

Some personal updates:
- I've completed my PhD at @unccs.bsky.social! 🎓
- Starting Fall 2026, I'll be joining the CS dept. at Johns Hopkins University @jhucompsci.bsky.social as an Assistant Professor 💙
- Currently exploring options for my gap year (Aug 2025 - Jul 2026), so feel free to reach out! 🔎
20.05.2025 17:58 — 👍 27 🔁 5 💬 3 📌 2
Our paper "Misattribution Matters: Quantifying Unfairness in Authorship Attribution" got accepted to #ACL2025!
@niranjanb.bsky.social @ajayp95.bsky.social
Arxiv link coming hopefully soon!
16.05.2025 03:01 — 👍 2 🔁 2 💬 0 📌 0
🔥 BIG CONGRATS to Elias (and UT Austin)! Really proud of you -- it has been a complete pleasure to work with Elias and see him grow into a strong PI on *all* axes 🤗
Make sure to apply for your PhD with him -- he is an amazing advisor and person! 💙
05.05.2025 22:00 — 👍 12 🔁 4 💬 1 📌 0
Congratulations Elias (and to UT Austin too).
06.05.2025 00:03 — 👍 1 🔁 0 💬 1 📌 0
If you are at #AISTATS2025 and are interested in concept erasure, talk to @somnathbrc.bsky.social at Poster Session 1 on Saturday May 3.
03.05.2025 00:47 — 👍 16 🔁 4 💬 0 📌 0

I’ll be presenting Meta-Reasoning Improves Tool Use in Large Language Models at #NAACL25 tomorrow Thursday May 1st from 2 until 3.30pm in Hall 3! Come check it out and have a friendly chat if you’re interested in LLM reasoning and tools 🙂 #NAACL
30.04.2025 20:58 — 👍 5 🔁 1 💬 1 📌 0

Thrilled that our paper won 🏆 Best Paper Runner-Up 🏆 at #NAACL25!!
Our work (REL-A.I.) introduces an evaluation framework that measures human reliance on LLMs and reveals how contextual features like anthropomorphism, subject, and user history can significantly influence user reliance behaviors.
29.04.2025 22:42 — 👍 31 🔁 3 💬 1 📌 2
advisorial advertising? advisor's advertising? 🤔
29.04.2025 18:48 — 👍 0 🔁 0 💬 0 📌 0

🚀 Excited to share a new interp+agents paper: 🐭🐱 MICE for CATs: Model-Internal Confidence Estimation for Calibrating Agents with Tools appearing at #NAACL2025
This was work done @msftresearch.bsky.social last summer with Jason Eisner, Justin Svegliato, Ben Van Durme, Yu Su, and Sam Thomson
1/🧵
29.04.2025 13:41 — 👍 12 🔁 8 💬 1 📌 2
I'll do the advisory advertising: @ykl7.bsky.social is a fantastic researcher and is passionate about being in academia. He has this amazing ability to simply get things done! Happy to say more in a letter or over a chat but if you are going to @naaclmeeting.bsky.social (#NAACL2025) ping him.
29.04.2025 18:40 — 👍 3 🔁 1 💬 1 📌 0
Nice work Abhilasha!
28.04.2025 16:08 — 👍 1 🔁 0 💬 1 📌 0
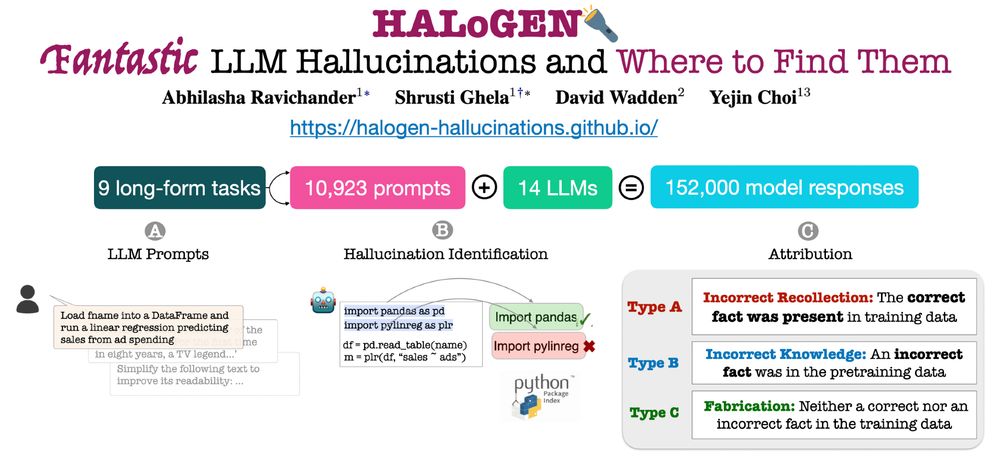
We are launching HALoGEN💡, a way to systematically study *when* and *why* LLMs still hallucinate.
New work w/ Shrusti Ghela*, David Wadden, and Yejin Choi 💫
📝 Paper: arxiv.org/abs/2501.08292
🚀 Code/Data: github.com/AbhilashaRav...
🌐 Website: halogen-hallucinations.github.io 🧵 [1/n]
31.01.2025 18:27 — 👍 34 🔁 8 💬 3 📌 4

🟢 Announcing the #NAACL2025 Award Winners!
The Best Paper and Best Theme Paper winners will present at our closing session
2025.naacl.org/blog/best-pa...
25.04.2025 16:04 — 👍 16 🔁 7 💬 0 📌 0
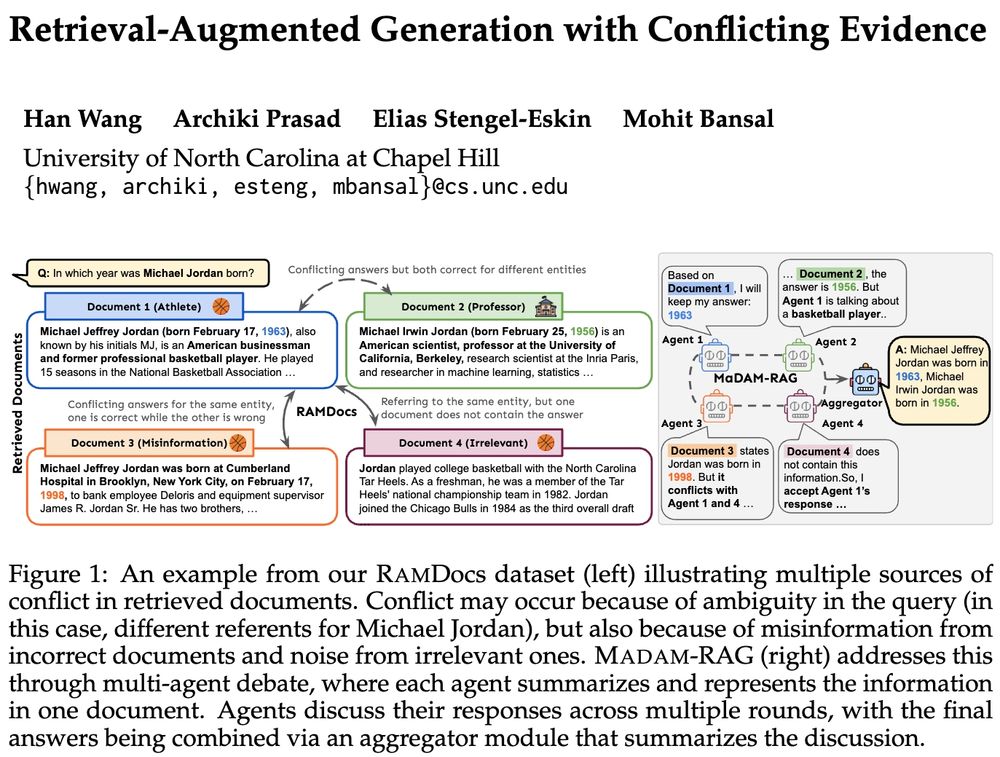
🚨Real-world retrieval is messy: queries are ambiguous or docs conflict & have incorrect/irrelevant info. How can we jointly address these problems?
➡️RAMDocs: challenging dataset w/ ambiguity, misinformation & noise
➡️MADAM-RAG: multi-agent framework, debates & aggregates evidence across sources
🧵⬇️
18.04.2025 17:05 — 👍 14 🔁 7 💬 3 📌 0
Check out @juand-r.bsky.social and @wenxuand.bsky.social 's work on improving generator-validator gaps in LLMs! I really like the formulation of the G-V gap we present, and I was pleasantly surprised by how well the ranking-based training closed the gap. Looking forward to following up in this area!
16.04.2025 18:18 — 👍 11 🔁 2 💬 0 📌 0
For years it’s been an open question — how much is a language model learning and synthesizing information, and how much is it just memorizing and reciting?
Introducing OLMoTrace, a new feature in the Ai2 Playground that begins to shed some light. 🔦
09.04.2025 13:16 — 👍 59 🔁 12 💬 4 📌 13

Please share it within your circles! edin.ac/3DDQK1o
13.03.2025 11:59 — 👍 14 🔁 9 💬 0 📌 1

Excited to announce the COLM 2025 keynote speakers: Shirley Ho, Nicholas Carlini, @lukezettlemoyer.bsky.social, and Tom Griffiths!
See you in October in Montreal!
10.03.2025 14:33 — 👍 24 🔁 3 💬 0 📌 2
Working on it. Stay tuned.
09.12.2024 14:57 — 👍 0 🔁 0 💬 0 📌 0
Thanks @mohitbansal.bsky.social for the wonderful Distinguished Lecture on agents and multimodal generation. This got so many of us here at Stony Brook excited for the potential in these areas. Also, thanks for spending time with our students & sharing your wisdom. It was a pleasure hosting you!
09.12.2024 12:49 — 👍 10 🔁 3 💬 1 📌 0

A flyer announcing that Professor Mohit Bansal from the University of North Carolina Chapel Hill will present a Distinguished Lecture on Planning Agents for Collaborative Reasoning and Multimodal Generation at 2:30 PM in the New Computer Science Room 120 on Dec 6th 2024. The flyer also has a head shot of Mohit Bansal.
Excited to host the wonderful @mohitbansal.bsky.social as part of Stony Brook CS Distinguished Lecture Series on Dec 6th. Looking forward to hearing about his team's fantastic work on Planning Agents for Collaborative Reasoning and Multimodal Generation. More here: tinyurl.com/jkmex3e9
03.12.2024 15:07 — 👍 3 🔁 0 💬 1 📌 2
Hmmm. Fair. I feel like some record somewhere of my tardiness in submitting reviews will prod me to do better.
27.11.2024 18:22 — 👍 0 🔁 0 💬 1 📌 0
I noticed a lot of starter packs skewed towards faculty/industry, so I made one of just NLP & ML students: go.bsky.app/vju2ux
Students do different research, go on the job market, and recruit other students. Ping me and I'll add you!
23.11.2024 19:54 — 👍 176 🔁 54 💬 101 📌 4
Have you thoughts about deanon post discussion phase? That is, denon after the deed is done. This way it doesnt influence your thinking but keeps you accountable.
25.11.2024 14:02 — 👍 1 🔁 0 💬 1 📌 0

✨New pre-print!✨ Successful language technologies should work for a wide variety of languages. But some languages have systematically worse performance than others. In this paper we ask whether performance differences are due to morphological typology. Spoiler: I don’t think so! #NLP #linguistics
22.11.2024 15:03 — 👍 76 🔁 14 💬 2 📌 2
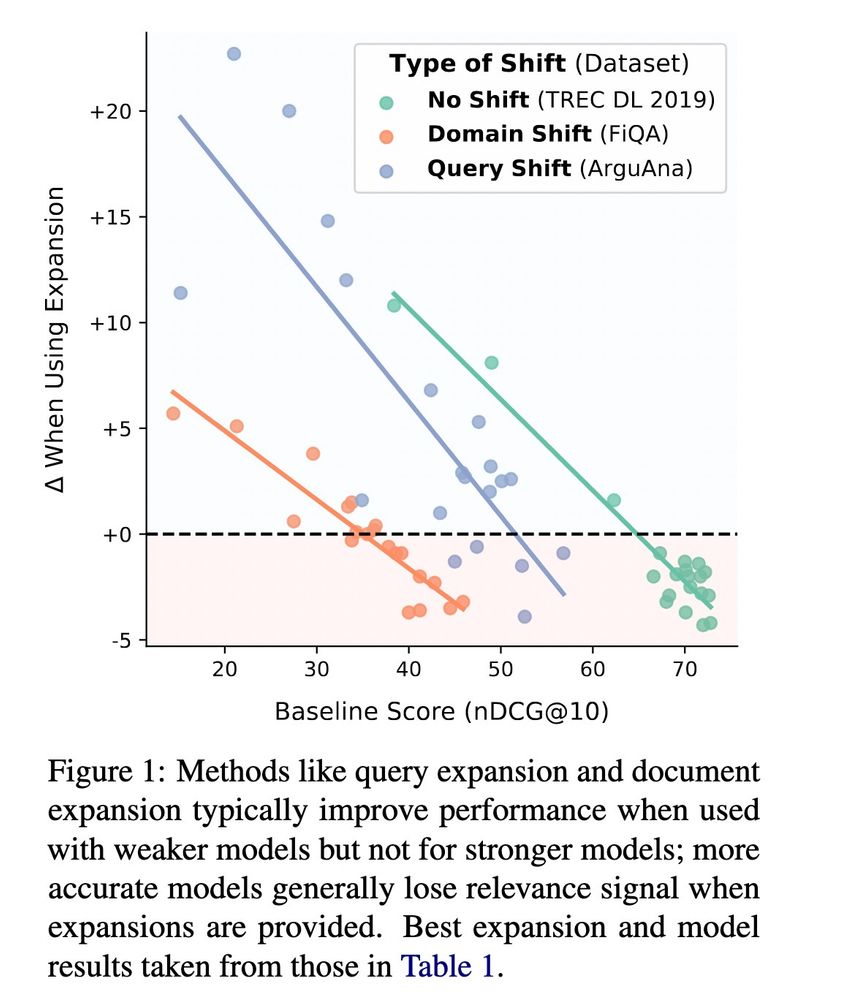
A plot: the x axis is baseline score of rankers, in ndcg@10. y axis is delta of model score after an expansion is applied.
There are three sets of results, one dataset for each shift type: TrecDL (no shift), FiQA (domain shift), ArguAna (query shift). For each set of result, the chart shows a scatter plot with a trend line. We observe the same trend for all: as the baseline score increases, the delta when using expansion decreases.
On TREC DL, worst models have a base score of ~40, and improve by 10 points w/expansion. the best models have a score of >70, and their performance decreases by -5 points w/expansion.
On FiQA, worse models have a base score of ~15, and improve by 5 points w/expansion. the best models have a score of ~45, and their performance decreases by -3 point w/expansion.
On ArguAna, worst models have a base score of ~25, and improve by >20 points w/expansion. the best models have a score of >55, and their performance decreases by -1 point w/expansion.
Using LLMs for query or document expansion in retrieval (e.g. HyDE and Doc2Query) have scores going 📈
But do these approaches work for all IR models and for different types of distribution shifts? Turns out its actually more 📉 🚨
📝 (arxiv soon): orionweller.github.io/assets/pdf/L...
15.09.2023 18:57 — 👍 42 🔁 6 💬 3 📌 3
🚨 We are refreshing the 🌎 AppWorld (appworld.dev) leaderboard with all the new coding and/or tool-use LMs.
❓ What would you like to be included?
🔌 Self-plugs are welcome!!
x.com/harsh3vedi/s...
21.11.2024 14:11 — 👍 7 🔁 2 💬 0 📌 1
Assistant Professor in Humane AI and NLP at the University of Groningen (GroNLP)
associate prof at UMD CS researching NLP & LLMs
DevAI @google, working on PL/SE+ ML. CS PhD (@MIT_CSAIL) 🇨🇷 in ATL. www.josecambronero.com
ML@AWS
Prev: Stony Brook University
Postdoc @ TakeLab, UniZG | previously: Technion; TU Darmstadt | PhD @ TakeLab, UniZG
Faithful explainability, controllability & safety of LLMs.
🔎 On the academic job market 🔎
https://mttk.github.io/
Research in NLP (mostly LM interpretability & explainability).
Assistant prof at UMD CS + CLIP.
Previously @ai2.bsky.social @uwnlp.bsky.social
Views my own.
sarahwie.github.io
PhD candidate @UMD | Responsible AI
NLP PhD student @ University of Maryland, College Park || prev lyft, UT Austin NLP
https://nehasrikn.github.io/
Research Scientist at Google DeepMind | Building Gemini
guabhinav.com
Applying and improving #NLP/#AI but in a safe way. Teaching computers to tell stories, play D&D, and help people talk (accessibility).
Assistant Prof in CSEE @ UMBC.
🏳️🌈♿
https://laramartin.net
https://shramay-palta.github.io
CS PhD student . #NLProc at CLIP UMD| Commonsense + xNLP, AI, CompLing | ex Research Intern @msftresearch.bsky.social
Ph.D. Student at UNC NLP | Prev: Apple, Amazon, Adobe (Intern) vaidehi99.github.io | Undergrad @IITBombay
Incoming assistant professor at JHU CS & Young Investigator at AI2
PhD at UNC
https://j-min.io
#multimodal #nlp
Robustness, Data & Annotations, Evaluation & Interpretability in LLMs
http://mimansajaiswal.github.io/
UMIACS Postdoc - Incoming Assistant Professor @ SBU CS. Vision and Language. Prev. @RiceCompSci @vislang @merl_news @MITIBMLab. EECS Rising Star'23. Former drummer. 🇨🇷
https://paolacascante.com/
Computational neuroscientist at Imperial College. I like spikes and making science better (Neuromatch, Brian spiking neural network simulator, SNUFA annual workshop on spiking neurons).
🧪 https://neural-reckoning.org/
📷 https://adobe.ly/3On5B29
Neuro, AI, chips @ Imperial & Cambridge.
www.danakarca.com
Lecturer (Assistant Professor) at Royal Holloway, University of London
ML and Computational Neuroscience
🧠🇬🇧🇩🇪🇦🇹🇺🇸🇮🇳
Mastodon: @anandsubramoney@sigmoid.social
https://anandsubramoney.com
Boutique Neurotheory & Snazz Compneuro at IST Austria





















