
New #OpenAccess
Bringing economic & family sociology into the digital era, @yanghu.co.uk & @yueqiansoc.bsky.social analyze longitudinal data from @usociety.bsky.social to reveal how the use of online banking shape couples' money management and financial decisions
doi.org/10.1093/esr/jcag002
10.02.2026 09:38 — 👍 9 🔁 4 💬 0 📌 0
Redefining influence: how a feminist advocacy group reformed paternity leave in Spain through insider women’s alliances | Journal of Public Policy | Cambridge Core
Redefining influence: how a feminist advocacy group reformed paternity leave in Spain through insider women’s alliances
New publication in the Journal of Public Policy!🚨
⚖️It shows how feminist advocacy pushed for a reform entitling mothers and fathers to equal parental leave in Spain.
👉This also unveils that descriptive representation matters because it can open access for feminist groups.
doi.org/10.1017/S014...
05.02.2026 10:55 — 👍 16 🔁 7 💬 1 📌 0

🧵 NEW: Our report 'Listen and learn' sets out how the Government should improve Universal Credit (UC) for the 15 million people who rely on it.
13 years after its roll-out began, it’s time to get UC right.
We've co-produced recommendations with @changingrealities.bsky.social participants 👇
29.01.2026 16:08 — 👍 20 🔁 12 💬 1 📌 9

This is a brief reminder that the Call for Streams for the 24th ESPAnet Annual Conference is now open.
The deadline for submissions is the 16th of January 2026.
More information at: www.iseg.ulisboa.pt/event/24th-e...
08.01.2026 10:00 — 👍 12 🔁 8 💬 1 📌 2
In our research on socioeconomic background in academia, we ran a survey. Over 2,000 faculty members responded (thanks if you were one!)
Social & cultural capital showed up time and again as key issues.
A few findings you might be interested in...🧵
09.12.2025 16:35 — 👍 62 🔁 26 💬 1 📌 8

screenshot of my post
Big new blogpost!
My guide to data visualization, which includes a very long table of contents, tons of charts, and more.
--> Why data visualization matters and how to make charts more effective, clear, transparent, and sometimes, beautiful.
www.scientificdiscovery.dev/p/salonis-gu...
09.12.2025 20:28 — 👍 800 🔁 317 💬 22 📌 50

A table showing profit margins of major publishers. A snippet of text related to this table is below.
1. The four-fold drain
1.1 Money
Currently, academic publishing is dominated by profit-oriented, multinational companies for
whom scientific knowledge is a commodity to be sold back to the academic community who
created it. The dominant four are Elsevier, Springer Nature, Wiley and Taylor & Francis,
which collectively generated over US$7.1 billion in revenue from journal publishing in 2024
alone, and over US$12 billion in profits between 2019 and 2024 (Table 1A). Their profit
margins have always been over 30% in the last five years, and for the largest publisher
(Elsevier) always over 37%.
Against many comparators, across many sectors, scientific publishing is one of the most
consistently profitable industries (Table S1). These financial arrangements make a substantial
difference to science budgets. In 2024, 46% of Elsevier revenues and 53% of Taylor &
Francis revenues were generated in North America, meaning that North American
researchers were charged over US$2.27 billion by just two for-profit publishers. The
Canadian research councils and the US National Science Foundation were allocated US$9.3
billion in that year.

A figure detailing the drain on researcher time.
1. The four-fold drain
1.2 Time
The number of papers published each year is growing faster than the scientific workforce,
with the number of papers per researcher almost doubling between 1996 and 2022 (Figure
1A). This reflects the fact that publishers’ commercial desire to publish (sell) more material
has aligned well with the competitive prestige culture in which publications help secure jobs,
grants, promotions, and awards. To the extent that this growth is driven by a pressure for
profit, rather than scholarly imperatives, it distorts the way researchers spend their time.
The publishing system depends on unpaid reviewer labour, estimated to be over 130 million
unpaid hours annually in 2020 alone (9). Researchers have complained about the demands of
peer-review for decades, but the scale of the problem is now worse, with editors reporting
widespread difficulties recruiting reviewers. The growth in publications involves not only the
authors’ time, but that of academic editors and reviewers who are dealing with so many
review demands.
Even more seriously, the imperative to produce ever more articles reshapes the nature of
scientific inquiry. Evidence across multiple fields shows that more papers result in
‘ossification’, not new ideas (10). It may seem paradoxical that more papers can slow
progress until one considers how it affects researchers’ time. While rewards remain tied to
volume, prestige, and impact of publications, researchers will be nudged away from riskier,
local, interdisciplinary, and long-term work. The result is a treadmill of constant activity with
limited progress whereas core scholarly practices – such as reading, reflecting and engaging
with others’ contributions – is de-prioritized. What looks like productivity often masks
intellectual exhaustion built on a demoralizing, narrowing scientific vision.

A table of profit margins across industries. The section of text related to this table is below:
1. The four-fold drain
1.1 Money
Currently, academic publishing is dominated by profit-oriented, multinational companies for
whom scientific knowledge is a commodity to be sold back to the academic community who
created it. The dominant four are Elsevier, Springer Nature, Wiley and Taylor & Francis,
which collectively generated over US$7.1 billion in revenue from journal publishing in 2024
alone, and over US$12 billion in profits between 2019 and 2024 (Table 1A). Their profit
margins have always been over 30% in the last five years, and for the largest publisher
(Elsevier) always over 37%.
Against many comparators, across many sectors, scientific publishing is one of the most
consistently profitable industries (Table S1). These financial arrangements make a substantial
difference to science budgets. In 2024, 46% of Elsevier revenues and 53% of Taylor &
Francis revenues were generated in North America, meaning that North American
researchers were charged over US$2.27 billion by just two for-profit publishers. The
Canadian research councils and the US National Science Foundation were allocated US$9.3
billion in that year.

The costs of inaction are plain: wasted public funds, lost researcher time, compromised
scientific integrity and eroded public trust. Today, the system rewards commercial publishers
first, and science second. Without bold action from the funders we risk continuing to pour
resources into a system that prioritizes profit over the advancement of scientific knowledge.
We wrote the Strain on scientific publishing to highlight the problems of time & trust. With a fantastic group of co-authors, we present The Drain of Scientific Publishing:
a 🧵 1/n
Drain: arxiv.org/abs/2511.04820
Strain: direct.mit.edu/qss/article/...
Oligopoly: direct.mit.edu/qss/article/...
11.11.2025 11:52 — 👍 641 🔁 453 💬 8 📌 66
Echoing this: Child poverty shouldn't be reduced to an accounting exercise. But when it is, we should at the very least factor in the costs of keeping children in poverty, costs affecting the public budget of tomorrow.
www.transformingsociety.co.uk/2025/10/06/t...
10.11.2025 14:59 — 👍 4 🔁 0 💬 1 📌 0

I can’t envisage a child poverty strategy which garners any credibility without fully scrapping the two-child limit.
Unconvinced? Check out (even better share) this summary of the peer-reviewed evidence base @kittyjstewart.bsky.social @aaronreeves.bsky.social
largerfamilies.study/publications...
01.11.2025 16:37 — 👍 64 🔁 47 💬 3 📌 2
Really appreciate this review of our book (w/ @alexhanna.bsky.social)
"By insisting on the term “automation,” Bender and Hanna reveal that what’s sold as innovation is often just labor displacement with better branding."
"…a demystifying, often hilarious lexicon that cuts through the fog of hype."
31.10.2025 15:56 — 👍 148 🔁 44 💬 0 📌 3

Let Them Eat Large Language Models: Artificial Intelligence and Austerity in the Neoliberal University
Martha Kenney and Martha Lincoln
Abstract
This article examines the expansion of generative artificial intelligence (genAI) into higher education. We argue that genAI’s incursion into university systems represents an effort by Silicon Valley to capture lucrative new markets for their products, as well as enhanced credibility by association. Drawing on our experience as faculty in the California State University (CSU) system—the first university system to contract with OpenAI to provide ChatGPT Edu system-wide—we assess the rhetoric that justifies and legitimizes genAI contracts in higher education. We suggest that the uncritical adoption of genAI in higher education poses problems for labor conditions, the integrity of intellectual property, and student learning on campuses, particularly under the conditions of austerity that are commonly found in public universities.
New preprint alert! 🚨
“Let Them Eat Large Language Models: Artificial Intelligence and Austerity in the Neoliberal University”
25.10.2025 17:05 — 👍 408 🔁 157 💬 9 📌 10

Belgian AI scientists resist the use of AI in academia
Several AI scientists have published an open letter calling for a ban on AI use by students.
Belgian AI scientists are advocating *against* the use of AI in academia. “If independent thinking is no longer encouraged at university, where would it?” apache.be/2025/10/24/b...
24.10.2025 09:34 — 👍 388 🔁 208 💬 7 📌 35

www.peoplespolicyproject.org/2025/10/26/d...
26.10.2025 18:28 — 👍 309 🔁 22 💬 4 📌 1
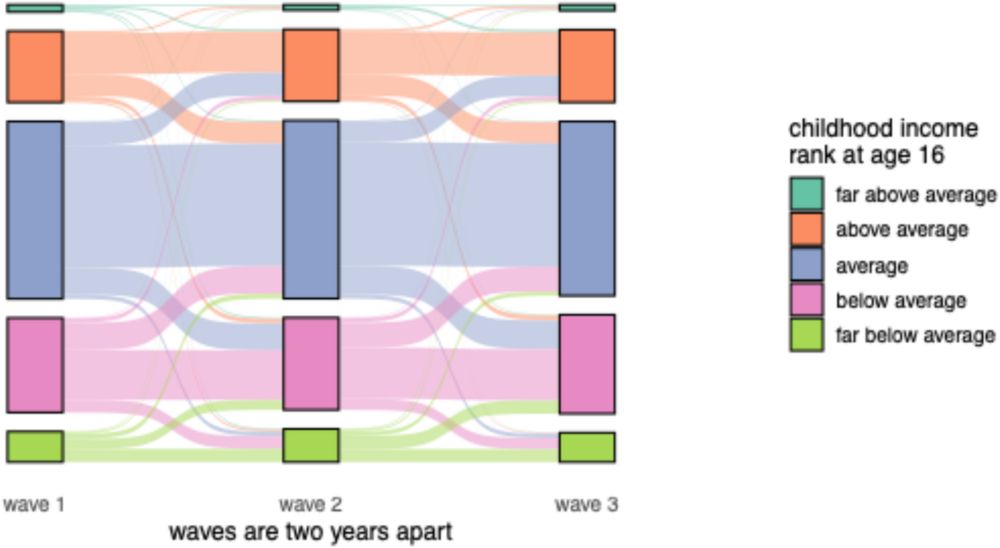
Growing up Different(ly than Last Time We Asked): Social Status and Changing Reports of Childhood Income Rank - Social Indicators Research
How we remember our past can be shaped by the realities of our present. This study examines how changes to present circumstances influence retrospective reports of family income rank at age 16. While retrospective survey data can be used to assess the long-term effects of childhood conditions, present-day circumstances may “anchor” memories, causing shifts in how individuals recall and report past experiences. Using panel data from the 2006–2014 General Social Surveys (8,602 observations from 2,883 individuals in the United States), we analyze how changes in objective and subjective indicators of current social status—income, financial satisfaction, and perceived income relative to others—are associated with changes in reports of childhood income rank, and how this varies by sex and race/ethnicity. Fixed-effects models reveal no significant association between changes in income and in childhood income rank. However, changes in subjective measures of social status show contrasting effects, as increases in current financial satisfaction are associated with decreases in childhood income rank, but increases in current perceived relative income are associated with increases in childhood income rank. We argue these opposing effects follow from theories of anchoring in recall bias. We further find these effects are stronger among males but are consistent across racial/ethnic groups. This demographic heterogeneity suggests that recall bias is not evenly distributed across the population and has important implications for how different groups perceive their own pasts. Our findings further highlight the malleability of retrospective perceptions and their sensitivity to current social conditions, offering methodological insights into survey reliability and recall bias.
The GSS asked the same people about their childhood income rank three different times. 56% changed their answer, even though what was trying to be measured couldn’t change! We dig into this in a new article at @socialindicators.bsky.social.
doi.org/10.1007/s112...
🧵👇 (1/5)
10.10.2025 14:05 — 👍 97 🔁 41 💬 2 📌 5

Let’s do statistics the other way around
Summer in Berlin – the perfect time and place to explore the city, take a walk in the Görli, go skinny dipping in the Spree, attend an overcrowded, overheated conference symposium on cross-lagged pane...
Currently attending a conference & our field is quite a bit into fancy modeling, so it’s time to repost this blog post.
Don’t try to squeeze your research question into whatever model is fashionable right now; try to build the right model for your research question.
www.the100.ci/2024/08/27/l...
23.09.2025 04:38 — 👍 89 🔁 19 💬 8 📌 1

An illustration of me, and the headline: "AI agents are coming for your privacy, warns Meredith Whittaker
The Signal Foundation’s president worries they will also blunt competition and undermine cyber-security"

To put it bluntly, the path currently being taken towards agentic AI leads to an elimination of privacy and security at the application layer. It will not be possible for apps like Signal—the messaging app whose foundation I run—to continue to provide strong privacy guarantees, built on robust and openly validated encryption, if device-makers and OS developers insist on puncturing the metaphoric blood-brain barrier between apps and the OS. Feeding your sensitive Signal messages into an undifferentiated data slurry connected to cloud servers in service of their AI-agent aspirations is a dangerous abdication of responsibility.

Happily, it’s not too late. There is much that can still be done, particularly when it comes to protecting the sanctity of private data. What’s needed is a fundamental shift in how we approach the development and deployment of AI agents. First, privacy must be the default, and control must remain in the hands of application developers exercising agency on behalf of their users. Developers need the ability to designate applications as “sensitive” and mark them as off-limits to agents, at the OS level and otherwise. This cannot be a convoluted workaround buried in settings; it must be a straightforward, well-documented mechanism (similar to Global Privacy Control) that blocks an agent from accessing our data or taking actions within an app.
Second, radical transparency must be the norm. Vague assurances and marketing-speak are no longer acceptable. OS vendors have an obligation to be clear and precise about their architecture and what data their AI agents are accessing, how it is being used and the measures in place to protect it.
📣 NEW -- In The Economist, discussing the privacy perils of AI agents and what AI companies and operating systems need to do--NOW--to protect Signal and much else!
www.economist.com/by-invitatio...
09.09.2025 11:44 — 👍 878 🔁 281 💬 12 📌 31

These Are Not the Effects You Are Looking for: Causality and the Within-/Between-Persons Distinction in Longitudinal Data Analysis
In psychological science, researchers often pay particular attention to the distinction between within- and between-persons relationships in longitudinal data analysis. Here, we aim to clarify the relationship between the within- and between-persons distinction and causal inference and show that the distinction is informative but does not play a decisive role in causal inference. Our main points are threefold. First, within-persons data are not necessary for causal inference; for example, between-persons experiments can inform about (average) causal effects. Second, within-persons data are not sufficient for causal inference; for example, time-varying confounders can lead to spurious within-persons associations. Finally, despite not being sufficient, within-persons data can be tremendously helpful for causal inference. We provide pointers to help readers navigate the more technical literature on longitudinal models and conclude with a call for more conceptual clarity: Instead of letting statistical models dictate which substantive questions researchers ask, researchers should start with well-defined theoretical estimands, which in turn determine both study design and data analysis.
It's like an association, but more causal.
This reasoning is very prevalent in psych as well (in particular when it comes to "lagged effects", aka lagged associations, and "within-person associations") which is why we wrote a paper about it:
journals.sagepub.com/doi/10.1177/...
21.08.2025 06:35 — 👍 75 🔁 17 💬 4 📌 1

• Resist the introduction of AI in our own software systems, from Microsoft to OpenAI to Apple. It is not in our interests to let our processes be corrupted and give away our data to be used to train models that are not only useless to us, but also harmful.
• Ban AI use in the classroom for student assignments, in the same way we ban essay mills and other forms of plagiarism. Students must be protected from de-skilling and allowed space and time to perform their assignments themselves.
• Cease normalising the AI hype and the lies which are prevalent in the technology industry's framing of these technologies. The technologies do not have the advertised capacities and their adoption puts students and academics at risk of violating ethical, legal, scholarly, and scientific standards of reliability, sustainability, and safety.
• Fortify our academic freedom as university staff to enforce these principles and standards in our classrooms and our research as well as on the computer systems we are obliged to use as part of our work. We as academics have the right to our own spaces.
• Sustain critical thinking on AI and promote critical engagement with technology on a firm academic footing. Scholarly discussion must be free from the conflicts of interest caused by industry funding, and reasoned resistance must always be an option.
If you agree with our 5 requests to our universities, please sign 🖊️ the open letter and don’t forget to confirm your email! ☺️🙏
openletter.earth/open-letter-...
28.06.2025 19:52 — 👍 261 🔁 118 💬 7 📌 19
"Simpson's gender-equality paradox" surely deserve some award for best title 👑
The gender-equality paradox seems really central to some narrative people have constructed (and successfully sold). I absolutely wouldn't be surprised if it turned out 100% confounding.>
www.pnas.org/doi/10.1073/...
12.06.2025 15:11 — 👍 166 🔁 42 💬 7 📌 9

The Means of Prediction
An eye-opening examination of how power—not technology—will define life with AI. AI is inescapable, from its mundane uses online to its increasingly consequential decision-making in courtrooms,…
In case somebody missed this yesterday, while watching a political car-crash unfold:
"The Means of Prediction - How AI Really Works (and Who Benefits)"
is now in the UChicago Press catalog, and available for pre-order online!
press.uchicago.edu/ucp/books/bo...
06.06.2025 15:17 — 👍 33 🔁 9 💬 0 📌 0
New research from me&@agpines.bsky.social
Congress is pushing work requirements for Medicaid&SNAP. You’ve heard these kick eligible folks off (@pamherd.bsky.social @donmoyn.bsky.social), don't increase work&cause hunger (@laurenhlb.bsky.social @chloeneast.bsky.social). But wait there's more! 1/n
27.05.2025 13:51 — 👍 65 🔁 31 💬 5 📌 8
Built stuff for working people and solved crises @WhiteHouse @USDS 🚀 | itslukefarrell.substack.com
Nuffield Postdoctoral Prize Research Fellow in Sociology.
Environment | Fertility & Reproductive Health | Early Life Exposures
📍Nuffield College, Oxford @nuffieldcollege.bsky.social & Leverhulme Centre for Demographic Science @oxforddemsci.bsky.social
#VID | Ein Institut der Österreichischen Akademie der Wissenschaften #ÖAW | Vienna Institute of Demography of the Austrian Academy of Sciences
https://www.oeaw.ac.at/vid
https://www.oeaw.ac.at/oeaw/impressum
Demographer. Assistant Professor @ UT-Austin.
caseybreen.com
Lecturer, Department of Sociological Studies, University of Sheffield
Sociology and Cultural Studies of elites, inequality, private wealth, dynasties, higher education, university democracy etc. Associate Professor of Sociology. https://orcid.org/0000-0003-3845-8140
Professor of Sociology, University of California, Irvine;
economic sociology, culture, emotions, work & organizations, comparative political economy
https://faculty.sites.uci.edu/ninabandelj/
Associate Professor, History of Art & Architecture, UMass Amherst.
Impressive Politics: Print before the Press in Late Medieval England (UPenn Press, forthcoming). http://sonjadrimmer.com/about-forte (She/her)
Our work sits at the intersection of research, public policy, and efforts to reduce inequality
Email: info@theeconomicmisfit.com
https://theeconomicmisfit.com/
European Association for Population Studies (EAPS) is a non-profit, professional organization promoting population studies.
https://www.eaps.nl/
Economist at Columbia (Econ & SIPA), studying firms & development.
http://www.columbia.edu/~ev2124/
PhD Candidate in labor and gender @Uppsala university.
https://sites.google.com/view/elinsundberg
An interdisciplinary research institute focusing on the development of sustainable and inclusive cities and city regions at the University of Liverpool.
Oxfam is a world-wide development organization that mobilizes the power of people against poverty. #TheFutureisEqual
Accelerating the transition to open science in the Netherlands by funding & supporting the community.
www.openscience.nl
Co-Head of Social Policy, School for Business and Society, Uni York @uoysbs.bsky.social | Work on self-employment, labour market policy | Teaching & Learning lead for @socialpolicyuk.bsky.social | Co-Editor of Social Policy & Society | Opinions my own
Advice researcher & writer at Citizens Advice Scotland • Former welfare rights adviser, poverty researcher, polsci grad • Interested in policy and information for the public good • Outer Hebridean in Glasgow • Inexplicably sporty gayboy 🏳️🌈
Enseignant chercheur en économie.
Économie politique des transformations de l'Etat social.
#econsky
associate editor at liberal currents. neonliberal. she/her.
Public sociologist & socialist. Interested in elites, knowledge & communication. Author of 'The BBC: Myth of a Public Service'.
































