
In any case, the work is featuring at an interesting-looking workshop this weekend, put on by @katherinelee.bsky.social, @vaidehipatil.bsky.social, and others. More info here: mugenworkshop.github.io
15.07.2025 13:27 — 👍 2 🔁 1 💬 0 📌 0In any case, the work is featuring at an interesting-looking workshop this weekend, put on by @katherinelee.bsky.social, @vaidehipatil.bsky.social, and others. More info here: mugenworkshop.github.io
15.07.2025 13:27 — 👍 2 🔁 1 💬 0 📌 0
UT Austin campus
Extremely excited to announce that I will be joining
@utaustin.bsky.social Computer Science in August 2025 as an Assistant Professor! 🎉
Thanks to my amazing collaborators Yi-Lin Sung , @peterbhase.bsky.social , Jie Peng, Tianlong Chen , @mohitbansal.bsky.social for a wonderful collaboration!
07.05.2025 18:54 — 👍 0 🔁 0 💬 0 📌 0
📎 Check it out here!
📄 Paper: arxiv.org/abs/2505.01456
💻 Code and Dataset: github.com/Vaidehi99/Un...
huggingface.co/datasets/vai...
🤗 HuggingFace: huggingface.co/papers/2505....

Key Findings
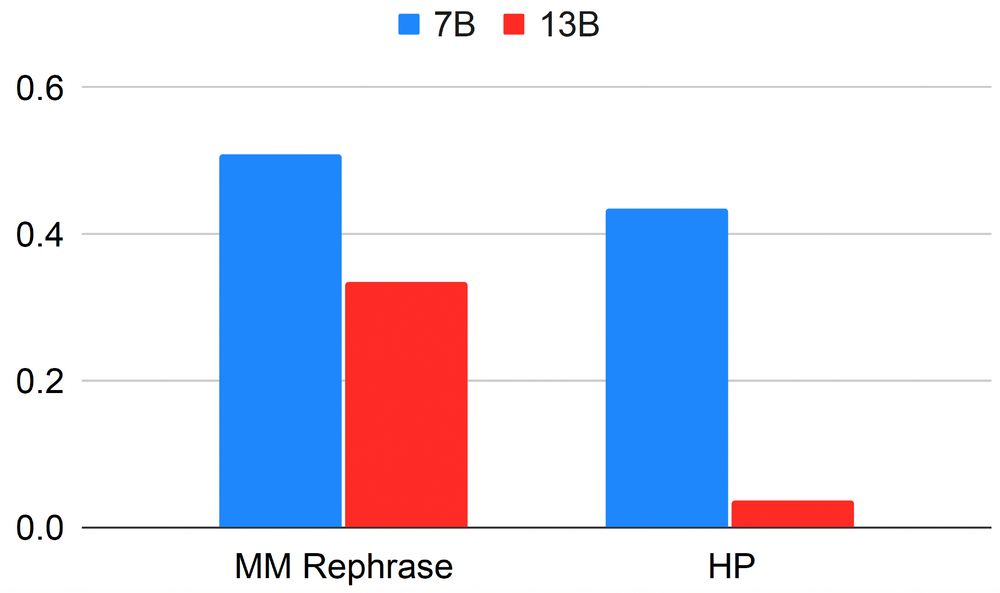
🔥 Multimodal attacks are the most effective
🛡️ Our strongest defense is deleting info from hidden states
📉 Larger models are more robust to extraction attacks post-editing compared to smaller ones
🎯 UnLOK-VQA enables targeted evaluations of unlearning defenses
⚔️ Benchmarking Multimodal Unlearning Defenses
Multimodal data opens up new attack vectors.
We benchmark 6 unlearning defenses against 7 attack strategies, including:
✅White-box attacks
✅Black-box paraphrased multimodal prompts
This enables two key types of evaluation:
✅Generalization Evaluation
✔️Rephrased questions
✔️Rephrased images
✅Specificity Evaluation
✔️Neighboring questions (same image, new question)
✔️Neighboring images (same concept, different image)


📦 What Is UnLOK-VQA?
UnLOK-VQA focuses on unlearning pretrained knowledge and builds on OK-VQA, a visual QA dataset. We extend it w/ an automated question-answer generation and image generation pipeline:
✅Forget samples from OK-VQA
✅New samples at varying levels of proximity (easy, medium, hard)
This is essential for:
📜 Legal compliance (e.g., GDPR, CCPA, the right to be forgotten)
🔐 Multimodal Privacy (e.g., faces, locations, license plates)
📷 Trust in real-world image-grounded systems

🔍 Why Does Multimodal Unlearning Matter?
Existing unlearning benchmarks focus only on text.
But multimodal LLMs are trained on web-scale data—images + captions—making them highly vulnerable to leakage of sensitive or unwanted content.
Unlearning must hold across modalities, not just in language.
We study:
❓ How effectively can we erase multimodal knowledge?
❓ How should we measure forgetting in multimodal settings?
✅We benchmark 6 unlearning defenses against 7 whitebox and blackbox attack strategies

🚨 Introducing our @tmlrorg.bsky.social paper “Unlearning Sensitive Information in Multimodal LLMs: Benchmark and Attack-Defense Evaluation”
We present UnLOK-VQA, a benchmark to evaluate unlearning in vision-and-language models, where both images and text may encode sensitive or private information.

In Singapore for #ICLR2025 this week to present papers + keynotes 👇, and looking forward to seeing everyone -- happy to chat about research, or faculty+postdoc+phd positions, or simply hanging out (feel free to ping)! 🙂
Also meet our awesome students/postdocs/collaborators presenting their work.
Come chat about unlearning with us!!
02.04.2025 16:57 — 👍 5 🔁 1 💬 0 📌 0
Call for PC Members!
We’re looking for program committee members!
📝 Submit your Expression of Interest here: forms.gle/ZPEHeymJ4t5N...
#ICML2025
👩💻 Organizers:
Mantas Mazeika, Yang Liu, @katherinelee.bsky.social, @mohitbansal.bsky.social, Bo Li and myself (@vaidehipatil.bsky.social) 🙂
🔥 Speakers & Panelists:
We're lucky to have an incredible lineup of speakers and panelists covering diverse topics in our workshop:
Nicholas Carlini, Ling Liu, Shagufta Mehnaz, @peterbhase.bsky.social , Eleni Triantafillou, Sijia Liu, @afedercooper.bsky.social, Amy Cyphert
We invite contributions exploring key challenges and advancements at the intersection of machine unlearning and generative AI!
🔗 Full details & updates: mugenworkshop.github.io
📅 Key Dates:
📝 Submission Deadline: May 19
✅ Acceptance Notifications: June 9
🤝 Workshop Date: July 18 or 19

🚨Exciting @icmlconf.bsky.social workshop alert 🚨
We’re thrilled to announce the #ICML2025 Workshop on Machine Unlearning for Generative AI (MUGen)!
⚡Join us in Vancouver this July to dive into cutting-edge research on unlearning in generative AI with top speakers and panelists! ⚡

🥳🥳 Honored and grateful to be awarded the 2025 Apple Scholars in AI/ML PhD Fellowship! ✨
Huge shoutout to my advisor @mohitbansal.bsky.social, & many thanks to my lab mates @unccs.bsky.social , past collaborators + internship advisors for their support ☺️🙏
machinelearning.apple.com/updates/appl...
🚨UPCORE is our new method for balancing unlearning/forgetting with maintaining model performance.
Best part is it works by selecting a coreset from the data rather than changing the model, so it is compatible with any unlearning method, with consistent gains for 3 methods + 2 tasks!

Huge thanks to my co-authors
@esteng.bsky.social , and @mohitbansal.bsky.social for a great collaboration!
🚀 Check it out here:
📄 Paper: arxiv.org/abs/2502.15082
💻 Code: github.com/Vaidehi99/UP...
🤗 @huggingface page: huggingface.co/papers/2502....


UPCORE consistently outperforms baselines across all methods:
✔️ Less unintended degradation
✔️ Deletion transferred to pruned points
UPCORE provides a practical, method-agnostic approach that improves the reliability of unlearning techniques.
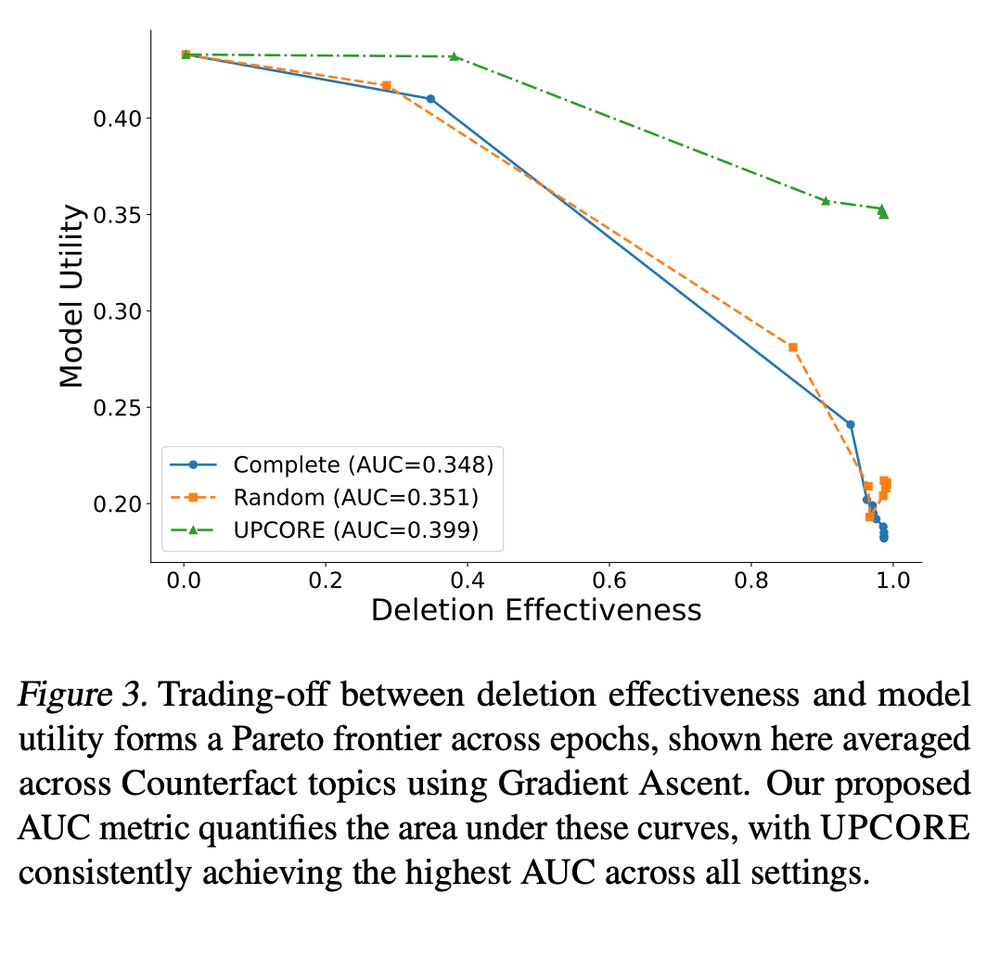
Instead of evaluating at a single training checkpoint, we introduce AUC (Area Under the Curve) across deletion effectiveness and utility.
This provides a complete picture of the trade-off between forgetting and knowledge retention over the unlearning trajectory.
We apply UPCORE across three unlearning methods:
📉 Gradient Ascent
🚫 Refusal
🔄 Negative Preference Optimization (NPO)
We measure:
✔️ Deletion effectiveness – How well the target is removed
✔️ Unintended degradation – Impact on other abilities
✔️ Positive transfer – How well unlearning generalizes
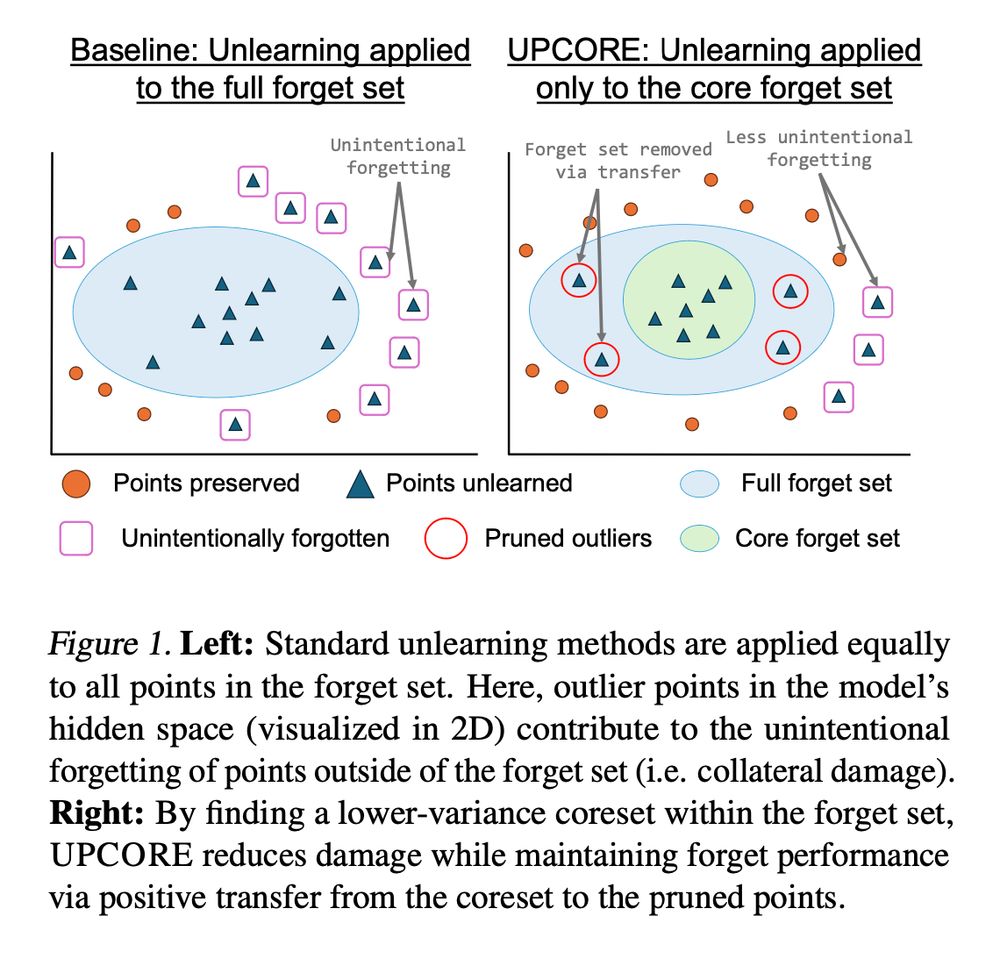
Even after pruning, the pruned points in the forget set still become unlearned -- thanks to positive collateral transfer from the core forget set.
Thus, UPCORE reduces negative collateral effects while maintaining effective deletion.
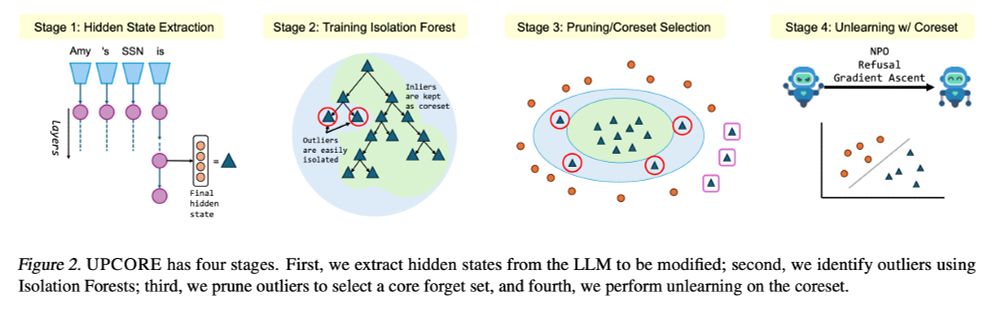
UPCORE constructs a core forget set by identifying and removing outlier points using Isolation Forest.
✅ Minimizes unintended degradation
✅ Preserves model utility
✅ Compatible with multiple unlearning methods
Our key insight: Not all forget set points degrade the model equally.
Points contributing to high variance cause more collateral damage when unlearned.
By pruning these outliers, UPCORE reduces unintended forgetting while ensuring effective deletion.
LLMs train on vast datasets, often with sensitive or unwanted info. Regulations like GDPR, CCPA mandate removal.
Yet, standard unlearning can degrade unrelated knowledge, making it unreliable.
Effective unlearning is key for:
📜 Compliance (GDPR, CCPA)
🔐 Privacy & security
⚖️ Ethical AI development

🚨 Introducing UPCORE, to balance deleting info from LLMs with keeping their other capabilities intact.
UPCORE selects a coreset of forget data, leading to a better trade-off across 2 datasets and 3 unlearning methods.
🧵👇