This week's #PaperILike is "The Utility of Temporal Abstraction in Reinforcement Learning" (Jong et al., AAMAS 2008).
My favorite underrated paper in hierarchical RL. Unpacks how options can help *or hurt* learning performance. Fun writing.
PDF: www.ifaamas.org/Proceedings/...
03.08.2025 12:30 — 👍 2 🔁 0 💬 0 📌 0
This week's #PaperILike is "Width and Serialization of Classical Planning Problems" (Lipovetzky & Geffner, ECAI 2012).
If you only read a few classical planning papers, this should be one! Illuminating and practically useful.
PDF: www-i6.informatik.rwth-aachen.de/~hector.geff...
27.07.2025 13:02 — 👍 1 🔁 1 💬 0 📌 0
Stop! Planner Time: Metareasoning for Probabilistic Planning Using Learned Performance Profiles
| Proceedings of the AAAI Conference on Artificial Intelligence
This week's #PaperILike is "Stop! Planner Time: Metareasoning for Probabilistic Planning Using Learned Performance Profiles" (Budd et al., AAAI 2024).
Metareasoning is increasingly important as we continue to make progress on "reasoning."
PDF: ojs.aaai.org/index.php/AA...
20.07.2025 13:44 — 👍 2 🔁 0 💬 0 📌 0
This week's #PaperILike is "Effort Level Search in Infinite Completion Trees with Application to Task-and-Motion Planning" (Toussaint et al., ICRA 2024).
Addresses the meta-reasoning challenge that is core to TAMP. Toussaint is always worth a read.
PDF: www.user.tu-berlin.de/mtoussai/24-...
06.07.2025 14:19 — 👍 3 🔁 1 💬 0 📌 0
This week's #PaperILike is "Learning over Subgoals for Efficient Navigation of Structured, Unknown Environments" (Stein et al., CoRL 2018).
A highly original combination of learning + planning that is still underrated (despite winning a CoRL award!)
PDF: proceedings.mlr.press/v87/stein18a...
22.06.2025 14:30 — 👍 3 🔁 1 💬 0 📌 0
YouTube video by Valentin Hartmann
Long-Horizon Multi-Robot Rearrangement Planning for Construction Assembly
This week's #PaperILike is "Long-Horizon Multi-Robot Rearrangement Planning for Construction Assembly" (Hartmann et al., TRO 2022).
Take two minutes to watch this video: www.youtube.com/watch?v=Gqho...
I don't use a lot of emojis, but 🤯
PDF: arxiv.org/abs/2106.02489
15.06.2025 12:50 — 👍 12 🔁 2 💬 0 📌 0
This week's #PaperILike is "Guaranteed Discovery of Control-Endogenous Latent States with Multi-Step Inverse Models" (Lamb et al., 2022).
Part of an exciting line of work: sites.google.com/view/agent-i...
This one has an awesome related work section.
PDF: arxiv.org/abs/2207.08229
01.06.2025 11:51 — 👍 3 🔁 0 💬 0 📌 0
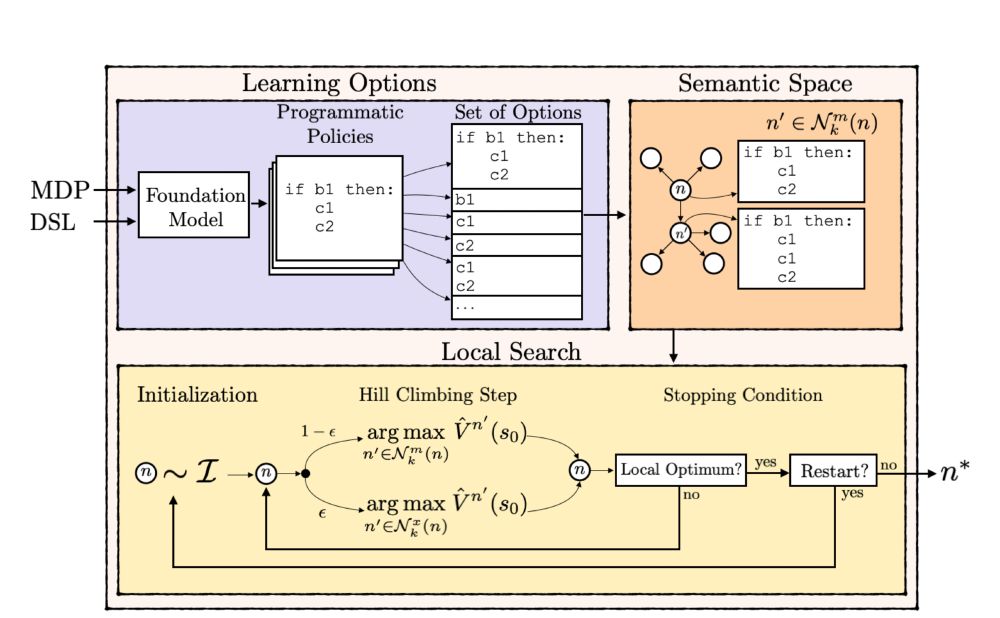
🧵1/ New paper! 📄 InnateCoder: Learning Programmatic Options with Foundation Models
This is Rubens Moraes' final chapter of his PhD thesis from Universidade Federal de Viçosa, Brazil, in collaboration with Quazi Sadmine and Hendrik Baier.
arXiv: arxiv.org/abs/2505.12508
23.05.2025 20:31 — 👍 5 🔁 3 💬 1 📌 0
Did something today that I never expected to do: made a donation to Harvard!
23.05.2025 18:41 — 👍 1 🔁 0 💬 0 📌 0
This week's #PaperILike is "Deep Reinforcement Learning that Matters" (Henderson et al., AAAI 2018).
A great primer on how to do deep RL rigorously. Among the papers that I share the most, especially in reviews!
PDF: arxiv.org/pdf/1709.06560
27.04.2025 14:19 — 👍 5 🔁 0 💬 0 📌 0
This week's #PaperILike is "Navigation Among Movable Obstacles" (Stilman & Kuffner, 2005).
An important early paper that informed a lot of subsequent work in task and motion planning (TAMP). Also, pretty impressive figures for 2005!
PDF: www.golems.org/papers/Stilm...
20.04.2025 15:16 — 👍 2 🔁 0 💬 0 📌 0

FINALLY.
Some gumption from the President of Harvard today:
14.04.2025 17:47 — 👍 107 🔁 15 💬 2 📌 0

Opinion | A Playbook for Law Firms and Colleges to Stand Up to President Trump
Law firms and universities do not need to capitulate. Here’s how they can fight back.
Thread: A surprisingly strong NYT editorial:
www.nytimes.com/2025/04/06/o...
"the most likely path to American autocracy depends on not only a power-hungry president but also the voluntary capitulation of a cowed civil society. It depends on the mistaken belief that a president is invincible."...
06.04.2025 13:18 — 👍 47 🔁 24 💬 1 📌 0
This week's #PaperILike is "Control-Limited Differential Dynamic Programming" (Tassa et al., ICRA 2014).
This paper has an extremely clear and concise overview of trajectory optimization for robotics, especially DDP.
PDF: www.roboti.us/lab/papers/T...
06.04.2025 12:49 — 👍 0 🔁 0 💬 0 📌 0
This week's #PaperILike is "Impossibly Good Experts and How to Follow Them" (Walsman et al., ICLR 2023).
A very well written paper that will be especially interesting if you're using teacher-student training in your work.
PDF: openreview.net/pdf?id=sciA_...
30.03.2025 15:49 — 👍 0 🔁 0 💬 0 📌 0
This week's #PaperILike is "Gaussian Process Implicit Surfaces for Shape Estimation and Grasping" (Dragiev et al., ICRA 2011).
Useful if you're thinking about implicit representations for manipulation. Also +1 for uncertainty quantification.
PDF: argmin.lis.tu-berlin.de/papers/11-dr...
23.03.2025 16:32 — 👍 5 🔁 0 💬 1 📌 0
Simple random search of static linear policies is competitive for reinforcement learning
This week's #PaperILike is "Simple random search of static linear policies is competitive for RL" (Mania et al., NeurIPS 2018).
"Simple baselines should be established before moving forward to more complex [ones]." Generally agree!
PDF: proceedings.neurips.cc/paper/2018/h...
16.03.2025 16:34 — 👍 7 🔁 2 💬 1 📌 0
This week's #PaperILike (well, book) is "The Structure of Scientific Revolutions" (Kuhn, 1962).
Zooming way, way out and thinking about what we're all doing here. (I'll get back to robots & AI next week.)
PDF (but also buy it): www.lri.fr/~mbl/Stanfor...
23.02.2025 14:40 — 👍 3 🔁 0 💬 0 📌 0
This week's #PaperILike is "Learning Reusable Manipulation Strategies" (Mao et al., CoRL 2023).
This paper is my favorite recent account of how robots can learn & dramatically generalize "tricks" or "mechanisms" from very little data.
PDF: arxiv.org/pdf/2311.03293
16.02.2025 17:52 — 👍 1 🔁 0 💬 0 📌 0
Research Scientist at Google DeepMind, interested in multiagent reinforcement learning, game theory, games, and search/planning.
Lover of Linux 🐧, coffee ☕, and retro gaming. Big fan of open-source. #gohabsgo 🇨🇦
For more info: https://linktr.ee/sharky6000
Señor swesearcher @ Google DeepMind, adjunct prof at Université de Montréal and Mila. Musician. From 🇪🇨 living in 🇨🇦.
https://psc-g.github.io/
Associate Professor in EECS at MIT. Neural nets, generative models, representation learning, computer vision, robotics, cog sci, AI.
https://web.mit.edu/phillipi/
Artificial Intelligence 🧠 Machine Learning 🕹️ Robotics 🤖
PhD 🎓 in CS 💻 from @ias-tudarmstadt.bsky.social | @tuda.bsky.social
Senior Scientist @ Honda Research Institute EU
https://dtannebe.github.io/
AI technical governance & risk management research. PhD Candidate at MIT CSAIL. Also at https://x.com/StephenLCasper.
https://stephencasper.com/
Innovating the future, one robot at a time! 🤖 Discover more at ieee-ras.org.
Associate Professor - University of Alberta
Canada CIFAR AI Chair with Amii
Machine Learning and Program Synthesis
he/him; ele/dele 🇨🇦 🇧🇷
https://www.cs.ualberta.ca/~santanad
Recent Robotics PhD passionate about inclusive & equitable knowledge sharing, especially about tech. My research is in combining classical robotics with AI. I love edible plants and composting. Pronouns: them/them preferred
We develop perception, control, & planning algorithms for robot autonomy.
theairlab.org
@cmurobotics.bsky.social | http://youtube.com/airlab
Assistant professor at University of Iowa, formerly at Bucknell University, mathematical optimizer with an #orms PhD from Carnegie Mellon University, curious about scaling up constraint learning, proud father of two
Studying cognition in humans and machines https://scholar.google.com/citations?user=WCmrJoQAAAAJ&hl=en
Professor of Computing, I do research on robotics and AI. I also ski.
https://robot-learning.cs.utah.edu/thermans
Parody. Some hate Trump. I don't. He's just a wanker. We, on the other hand, are COLONIZED by a wanker.
Chief Scientist at the UK AI Security Institute (AISI). Previously DeepMind, OpenAI, Google Brain, etc.
Roboticist
Chief Scientist, Berkshire Grey
Professor Emeritus, Carnegie Mellon University
Blogging at https://mtmason.com
computational cognitive science he/him
http://colala.berkeley.edu/people/piantadosi/
Researcher @ Google DeepMind and Honorary Fellow @ U of Edinburgh.
RL, philosophy, foundations, AI.
https://david-abel.github.io
Anti-cynic. Towards a weirder future. Reinforcement Learning, Autonomous Vehicles, transportation systems, the works. Asst. Prof at NYU
https://emerge-lab.github.io
https://www.admonymous.co/eugenevinitsky
computational cog sci • problem solving and social cognition • asst prof at NYU • https://codec-lab.github.io/
PhD student at MIT studying program synthesis, probabilistic programming, and cognitive science. she/her