
Brazil shows how it’s done in a democracy
11.09.2025 20:37 — 👍 313 🔁 83 💬 5 📌 6
@programsynthesis.bsky.social
Associate Professor - University of Alberta Canada CIFAR AI Chair with Amii Machine Learning and Program Synthesis he/him; ele/dele 🇨🇦 🇧🇷 https://www.cs.ualberta.ca/~santanad

A graph showing that a rules-based approach consistently underperformed at achieving desired anxiety levels measured in normalized SCL compared to an RL approach.

A brownish red virtual spider a medium distance away

A close by black fuzzy spider
Excited to announce that our work on Reinforcement Learning for Arachnophobia treatment has been accepted at ACM Transactions on Interactive Intelligent Systems! We found that an RL agent could more effectively adapt VR spiders to achieve specified anxiety levels in users compared to current SOTA.
25.08.2025 01:39 — 👍 55 🔁 7 💬 5 📌 9Was talking to a student who wasn't sure about why one would get a PhD. So I wrote up a list of reasons!
www.eugenevinitsky.com/posts/reason...
Previous work has shown that programmatic policies—computer programs written in a domain-specific language—generalize to out-of-distribution problems more easily than neural policies.
Is this really the case? 🧵

Sometimes, neural networks (with little tweaks) are enough. Other times, solving the task requires a programmatic representation to capture algorithmic structure.
Preprint: arxiv.org/abs/2506.14162
1. Is the representation expressive enough to find solutions that generalize?
2. Can our search procedure find a policy that generalizes?
So, when should we use neural vs. programmatic policies for OOD generalization?
Rather than treating programmatic policies as the default, we should ask:
As an illustrative example, we changed the grid-world task so that a solution policy must use a queue or stack to solve a navigation task. FunSearch found a Python program that provably generalizes. As one would expect, neural nets couldn’t solve the problem.
02.07.2025 22:12 — 👍 1 🔁 0 💬 1 📌 0Are neural and programmatic policies similar in terms OOD generalization? We don't think so. We think that benchmark problems used in previous work actually undervalue what programmatic representations can do.
02.07.2025 22:12 — 👍 1 🔁 0 💬 1 📌 0Programmatic policies appeared to generalize better in previous work because they never learned to go fast in the easy training tracks. Neural nets optimized speed well, which made it difficult to generalize to tracks with sharp curves.
02.07.2025 22:12 — 👍 1 🔁 0 💬 1 📌 0In a car-racing task, we adjusted the reward to encourage cautious driving. Neural nets generalized just as well as programmatic policies.
02.07.2025 22:12 — 👍 1 🔁 0 💬 1 📌 0We had to perform simple changes to the neural policies' training pipeline to attain similar OOD generalization to that exhibited by programmatic ones.
In a grid-world problem, we used the same sparse observation space as used with the programmatic policies augmented with the agent's last action.
In a preprint, led by my Master's student Amirhossein Rajabpour, we revisit some of these OOD generalization claims and show that neural policies generalize just as well as programmatic ones on benchmark problems used in previous work.
Preprint: arxiv.org/abs/2506.14162
Previous work has shown that programmatic policies—computer programs written in a domain-specific language—generalize to out-of-distribution problems more easily than neural policies.
Is this really the case? 🧵
If like me your Discover feed has been even worse lately and you are here for ML/AI news and discussion, check out these two feeds:
- Paper Skygest
- ML Feed: Trending
Links below 👇
As AI agents face increasingly long and complex tasks, decomposing them into subtasks becomes increasingly appealing.
But how do we discover such temporal structure?
Hierarchical RL provides a natural formalism-yet many questions remain open.
Here's our overview of the field🧵

As hot as this summer is, it’s also one of the coolest we’ll ever enjoy again.
Just how much hotter and deadlier summers will get is still up to us. Right now we’re working hard to make them worse
🎁 link to my @opinion.bloomberg.com column:
www.bloomberg.com/opinion/arti...

Hiring a postdoc to scale up and deploy RL-based planning onto some self-driving cars! We'll be building on arxiv.org/abs/2502.03349 and learn what the limits and challenges of RL planning are. Shoot me a message if interested and help spread the word please!
Full posting to come in a bit.
In addition to Sat's pointers, I would also take a look at the following recent paper by @swarat.bsky.social:
www.cs.utexas.edu/~swarat/pubs...
Also, the following paper covers most of the recent works on neuro-guided bottom-up synthesis algorithms:
webdocs.cs.ualberta.ca/~santanad/pa...
We’re extending the AIIDE deadline! Partially due to author requests, partially due to a significant increase in submissions meaning I need to increase the PC!
16.06.2025 18:21 — 👍 5 🔁 4 💬 1 📌 1I wanted to thank the folks who reviewed our paper. Your feedback helped us improve our work, especially by asking us to include experiments on more difficult instances and the TSP. Thank you!
13.06.2025 03:29 — 👍 0 🔁 0 💬 0 📌 0Still, many important problems with real-world applications, such as the TSP and program synthesis, share some of the properties we assume in this work.
13.06.2025 03:29 — 👍 0 🔁 0 💬 1 📌 0The work has a few limitations. The policy learning scheme was evaluated only on needle-in-the-haystack deterministic problems. Also, since we are using tree search algorithms, we assume the agent has access to an efficient forward model.
13.06.2025 03:29 — 👍 0 🔁 0 💬 1 📌 0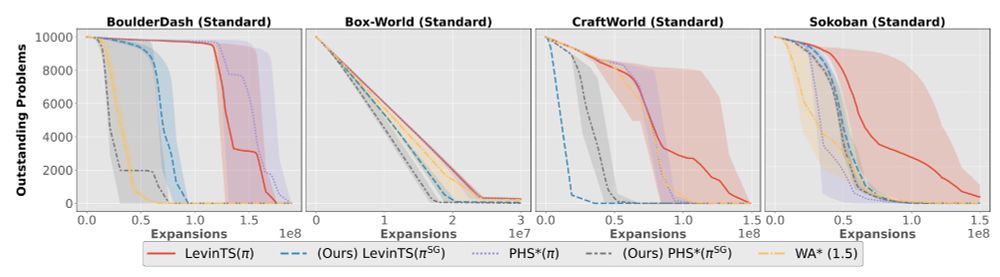
In other cases, where clustering seems unable to find relevant structure, the subgoal-based policies do not seem to harm the search, as in Sokoban problems.
13.06.2025 03:29 — 👍 0 🔁 0 💬 1 📌 0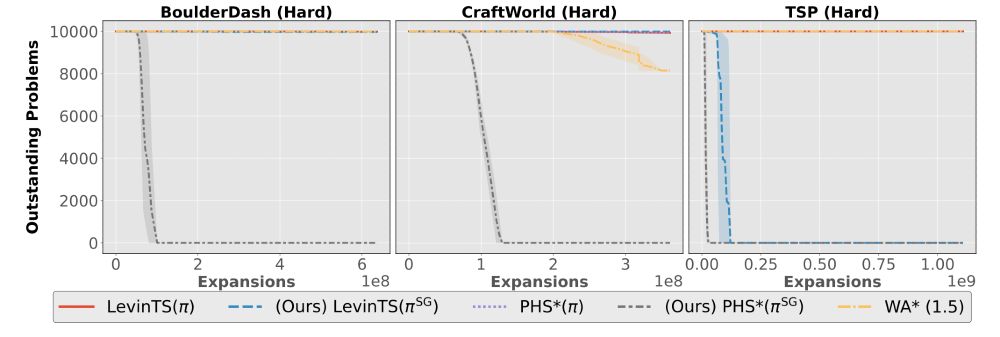
The empirical results are strong when clustering effectively detects the problem's underlying structure.
13.06.2025 03:29 — 👍 0 🔁 0 💬 1 📌 0To illustrate, this approach allows the agent to learn how to navigate between cities in a variant of the traveling salesman problem before the agent solves any TSP problem—the agent learns from failed searches.
13.06.2025 03:29 — 👍 0 🔁 0 💬 1 📌 0The approach learns policies for solving subgoals and a policy to mix the subgoal policies. Ultimately, we have a policy that can be used with any Levin-based algorithm, thus retaining their strong guarantees.
13.06.2025 03:29 — 👍 0 🔁 0 💬 1 📌 0Instead, Jake invented a method that learns subgoals from the discarded data. It builds a graph from the expanded search trees and uses a clustering algorithm to break the problem into subproblems, forming subgoals.
13.06.2025 03:29 — 👍 0 🔁 0 💬 1 📌 0Jake's paper offers a solution to something that has always bugged me in previous works combining learning and search. Previous approaches to learning a policy and/or a heuristic discarded failed searches. This includes the original 2011 Bootstrap paper.
www.sciencedirect.com/science/arti...
If you are not familiar with policy-guided tree search, here are some papers. Read these, and you might never use MCTS again to solve single-agent problems. ;-)
webdocs.cs.ualberta.ca/~santanad/pa...
webdocs.cs.ualberta.ca/~santanad/pa...
webdocs.cs.ualberta.ca/~santanad/pa...




















