@crampell.bsky.social’s post got me to thinking and…yes…Trump has apparently canceled the research grant of Judea Pearl, who is one of the world’s leading scholars, is Jewish, Israeli-American, & is vocally opposed to antisemitism, & is the father of Daniel Pearl.
www.science.org/content/arti...
03.08.2025 02:44 — 👍 213 🔁 91 💬 9 📌 8
Stellen OBP - Georg-August-Universität Göttingen
Webseiten der Georg-August-Universität Göttingen
Interested in multilingual tokenization in #NLP? Lisa Beinborn and I are hiring!
PhD candidate position in Göttingen, Germany: www.uni-goettingen.de/de/644546.ht...
PostDoc position in Leuven, Belgium:
www.kuleuven.be/personeel/jo...
Deadline 6th of June
16.05.2025 08:23 — 👍 25 🔁 13 💬 2 📌 2
I've posted a few papers I missed including yours here bsky.app/profile/crai.... Thomas pointed that out about 5 seconds after I posted on the discord :-)
30.07.2025 15:17 — 👍 1 🔁 0 💬 1 📌 0
And of course I missed some tokenization related papers at #ACL2025 in my previous post. Any more I should add?
30.07.2025 14:22 — 👍 2 🔁 0 💬 1 📌 0
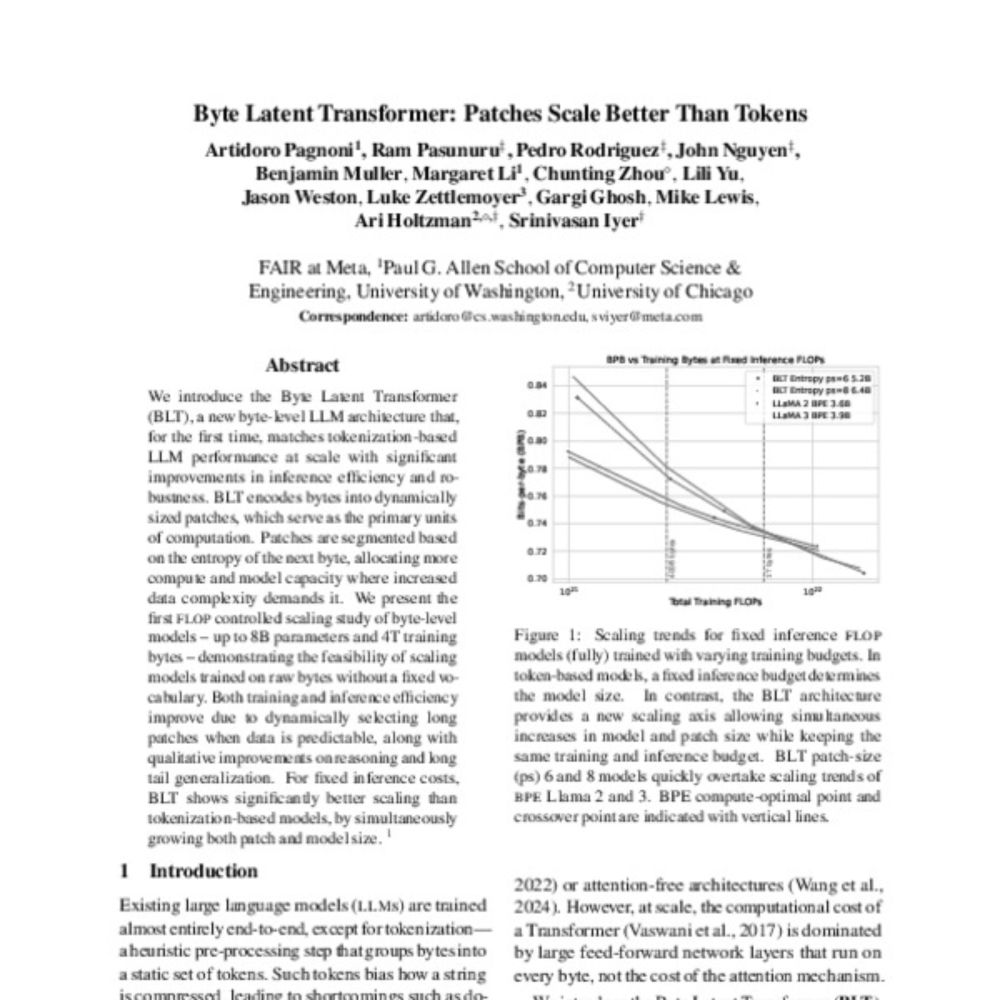
Byte Latent Transformer: Patches Scale Better Than Tokens
Artidoro Pagnoni, Ramakanth Pasunuru, Pedro Rodriguez, John Nguyen, Benjamin Muller, Margaret Li, Chunting Zhou, Lili Yu, Jason E Weston, Luke Zettlemoyer, Gargi Ghosh, Mike Lewis, Ari Holtzman, Srini...
1) Byte Latent Transformer: Patches Scale Better Than Tokens
Artidoro Pagnoni et al
aclanthology.org/2025.acl-lon...
30.07.2025 14:03 — 👍 1 🔁 0 💬 1 📌 0
I'm sadly not at #ACL2025, but the work on tokenization seem to continue to explode. Here are the tokenization related papers I could find, in no particular order. Let me know if I missed any.
30.07.2025 14:03 — 👍 11 🔁 4 💬 2 📌 0
Really grateful to the organizers for the recognition of our work!
19.07.2025 13:55 — 👍 12 🔁 1 💬 1 📌 0
ICML Poster Chameleon: A Flexible Data-mixing Framework for Language Model Pretraining and FinetuningICML 2025
You’re right these results apply to general “big” datasets like ThePile or RedPajama. There are several papers at ICML on weighting datasets like Chameleon (icml.cc/virtual/2025...) that could probably let you get away with less data.
17.07.2025 15:29 — 👍 1 🔁 0 💬 1 📌 0
My son said he couldn’t call me on Father’s Day because he had worked the weekend dealing with a North Korean hacking group. Valid excuse I guess. The hack analysis …
18.06.2025 23:58 — 👍 1 🔁 0 💬 0 📌 0
I see I was too slow, and you're already on the discord
01.06.2025 14:11 — 👍 1 🔁 0 💬 0 📌 0

A bit of a mess around the conflict of COLM with the ARR (and to lesser degree ICML) reviews release. We feel this is creating a lot of pressure and uncertainty. So, we are pushing our deadlines:
Abstracts due March 22 AoE (+48hr)
Full papers due March 28 AoE (+24hr)
Plz RT 🙏
20.03.2025 18:20 — 👍 37 🔁 31 💬 3 📌 2
If you have an interest in tokenization in Natural Language Processing (NLP), this is a nice discord. Come say hi.
12.02.2025 14:17 — 👍 4 🔁 0 💬 1 📌 0
Researcher of online rumors & disinformation. Former basketball player. Prof at University of Washington, HCDE. Co-founder of the UW Center for an Informed Public. Personal account: Views may not reflect those of my employer. #RageAgainstTheBullshitMachine
Computational linguist trying to understand how humans and computers learn and use language 👶🧠🗣️🖥️💬
PhD @clausebielefeld.bsky.social, Bielefeld University
https://bbunzeck.github.io
NLP PhD at UKP Lab, TU Darmstadt | Alumnus IISc | Alumnus IIT-ISM
ML/AI at Sennder || ex Turi, Apple
Longer posts at https://crosstab.io/.
Academic Editor & Writing Coach at https://www.indeliblevoice.com ・Communication and/or technology researcher 🔬・Author of "Politics Recoded" (MIT Press 2024) 🤖・Foodie 🍲・Nature boi 🌲・Cancer caregiver 🎗️・They/he・All links https://bio.site/aure
Disseminating knowledge—through the publication of printed books, periodicals, and electronic files—beyond the confines of the University's campus.
First University Press in the US
Established 1869
http://cornellpress.cornell.edu
At Johns Hopkins University Press, we envision a future where knowledge enriches the life of every person.
Home to @projectmuse.bsky.social
press.jhu.edu
Books et Veritas. Bringing truth to light for more than one hundred years.
Book publisher, est. 1925.
The University of North Carolina Press
📖 First University Press in the South
📚 Publishing distinguished books and journals for academics, students, and general readers for over a century
Adventures in books... from Yale University Press in London
https://yalebooks.co.uk/
Publishing books that champion the arts & humanities
⭐️ For book updates & UK OFFERS join the Yale in London newsletter: bit.ly/YaleBookNews ⭐️
Publishing voices that drive change & impact how people think. Founded in 1893. linkin.bio/ucpress
University of Illinois Press / Publisher of scholarly and regional trade books and journals since 1918
We believe in books that promote positive change and enrich culture.
Sign up to the MUP newsletter & receive 30% off all orders.
https://linktr.ee/ManchesterUniversityPress
The oldest scholarly press in Ohio, specializing in African studies, Appalachian studies, regional guidebooks, and literary fiction. Learn more at ohioswallow.com
Mission-driven nonprofit publisher committed to the idea of scholarship as a public good, serving intellectually curious readers everywhere for over 100 years. bio.link/uwapress
Rutgers University Press is dedicated to the advancement and dissemination of knowledge to scholars, students, and the general reading public. The Press reflects and extends the University’s core mission of research, instruction, and service.
Publishes 70+ books per year in the humanities & social sciences, blending the strengths of a university press with innovation sparked by digital technologies
upress.virginia.edu




































