The best part? LinEAS works on LLMs & T2I models.
Huge thanks to the team: Michal Klein, Eleonora Gualdoni, Valentino Maiorca, Arno Blaas, Luca Zappella, Marco Cuturi, & Xavier Suau (who contributed like a 1st author too🥇)!
💻https://github.com/apple/ml-lineas
📄https://arxiv.org/abs/2503.10679
21.10.2025 10:00 — 👍 0 🔁 0 💬 0 📌 0

Sparsity improves utility while mitigating toxicity. Toxicity results on Qwen2.5-7B using only 32 sentences, at different levels of sparsity γ that result in different support sizes (x axis). At 1K optimization steps, with a support of about 1% we maintain similar toxicity (left, center-left) while PPLWIK decreases (center-right) and MMLU increases (right). Note that too long optimizations (10k steps) might harm utility, due to overfitting. Similarly, short optimizations (e.g., 100 steps) and strong sparsity leads to low conditioning (mild toxicity mitigation).
LinEAS globally 🌐 optimizes all 1D-Wasserstein distances between source and target activation distributions at multiple layers via backprop. ✨ Bonus: we can now add a sparsity objective. The result? Targeted 🎯 interventions that preserve fluency with strong conditioning!
21.10.2025 10:00 — 👍 0 🔁 0 💬 1 📌 0
Existing methods estimate layer-wise 🥞 interventions. While powerful, layer-wise methods have some approximation error since the optimization is done locally, without considering multiple layers at once 🤔. We circumvent this problem in LinEAS with an end-to-end optimization ⚙️!
21.10.2025 10:00 — 👍 0 🔁 0 💬 1 📌 0

LinEAS learns lightweight maps to steer pretrained model activations. With LinEAS, we gain fine-grained control on text-to-image generation to induce precise styles (in the figure) or remove objects. The same procedure also allows controlling LLMs.
🦊Activation Steering modifies a model's internal activations to control its output. Think of a slider 🎚️ that gradually adds a concept, like art style 🎨 to the output. This is also a powerful tool for safety, steering models away from harmful content.
21.10.2025 10:00 — 👍 0 🔁 0 💬 1 📌 0
🚀 Excited to share LinEAS, our new activation steering method accepted at NeurIPS 2025! It approximates optimal transport maps e2e to precisely guide 🧭 activations achieving finer control 🎚️ with ✨ less than 32 ✨ prompts!
💻https://github.com/apple/ml-lineas
📄https://arxiv.org/abs/2503.10679
21.10.2025 10:00 — 👍 2 🔁 1 💬 1 📌 1

Our two phenomenal interns, Alireza Mousavi-Hosseini and Stephen Zhang @syz.bsky.social have been cooking some really cool work with Michal Klein and me over the summer.
Relying on optimal transport couplings (to pick noise and data pairs) should, in principle, be helpful to guide flow matching
🧵
03.10.2025 20:50 — 👍 30 🔁 7 💬 2 📌 1
Our work on fine-grained control of LLMs and diffusion models via Activation Transport will be presented @iclr_conf as spotlight✨Check out our new blog post machinelearning.apple.com/research/tra...
11.04.2025 06:58 — 👍 7 🔁 1 💬 0 📌 1
YouTube video by Deep Learning Barcelona
Què és l'aprenentatge profund ? - La Dimoni de Maxwell #deeplearning #ciencia #català #barcelona
Què és l’aprenentatge profund ?
La @marionamec.bsky.social de @neurofregides.bsky.social ens ho explica en motiu del Deep Learning Barcelona Symposium 2024 (@dlbcn.ai), aquest dijous 19 de desembre.
#deeplearning #ciencia #català #barcelona
www.youtube.com/shorts/R4u_Z...
16.12.2024 08:49 — 👍 7 🔁 3 💬 0 📌 1
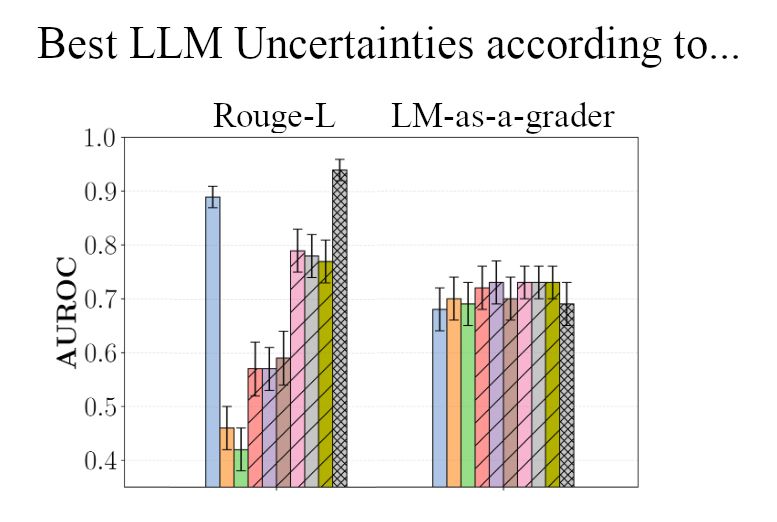
Evaluating your LLM uncertainties with Rougle-L will show clear winners... except that they aren't actually good. We find that Rouge-L spuriously favors some methods over others. 🧵1/4
📄 openreview.net/forum?id=jGt...
NeurIPS: Sunday, East Exhibition Hall A, Safe Gen AI workshop
12.12.2024 11:36 — 👍 7 🔁 3 💬 1 📌 1
Kudos to all co-authors 👏 Arno Blaas, Michal Klein, Luca Zappella, Nicholas Apostoloff, Marco Cuturi, and Xavier Suau.
Extra 👏 to Xavi for making this so great! Like a friend would say, he's the Rolls-Royce of the co-authors, and he should be regarded the first author too!
10.12.2024 13:09 — 👍 2 🔁 0 💬 0 📌 0
Summary:
🤝 Unifying activation steering w/ OT.
✨ Linear-AcT preserves distributions w/ interpretable ([0, 1]) strength.
💪 Robust: models/layers/modalities
💬 LLMs: toxicity mitigation, truthfulness and concept induction,
🌄 T2I: style induction and concept negation.
🚀 Negligible cost!
10.12.2024 13:09 — 👍 3 🔁 0 💬 1 📌 0
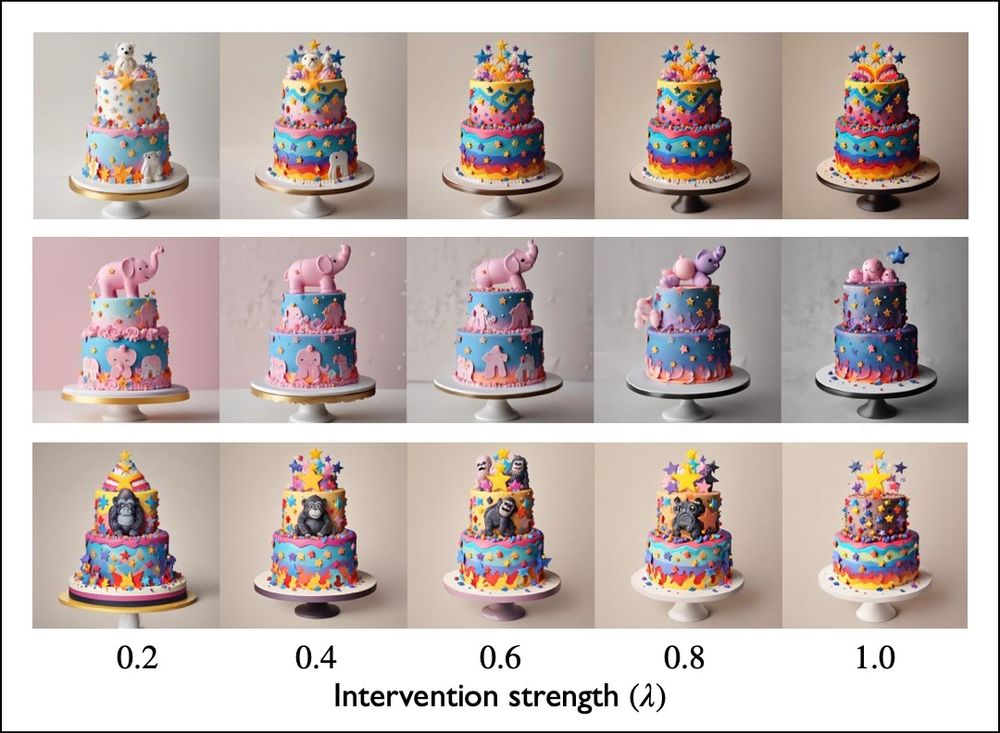
8/9 T2I models tend to generate negated concepts 😮
In the image, StableDiffusion XL prompted with: “2 tier cake with multicolored stars attached to it and no {white bear, pink elephant, gorilla} can be seen.”
✨Linear-AcT makes the negated concept disappear✨
10.12.2024 13:09 — 👍 4 🔁 1 💬 1 📌 0
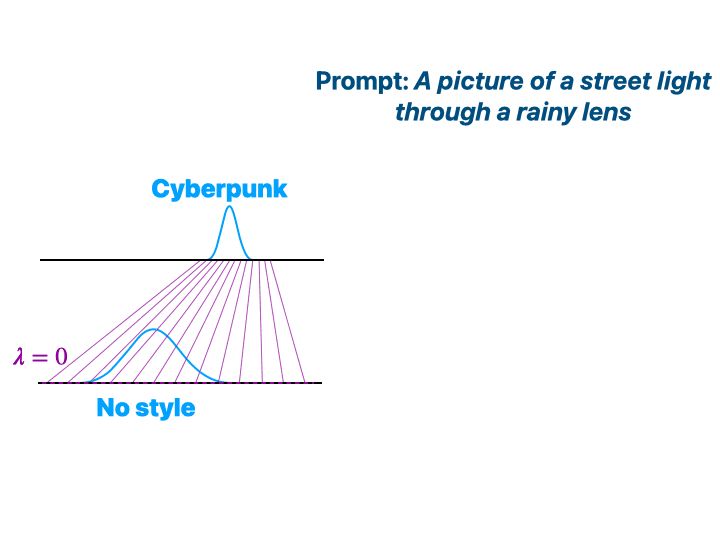
7/9 And here we induce Cyberpunk 🤖 for the same prompt!
10.12.2024 13:09 — 👍 2 🔁 0 💬 2 📌 0
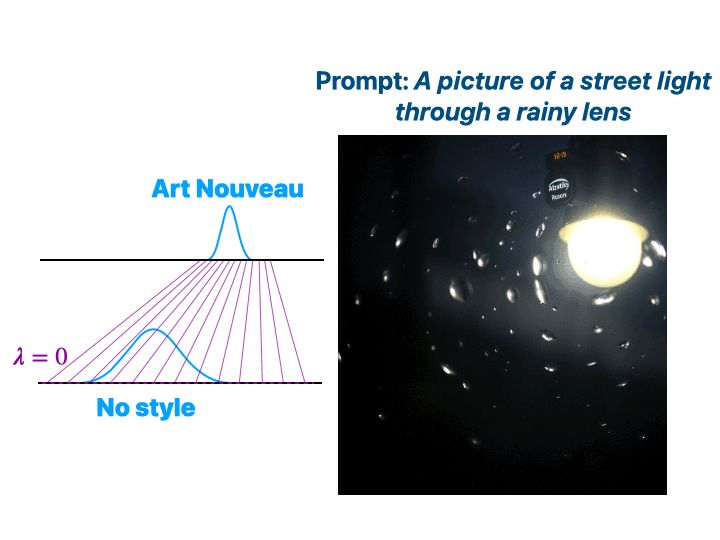
6/9 Amazingly, we can condition Text-to-Image (T2I) Diffusion with the same exact method we used for LLMs! 🤯
In this example, we induce a specific style (Art Nouveau 🎨), which we can accurately control with our λ parameter.
10.12.2024 13:09 — 👍 2 🔁 0 💬 1 📌 0
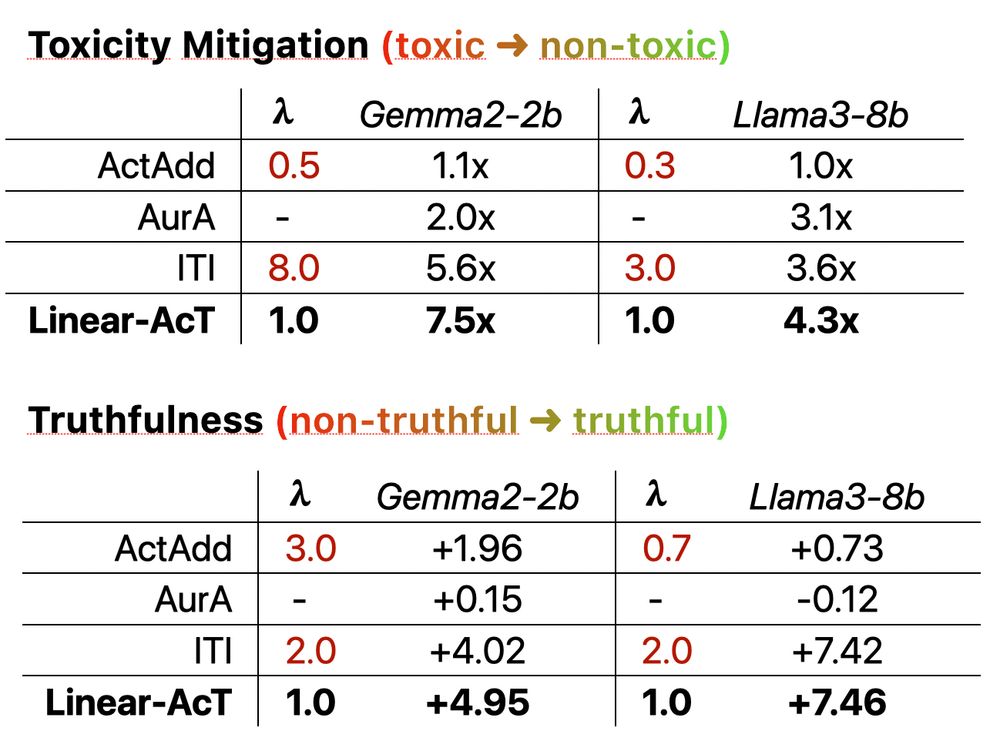
5/9 With Linear-AcT, we achieve great results in LLM 👿 toxicity mitigation and 👩🏼⚖️ truthfulness induction.
And the best result is always obtained at λ=1, as opposed to vector-based steering methods!
10.12.2024 13:09 — 👍 1 🔁 0 💬 1 📌 0
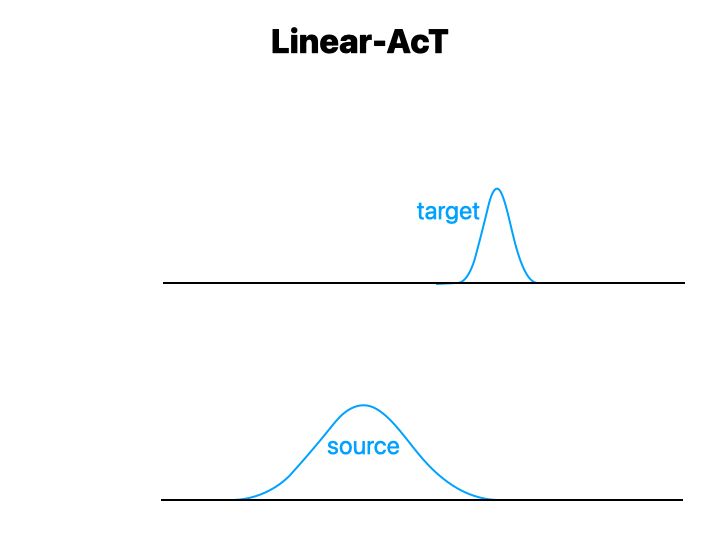
4/9 Linear-AcT preserves target distributions, with interpretable strength λ 🌈
🍰 All we need is two small sets of sentences {a},{b} from source and target distributions to estimate the Optimal Transport (OT) map 🚚
🚀 We linearize the map for speed/memory, thus ⭐Linear-AcT⭐
10.12.2024 13:09 — 👍 1 🔁 0 💬 1 📌 0
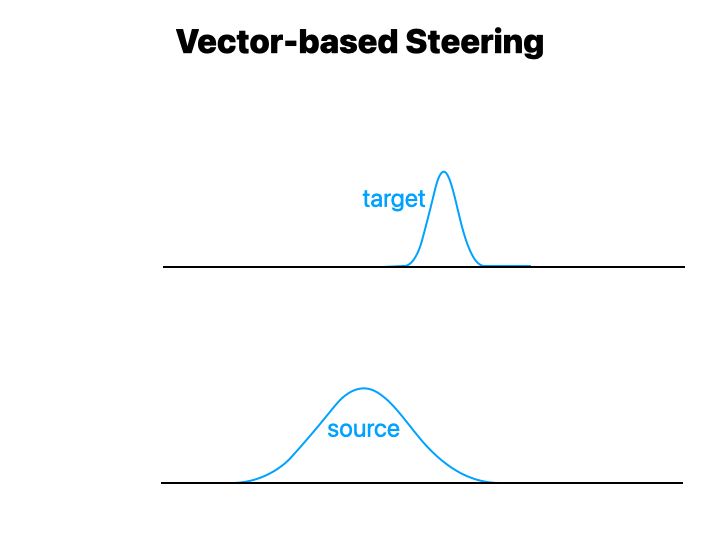
3/9 An activation has a different output distributions per behavior, eg. 🦠 toxic (source) and 😊 non-toxic (target). i) Vector-based AS moves activations OOD 🤯, with catastrophic consequences 💥 harming model utility. ii) The strength λ is unbounded and non-interpretable 🤨!
10.12.2024 13:09 — 👍 1 🔁 0 💬 1 📌 0
2/9 🤓 Activation Steering (AS) is a fast and cheap alternative for alignment/control.
Most AS techniques perform a vector addition such as a* = a + λv, where v is some estimated vector and λ the conditioning strength. How v is estimated differs for each method.
10.12.2024 13:09 — 👍 1 🔁 0 💬 1 📌 0
1/9 🤔 How do we currently align/control generative models?
- Pre-prompting
- Fine-tuning
- RLHF
However, these techniques can be slow/expensive! 🐢
10.12.2024 13:09 — 👍 2 🔁 0 💬 1 📌 0

Thrilled to share the latest work from our team at
@Apple
where we achieve interpretable and fine-grained control of LLMs and Diffusion models via Activation Transport 🔥
📄 arxiv.org/abs/2410.23054
🛠️ github.com/apple/ml-act
0/9 🧵
10.12.2024 13:09 — 👍 47 🔁 15 💬 3 📌 5
Announcing the NeurIPS 2024 Test of Time Paper Awards – NeurIPS Blog
Thank you to the @neuripsconf.bsky.social for this recognition of the Generative Adversarial Nets paper published ten years ago with @ian-goodfellow.bsky.social, Jean Pouget-Abadie, @memimo.bsky.social, Bing Xu, David Warde-Farley, Sherjil Ozair and Aaron Courville.
blog.neurips.cc/2024/11/27/a...
28.11.2024 14:36 — 👍 194 🔁 20 💬 4 📌 0

Apple will be a platinum sponsor of the Deep Learning Barcelona Symposim 2024. This is the first time that Apple sponsors the event. #DLBCN
22.11.2024 07:42 — 👍 1 🔁 1 💬 0 📌 0
Inbox | Substack
Bring stats to LM evals!!
open.substack.com/pub/desiriva...
21.11.2024 16:59 — 👍 4 🔁 1 💬 0 📌 0
Watching Frieren can’t stop thinking that demons are evil LLMs 😅
20.11.2024 12:10 — 👍 3 🔁 0 💬 0 📌 0
Research Scientist @ | Previously @ Toyota Research Institute and Google | PhD from Georgia Tech.
Interests on bsky: ML research, applied math, and general mathematical and engineering miscellany. Also: Uncertainty, symmetry in ML, reliable deployment; applications in LLMs, computational chemistry/physics, and healthcare.
https://shubhendu-trivedi.org
Ph.D. student on generative models and domain adaptation for Earth observation 🛰
Previously intern @SonyCSL, @Ircam, @Inria
🌎 Personal website: https://lebellig.github.io/
Apple ML Research in Barcelona, prev OxCSML InfAtEd, part of MLinPL & polonium_org 🇵🇱, sometimes funny
AI for Science, deep generative models, inverse problems. Professor of AI and deep learning @universitedeliege.bsky.social. Previously @CERN, @nyuniversity. https://glouppe.github.io
TMLR Homepage: https://jmlr.org/tmlr/
TMLR Infinite Conference: https://tmlr.infinite-conf.org/
Bioinformatics PhD Student in the Ren lab at UCSD. Modeling gene regulation across species.
Machine Learning Research @ Apple (opinions are my own)
ML Engineer-ist @ Apple Machine Learning Research
AI for storytelling, games, explainability, safety, ethics. Professor at Georgia Tech. Associate Director of ML Center at GT. Time travel expert. Geek. Dad. he/him
PhD Student @ UC San Diego
Researching reliable, interpretable, and human-aligned ML/AI
Computer science, math, machine learning, (differential) privacy
Researcher at Google DeepMind
Kiwi🇳🇿 in California🇺🇸
http://stein.ke/
PhD student in NLP at Sapienza | Prev: Apple MLR, @colt-upf.bsky.social , HF Bigscience, PiSchool, HumanCentricArt #NLProc
www.santilli.xyz
Research Scientist at Apple for uncertainty quantification.
Group Leader, Generative AI | NeurIPS 2024 Program Chair | Principal Scientist & Director | Founder of Amsterdam AI Solutions
#NLP Postdoc at Mila - Quebec AI Institute & McGill University
mariusmosbach.com
Professor in computational Bayesian modeling at Aalto University, Finland. Bayesian Data Analysis 3rd ed, Regression and Other Stories, and Active Statistics co-author. #mcmc_stan and #arviz developer.
Web page https://users.aalto.fi/~ave/
Principal Researcher in BioML at Microsoft Research. He/him/他. 🇹🇼 yangkky.github.io























