of these problems in a more general setting and it's not even mentioned!
So I asked ChatGPT... ...I'm impressed by the answer1. 1/🧵
15.05.2025 01:22 — 👍 11 🔁 1 💬 1 📌 0

Wow, very cool to see this work from Alla Karpova's lab. She had shown me the results when I visited @hhmijanelia.bsky.social and I was blown away.
www.biorxiv.org/content/10.1...
1/
29.04.2025 00:05 — 👍 33 🔁 5 💬 1 📌 0
Assistant Professor at UCLA | Alum @MIT @Princeton @UC Berkeley | AI+Cognitive Science+Climate Policy | https://ucla-cocopol.github.io/
Co-founder at Asana and Good Ventures (a funding partner of Coefficient Giving). Meta delenda est. Strange looper.
HHMI’s Janelia Research Campus in Ashburn, Virginia, is innovating research practices and technologies to solve biology’s deepest mysteries. https://www.janelia.org/
Associate Professor @UvA_Amsterdam | Cognitive neuroscience, Scene perception, Computational vision | Chair of CCN2025 | www.irisgroen.com
Associate prof & cognitive neurophysiologist at Dartmouth. www.vandermeerlab.org, https://scholar.google.com/citations?user=cGMeE7UAAAAJ&hl=en
Mastodon: @nafnlaus@fosstodon.org
Twitter: @enn_nafnlaus
URL: https://softmaxdroptableartists.bandcamp.com/
#Energy #EVs #Ukraine #AI #Horticulture #Research
Applied Mathematician
Macro data refinement scientist
https://kslote1.github.io
Everyone should care.
My opinions are my own
Professor, Stanford
Vision Neuroscientist
Interested on how the interplay between brain function, structure & computations enables visual perception; and also what are we born with and what develops.
Scientist, AI researcher, roboticist, professor emeritus. Coauthor “Artificial Intelligence: Foundations of Computational Agents” http://artint.info 🇨🇦
Consultant, Science and Innovation. Munich. Formerly neuroscientist @ MIT, PhD @ MPI Frankfurt, Germany.
AGI safety researcher at Google DeepMind, leading causalincentives.com
Personal website: tomeveritt.se
Neuroscientist at University College London (www.ucl.ac.uk/cortexlab). Opinions my own.
Systems neuroscientist. Assistant Professor at
Cornell. Studying the computational and circuit mechanisms of learning, memory and natural behaviors in rodents
Computational and systems neuroscience. DeepRL Hippocampus navigation <- Data analysis / neural network modelling PFC working memory flexible cognition.
xiaoxionglin.com
https://www.bcf.uni-freiburg.de/about/people/lin
github.com/xiaoxionglin/dSCA
EU High Representative for Foreign Affairs and Security Policy
Vice-President of the European Commission
Evolution: it's nothing personal. (Sorry if I ask too many questions... Share nicely!)
I'm here because you're here.
http://pabloredux.wordpress.com/
(Profile photo: a faint shadow of me cast across a weathered lichen-marked stone wall by the sea.)
Neuroscientist, psychologist, and author of "Seven and a Half Lessons About the Brain" (an Amazon "Best Book") and "How Emotions are Made." LisaFeldmanBarrett.com
Cognitive scientist at Carnegie Mellon University and External Faculty at the Santa Fe Institute. http://santafe.edu/~simon