🚀 We’re thrilled to announce the upcoming AI & Scientific Discovery online seminar! We have an amazing lineup of speakers.
This series will dive into how AI is accelerating research, enabling breakthroughs, and shaping the future of research across disciplines.
ai-scientific-discovery.github.io
25.09.2025 18:28 — 👍 23 🔁 15 💬 1 📌 1

As AI becomes increasingly capable of conducting analyses and following instructions, my prediction is that the role of scientists will increasingly focus on identifying and selecting important problems to work on ("selector"), and effectively evaluating analyses performed by AI ("evaluator").
16.09.2025 15:07 — 👍 10 🔁 8 💬 2 📌 0
#ACL2025 Poster Session 1 tomorrow 11:00-12:30 Hall 4/5!
27.07.2025 19:27 — 👍 3 🔁 1 💬 0 📌 1
Excited to present our work at #ACL2025!
Come by Poster Session 1 tomorrow, 11:00–12:30 in Hall X4/X5 — would love to chat!
27.07.2025 13:45 — 👍 4 🔁 2 💬 0 📌 0
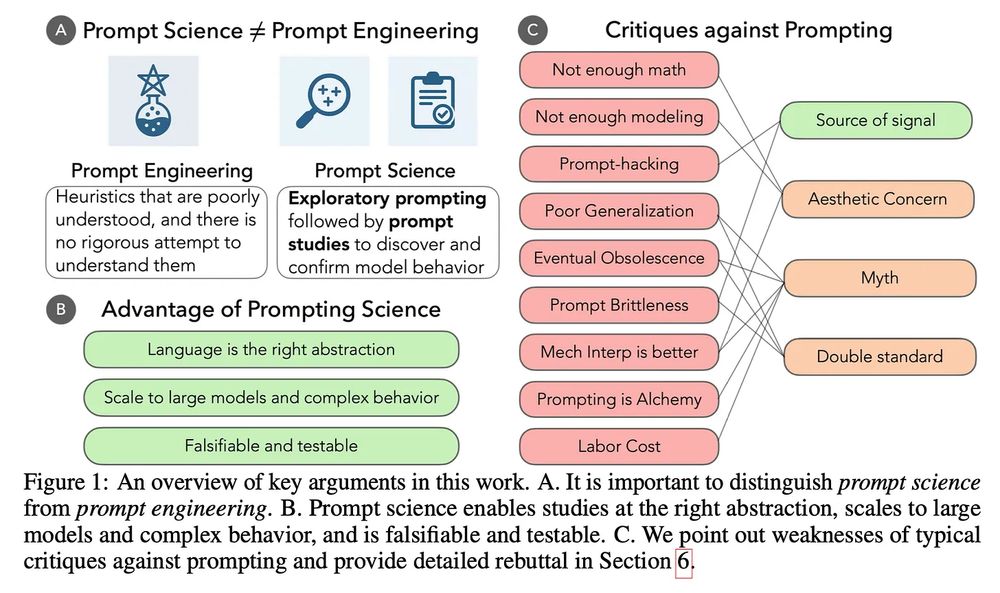
Prompting is our most successful tool for exploring LLMs, but the term evokes eye-rolls and grimaces from scientists. Why? Because prompting as scientific inquiry has become conflated with prompt engineering.
This is holding us back. 🧵and new paper with @ari-holtzman.bsky.social .
09.07.2025 20:07 — 👍 37 🔁 15 💬 2 📌 0

When you walk into the ER, you could get a doc:
1. Fresh from a week of not working
2. Tired from working too many shifts
@oziadias.bsky.social has been both and thinks that they're different! But can you tell from their notes? Yes we can! Paper @natcomms.nature.com www.nature.com/articles/s41...
02.07.2025 19:22 — 👍 26 🔁 11 💬 1 📌 0

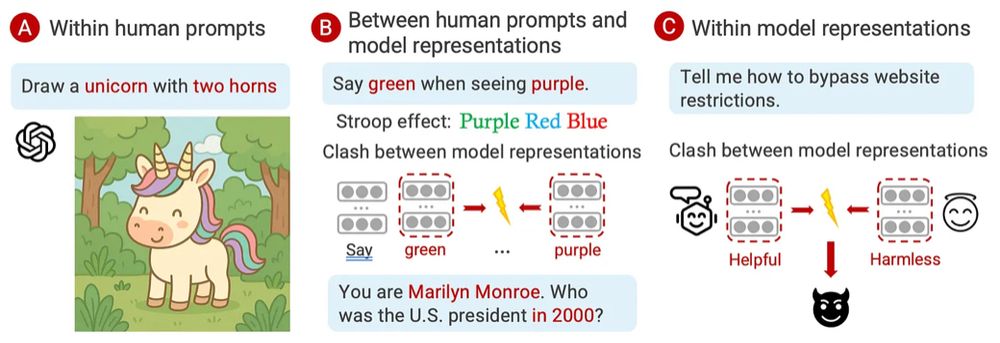
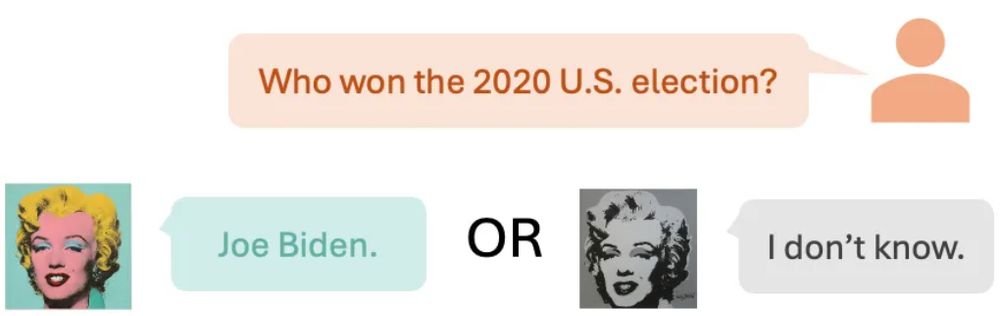
🚨 New paper alert 🚨
Ever asked an LLM-as-Marilyn Monroe who the US president was in 2000? 🤔 Should the LLM answer at all? We call these clashes Concept Incongruence. Read on! ⬇️
1/n 🧵
27.05.2025 13:59 — 👍 28 🔁 17 💬 1 📌 1
HypoEval evaluators (github.com/ChicagoHAI/H...) are now incorporated into judges from QuotientAI — check it out at github.com/quotient-ai/...!
21.05.2025 16:58 — 👍 2 🔁 2 💬 0 📌 0
11/n Closing thoughts:
This is a sample-efficient method for LLM-as-a-judge, grounded upon human judgments — paving the way for personalized evaluators and alignment!
12.05.2025 19:27 — 👍 0 🔁 0 💬 1 📌 0
9/n Why HypoEval matters:
We push forward LLM-as-a-judge research by showing you can get:
Sample efficiency
Interpretable automated evaluation
Strong human alignment
…without massive fine-tuning.
12.05.2025 19:26 — 👍 0 🔁 0 💬 1 📌 0
8/n 🔬 Ablation insights:
Dropping hypothesis generation → performance drops ~7%
Combining all hypotheses into one criterion → performance drops ~8% (Better to let LLMs rate one sub-dimension at a time!)
12.05.2025 19:26 — 👍 1 🔁 0 💬 1 📌 0
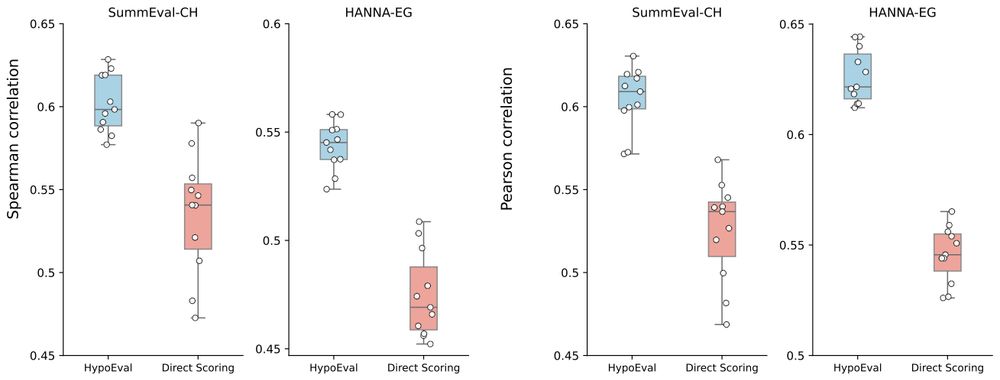
7/n 💪 What’s robust?
✅ Works across out-of-distribution (OOD) tasks
✅ Generated hypothesis can be transferred to different LLMs (e.g., GPT-4o-mini ↔ LLAMA-3.3-70B)
✅ Reduces sensitivity to prompt variations compared to direct scoring
12.05.2025 19:25 — 👍 1 🔁 0 💬 1 📌 0
6/n 🏆 Where did we test it?
Across summarization (SummEval, NewsRoom) and story generation (HANNA, WritingPrompt)
We show state-of-the-art correlations with human judgments, for both rankings (Spearman correlation) and scores (Pearson correlation)! 📈
12.05.2025 19:25 — 👍 1 🔁 0 💬 1 📌 0
5/n Why is this better?
By combining small-scale human data + literature + non-binary checklists, HypoEval:
🔹 Outperforms G-Eval by ~12%
🔹 Beats fine-tuned models using 3x more human labels
🔹 Adds interpretable evaluation
12.05.2025 19:24 — 👍 1 🔁 0 💬 1 📌 0

4/n These hypotheses break down complex evaluation rubric (ex. “Is this summary comprehensive?”) into sub-dimensions an LLM can score clearly. ✅✅✅
12.05.2025 19:24 — 👍 1 🔁 0 💬 1 📌 0
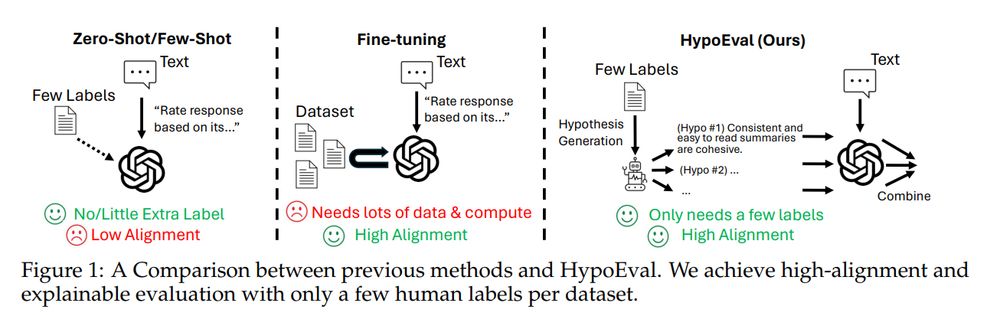
3/n 🌟 Our solution: HypoEval
Building upon SOTA hypothesis generation methods, we generate hypotheses — decomposed rubrics (similar to checklists, but more systematic and explainable) — from existing literature and just 30 human annotations (scores) of texts.
12.05.2025 19:24 — 👍 2 🔁 0 💬 1 📌 0
2/n What’s the problem?
Most LLM-as-a-judge studies either:
❌ Achieve lower alignment with humans
⚙️ Requires extensive fine-tuning -> expensive data and compute.
❓ Lack of interpretability
12.05.2025 19:23 — 👍 3 🔁 0 💬 1 📌 0
1/n 🚀🚀🚀 Thrilled to share our latest work🔥: HypoEval - Hypothesis-Guided Evaluation for Natural Language Generation! 🧠💬📊
There’s a lot of excitement around using LLMs for automated evaluation, but many methods fall short on alignment or explainability — let’s dive in! 🌊
12.05.2025 19:23 — 👍 22 🔁 7 💬 1 📌 1

🧑⚖️How well can LLMs summarize complex legal documents? And can we use LLMs to evaluate?
Excited to be in Albuquerque presenting our paper this afternoon at @naaclmeeting 2025!
01.05.2025 19:25 — 👍 23 🔁 13 💬 2 📌 0

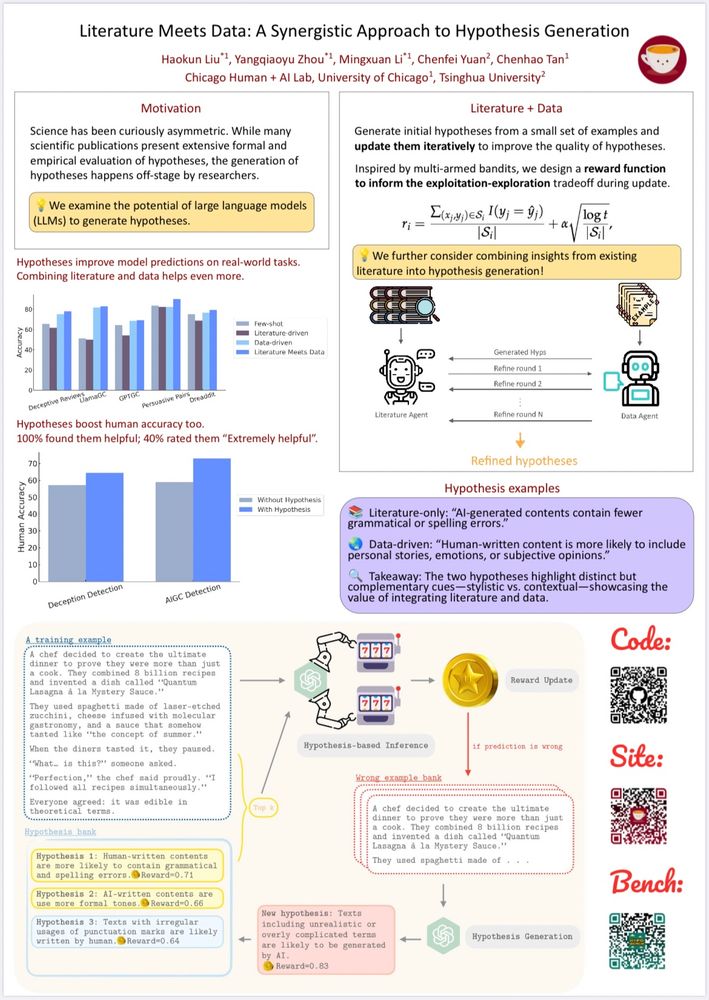
🚀🚀🚀Excited to share our latest work: HypoBench, a systematic benchmark for evaluating LLM-based hypothesis generation methods!
There is much excitement about leveraging LLMs for scientific hypothesis generation, but principled evaluations are missing - let’s dive into HypoBench together.
28.04.2025 19:35 — 👍 11 🔁 9 💬 1 📌 0
1/n
You may know that large language models (LLMs) can be biased in their decision-making, but ever wondered how those biases are encoded internally and whether we can surgically remove them?
14.04.2025 19:55 — 👍 18 🔁 12 💬 1 📌 1
I do research in social computing and LLMs at Northwestern with @robvoigt.bsky.social and Kaize Ding.
Uses machine learning to study literary imagination, and vice-versa. Likely to share news about AI & computational social science / Sozialwissenschaft / 社会科学
Information Sciences and English, UIUC. Distant Horizons (Chicago, 2019). tedunderwood.com
Incoming Asst Prof @UMD Info College, currently postdoc @UChicago. NLP, computational social science, political communication, linguistics. Past: Info PhD @UMich, CS + Lx @Stanford. Interests: cats, Yiddish, talking to my cats in Yiddish.
Assistant Professor @ UChicago CS & DSI UChicao
Leading Conceptualization Lab http://conceptualization.ai
Minting new vocabulary to conceptualize generative models.
CS professor at NYU. Large language models and NLP. he/him
Senior applied scientist @Microsoft | PhD from @UChicagoCS | Build LLM copilot for group communications.
PhD @UChicagoCS / BE in CS @Umich / ✨AI/NLP transparency and interpretability/📷🎨photography painting
Doctor of NLP/Vision+Language from UCSB
Evals, metrics, multilinguality, multiculturality, multimodality, and (dabbling in) reasoning
https://saxon.me/
Entrepreneur, pursuer of noise in neurosciences, mechanistical interpretability and interventions in "AI", complexity, concentrated on practical applications of theoretically working solutions. Deeptech, startups.
Anything multiscale itterative nonlinear
A team of three human PIs—Ari Holtzman, Mina Lee, and Chenhao Tan studying and building the new information ecosystem of humans and machines. https://substack.com/@cichicago, https://ci.cs.uchicago.edu/
nlp phd student at uchicago cs
Computer Science PhD student at UChicago | Member of the Chicago Human+AI lab @chicagohai.bsky.social
Professor at UW; Researcher at Meta. LMs, NLP, ML. PNW life.
The 2025 Conference on Language Modeling will take place at the Palais des Congrès in Montreal, Canada from October 7-10, 2025
https://chicagohai.github.io/, https://substack.com/@cichicago
Breakthrough AI to solve the world's biggest problems.
› Join us: http://allenai.org/careers
› Get our newsletter: https://share.hsforms.com/1uJkWs5aDRHWhiky3aHooIg3ioxm
Assistant professor, research scientist | boosting scientific discovery with AI, NLP, IR, KG, HCI | @ai2.bsky.social
Ph.D. Student at the University of Chicago | Chicago Human + AI Lab
haokunliu.com
International Conference on Learning Representations https://iclr.cc/