6.005: Software Construction
Honestly most topics in this Software Engineering course are still very relevant:
ocw.mit.edu/ans7870/6/6....
Things I've used in the past few months:
- Writing Good Specs
- Safety Mechanisms (Tests, Assertions, Immutability etc.)
- Design Patterns (GUIs, Parallelism, Parser Generators)
31.12.2025 08:38 —
👍 1
🔁 0
💬 0
📌 0
The easiest / cleanest solution would be free registration at the conference.
05.12.2025 23:11 —
👍 1
🔁 0
💬 0
📌 0

I'll be @neuripsconf.bsky.social presenting Strategic Hypothesis Testing (spotlight!)
tldr: Many high-stakes decisions (e.g., drug approval) rely on p-values, but people submitting evidence respond strategically even w/o p-hacking. Can we characterize this behavior & how policy shapes it?
1/n
01.12.2025 20:31 —
👍 17
🔁 4
💬 1
📌 0
Spread the word! 📢 The FATE (Fairness, Accountability, Transparency, and Ethics) group at @msftresearch.bsky.social in NYC is hiring interns and postdocs to start in summer 2026! 🎉
Apply by *December 15* for full consideration.
20.11.2025 20:11 —
👍 51
🔁 29
💬 1
📌 0

HMRC trial of child benefit crackdown wrongly suspected fraud in 46% of cases
Exclusive: Almost half of families flagged as emigrants based on Home Office travel data were still living in UK
UK government project using AI to find benefit fraud resulted in:
- A 46% false fraud rate
- Anguish for families who were wrongly accused of fraud and had benefits stopped
- Months of additional work for government, setting up a hotline, correcting false fraud
www.theguardian.com/society/2025...
09.11.2025 15:11 —
👍 139
🔁 92
💬 12
📌 17
I’m giving an IDE seminar at @mitsloan.bsky.social tomorrow at 11am, on optimizing AI as decision support. Joint work w/ @ziyang.bsky.social @yifanwu.bsky.social @jasonhartline.bsky.social @berkustun.bsky.social
Come by if you’re around!
www.eventbrite.com/e/fall-2025-...
22.10.2025 19:06 —
👍 12
🔁 4
💬 0
📌 0
Who teaches an undergraduate principles of programming languages class? Looking for some inspiration to teach one at UCSD
22.09.2025 23:48 —
👍 6
🔁 1
💬 2
📌 0
Time for XAI for Code? 🙃
01.08.2025 16:01 —
👍 1
🔁 0
💬 0
📌 0
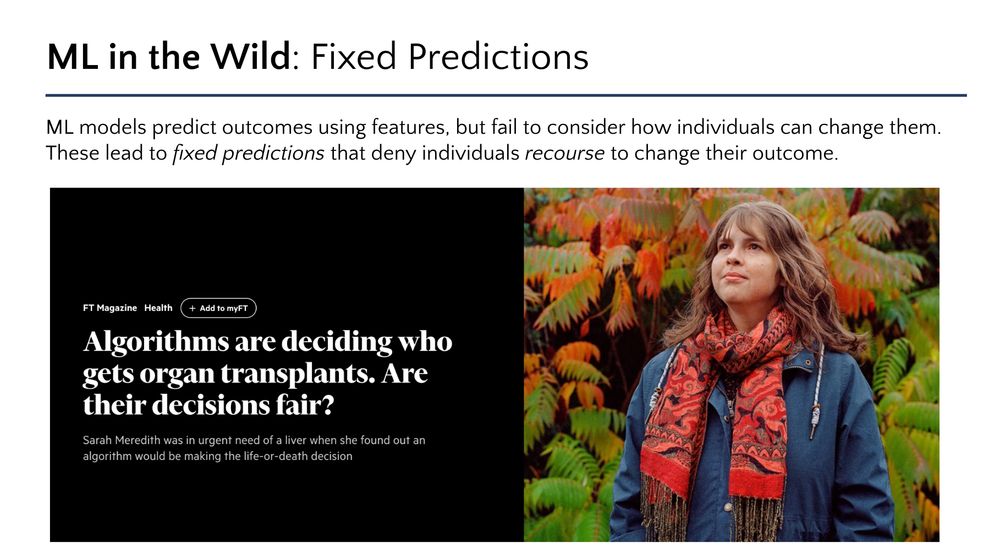
Machine learning models can assign fixed predictions that preclude individuals from changing their outcome. Think credit applicants that can never get a loan approved, or young patients that can never get an organ transplant - no matter how sick they are!
14.07.2025 16:11 —
👍 1
🔁 1
💬 1
📌 0

Understanding Fixed Predictions via Confined Regions
Machine learning models can assign fixed predictions that preclude individuals from changing their outcome. Existing approaches to audit fixed predictions do so on a pointwise basis, which requires ac...
Excited to be chatting about our new paper "Understanding Fixed Predictions via Confined Regions" (joint work with @berkustun.bsky.social, Lily Weng, and Madeleine Udell) at #ICML2025!
🕐 Wed 16 Jul 4:30 p.m. PDT — 7 p.m. PDT
📍East Exhibition Hall A-B #E-1104
🔗 arxiv.org/abs/2502.16380
14.07.2025 16:08 —
👍 5
🔁 3
💬 1
📌 0
ExplainableAI has long frustrated me by lacking a clear theory of what an explanation should do. Improve use of a model for what? How? Given a task what's max effect explanation could have? It's complicated bc most methods are functions of features & prediction but not true state being predicted 1/
02.07.2025 16:53 —
👍 46
🔁 8
💬 2
📌 0

screenshot of title and authors (Jakob Schoeffer, Maria De-Arteaga, Jonathan Elmer)
Having a lot of FOMO not being able to be in person at #FAccT2025 but enjoying the virtual transmission 💻. Tomorrow Jakob will be presenting our paper "Perils of Label Indeterminacy: A Case Study on Prediction of Neurological Recovery After Cardiac Arrest".
25.06.2025 21:30 —
👍 13
🔁 1
💬 1
📌 0
Explanations don't help us detect algorithmic discrimination. Even when users are trained. Even when we control their beliefs. Even under ideal conditions... 👇
24.06.2025 19:16 —
👍 11
🔁 0
💬 0
📌 1

*wrapfig entered the document*
24.05.2025 03:18 —
👍 5
🔁 1
💬 1
📌 0

“Science is a smart, low cost investment. The costs of not investing in it are higher than the risk of doing so… talk to people about science.” - @kevinochsner.bsky.social makes his case to the field #sans2025
26.04.2025 21:03 —
👍 170
🔁 55
💬 7
📌 7
I tried to be nice but then they said that saying please and thanks costs millions.
24.04.2025 18:41 —
👍 4
🔁 0
💬 0
📌 0
Hey AI folks - stop using SHAP! It won't help you debug [1], won't catch discrimination [2], and makes no sense for feature importance [3].
Plus - as we show - it also won't give recourse.
In a paper at #ICLR we introduce feature responsiveness scores... 1/
arxiv.org/pdf/2410.22598
24.04.2025 16:37 —
👍 29
🔁 8
💬 3
📌 0
When RAG systems hallucinate, is the LLM misusing available information or is the retrieved context insufficient? In our #ICLR2025 paper, we introduce "sufficient context" to disentangle these failure modes. Work w Jianyi Zhang, Chun-Sung Ferng, Da-Cheng Juan, Ankur Taly, @cyroid.bsky.social
24.04.2025 18:18 —
👍 11
🔁 5
💬 1
📌 0

Denied a loan, an interview, or an insurance claim by machine learning models? You may be entitled to a list of reasons.
In our latest w @anniewernerfelt.bsky.social @berkustun.bsky.social @friedler.net, we show how existing explanation frameworks fail and present an alternative for recourse
24.04.2025 06:19 —
👍 16
🔁 7
💬 1
📌 1
Absolute banger.
19.04.2025 19:43 —
👍 30
🔁 4
💬 4
📌 1

Many ML models predict labels that don’t reflect what we care about, e.g.:
– Diagnoses from unreliable tests
– Outcomes from noisy electronic health records
In a new paper w/@berkustun, we study how this subjects individuals to a lottery of mistakes.
Paper: bit.ly/3Y673uZ
🧵👇
19.04.2025 23:04 —
👍 12
🔁 2
💬 1
📌 0
is this a rhetorical question?
28.02.2025 19:25 —
👍 5
🔁 0
💬 0
📌 0
 28.02.2025 19:24 —
👍 1
🔁 0
💬 1
📌 0
28.02.2025 19:24 —
👍 1
🔁 0
💬 1
📌 0

🧵on the CFPB and less discriminatory algorithms.
last week, in its supervisory highlights, the Bureau offered a range of impressive new details on how financial institutions should be searching for less discriminatory algorithms.
21.01.2025 18:44 —
👍 16
🔁 5
💬 1
📌 0

Also
14.01.2025 22:31 —
👍 0
🔁 0
💬 0
📌 0

Engaging discussions on the future of #AI in #healthcare at this week's ICHPS, hosted by @amstatnews.bsky.social.
JCHI's @kdpsingh.bsky.social shared insights on the safety & equity of #MachineLearning algorithms and examined bias in large language models.
08.01.2025 21:59 —
👍 9
🔁 4
💬 1
📌 0




