Image of robots struggling with a social dilemma.
1/ Why does RL struggle with social dilemmas? How can we ensure that AI learns to cooperate rather than compete?
Introducing our new framework: MUPI (Embedded Universal Predictive Intelligence) which provides a theoretical basis for new cooperative solutions in RL.
Preprint🧵👇
(Paper link below.)
03.12.2025 19:19 — 👍 65 🔁 26 💬 5 📌 5
In this piece for @thetransmitter.bsky.social, I argue that ecological neuroscience should leverage generative video and interactive models to simulate the world from animals' perspectives.
The technological building blocks are almost here - we just need to align them for this application.
🧠🤖
08.12.2025 15:59 — 👍 40 🔁 14 💬 0 📌 1

Hope to see you at the @neuripsconf.bsky.social @dataonbrainmind.bsky.social Workshop! I will presenting our poster “Massively Parallel Imitation Learning of Mouse Forelimb Musculoskeletal Reaching Dynamics” @talmo.bsky.social @eazim.bsky.social Dec 7, SDCC 🦾🧠
arxiv.org/abs/2511.21848
04.12.2025 19:44 — 👍 5 🔁 2 💬 0 📌 1

🚨Our work was accepted to the @neuripsconf.bsky.social : Data on the Brain & Mind workshop!🧠🦾"Massively Parallel Imitation Learning of Mouse Forelimb Musculoskeletal Reaching Dynamics" @talmo.bsky.social @eazim.bsky.social
An imitation learning framework for modeling mouse forelimb control. 1/3
28.11.2025 17:01 — 👍 11 🔁 3 💬 1 📌 0

Talmo Lab is at @sfn.org! Come check out our latest work!
#neuroskyence #neurosky #SfN2025 #SfN25
15.11.2025 22:13 — 👍 17 🔁 6 💬 0 📌 1

New paper titled "Tracing the Representation Geometry of Language Models from Pretraining to Post-training" by Melody Z Li, Kumar K Agrawal, Arna Ghosh, Komal K Teru, Adam Santoro, Guillaume Lajoie, Blake A Richards.
LLMs are trained to compress data by mapping sequences to high-dim representations!
How does the complexity of this mapping change across LLM training? How does it relate to the model’s capabilities? 🤔
Announcing our #NeurIPS2025 📄 that dives into this.
🧵below
#AIResearch #MachineLearning #LLM
31.10.2025 16:19 — 👍 60 🔁 12 💬 1 📌 4
Over the past year, my lab has been working on fleshing out theory + applications of the Platonic Representation Hypothesis.
Today I want to share two new works on this topic:
Eliciting higher alignment: arxiv.org/abs/2510.02425
Unpaired learning of unified reps: arxiv.org/abs/2510.08492
1/9
10.10.2025 22:13 — 👍 131 🔁 32 💬 1 📌 5

The curriculum effect in visual learning: the role of readout dimensionality
Generalization of visual perceptual learning (VPL) to unseen conditions varies across tasks. Previous work suggests that training curriculum may be integral to generalization, yet a theoretical explan...
🚨 New preprint alert!
🧠🤖
We propose a theory of how learning curriculum affects generalization through neural population dimensionality. Learning curriculum is a determining factor of neural dimensionality - where you start from determines where you end up.
🧠📈
A 🧵:
tinyurl.com/yr8tawj3
30.09.2025 14:25 — 👍 77 🔁 25 💬 1 📌 2
A big congratulations to my supervisor for this awesome achievement. Excited to see where this will go!
23.09.2025 16:27 — 👍 3 🔁 0 💬 0 📌 0
5) Finally, I don't use it for writing as much as my peers. But its quite nice asking it how to say things like "this is best exemplified by..." in a different way so I don't repeat the same thing a million times in my paper or scholarship application.
04.09.2025 15:57 — 👍 1 🔁 0 💬 0 📌 0
4) Insofar as idea synthesis, I find my conversations with LLMs about as useful as talking to a layman with decent critical thinking skills and access to google. Its nice to bounce ideas off it at 1am when my colleagues may be asleep. But conversing with other academics is still by far more useful.
04.09.2025 15:54 — 👍 2 🔁 0 💬 1 📌 0
3) I am very grateful I learned how to code before the advent of LLMs. I think there's a real concern of new students relying too heavily on LLMs for coding, foregoing the learning process. At least for the time being, in order to use LLMs effectively, one still needs a strong foundation in coding.
04.09.2025 15:51 — 👍 1 🔁 0 💬 1 📌 0
2) When I start coding new projects, getting copilot to draft up the initial commit saves me loads of time. Of course there will be quite a few errors and/or silly coding structure. But I find tracing through the logic and making necessary corrections to be quicker than starting from scratch
04.09.2025 15:48 — 👍 1 🔁 0 💬 1 📌 0
I'm a graduate student breaking into the field of ML from physics.
1) I find LLMs useful insofar as gaining a basic understanding of new concepts. However going past a basic understanding still requires delving deep into the literature. I find the back-and-forth tutor style conversations useful.
04.09.2025 15:40 — 👍 1 🔁 0 💬 1 📌 0

🧵 Everyone is chasing new diffusion models—but what about the representations they model from?
We introduce Discrete Latent Codes (DLCs):
- Discrete representation for diffusion models
- Uncond. gen. SOTA FID (1.59 on ImageNet)
- Compositional generation
- Integrates with LLM
🧱
22.07.2025 14:41 — 👍 5 🔁 3 💬 1 📌 0

New preprint! 🧠🤖
How do we build neural decoders that are:
⚡️ fast enough for real-time use
🎯 accurate across diverse tasks
🌍 generalizable to new sessions, subjects, and even species?
We present POSSM, a hybrid SSM architecture that optimizes for all three of these axes!
🧵1/7
06.06.2025 17:40 — 👍 53 🔁 24 💬 2 📌 8

Preprint Alert 🚀
Can we simultaneously learn transformation-invariant and transformation-equivariant representations with self-supervised learning?
TL;DR Yes! This is possible via simple predictive learning & architectural inductive biases – without extra loss terms and predictors!
🧵 (1/10)
14.05.2025 12:52 — 👍 51 🔁 16 💬 1 📌 5
This can be a game changer for embodied #NeuroAI.
Or it *could* be, if it were open source.
Just imagine the resources it takes to develop an open version of this model. Now think about how much innovation could come from building on this, rather than just trying to recreate it (at best).
04.12.2024 17:01 — 👍 37 🔁 8 💬 3 📌 0
See my inner physicist hates the whole "doesn't matter as long as it works" sentiment in the ML community 😂. I want to UNDERSTAND not just accept... jokes aside though I see your point for the purposes of this discussion. I think we've identified a lot of potential in this stream of inquiry 🧐
22.11.2024 21:43 — 👍 1 🔁 0 💬 1 📌 0
That's somewhat along the lines of what I was thinking as well :)
Also good point about o1. I'd be very interested to see how it performs on the ToM tests!
22.11.2024 21:31 — 👍 1 🔁 0 💬 0 📌 0
Give the results and discussion a read as well it's super interesting! There's reason to believe perfect performance of Llama on the faux pas test was illusory (expanded upon in the discussion). That bias you mention is also elaborated upon in the discussion (and I briefly summarize above).
22.11.2024 21:30 — 👍 1 🔁 0 💬 1 📌 0
This all now begs the question of whether this makes LLMs more or less competent as practitioners of therapy. I think good arguments could be made for both perspectives. 🧵/fin
22.11.2024 20:37 — 👍 2 🔁 0 💬 1 📌 0
This fact is of course unsurprising (as the authors admit) since humanity's embodiment has placed evolutionary pressure on resolving these uncertainties (i.e. to fight or to flee). This dis-embodiment of LLMs could prevent their commitment to the most likely explanation. 🧵/2
22.11.2024 20:36 — 👍 1 🔁 0 💬 1 📌 0
I stand corrected. However, LLM's failure at the faux pas test underscores the need for further discussion. The failure: "not comput[ing] [mentalistic-like] inferences spontaneously to reduce uncertainty". LLMs are good at emulating human-responses, but the underlying cognition is different. 🧵/1
22.11.2024 20:35 — 👍 1 🔁 0 💬 1 📌 0
I'd argue that until LLMs can implement theory of mind, they'd be much better at diagnostic-oriented therapy. Being able to truly understand a human, form hypotheses, and guide a patient towards resolution is very different from recommending treatment based off a checklist made using the DSM.
22.11.2024 15:26 — 👍 3 🔁 0 💬 1 📌 0
1/ I work in #NeuroAI, a growing field of research, which many people have only the haziest conception of...
As way of introduction to this research approach, I'll provide here a very short thread outlining the definition of the field I gave recently at our BRAIN NeuroAI workshop at the NIH.
🧠📈
21.11.2024 16:20 — 👍 167 🔁 48 💬 8 📌 12
I'm making an unofficial starter pack with some of my colleagues at Mila. WIP for now but here's the link!
go.bsky.app/BHKxoss
20.11.2024 15:19 — 👍 70 🔁 29 💬 8 📌 1
Mind if I wiggle my way into this 🐛
20.11.2024 16:16 — 👍 1 🔁 0 💬 1 📌 0
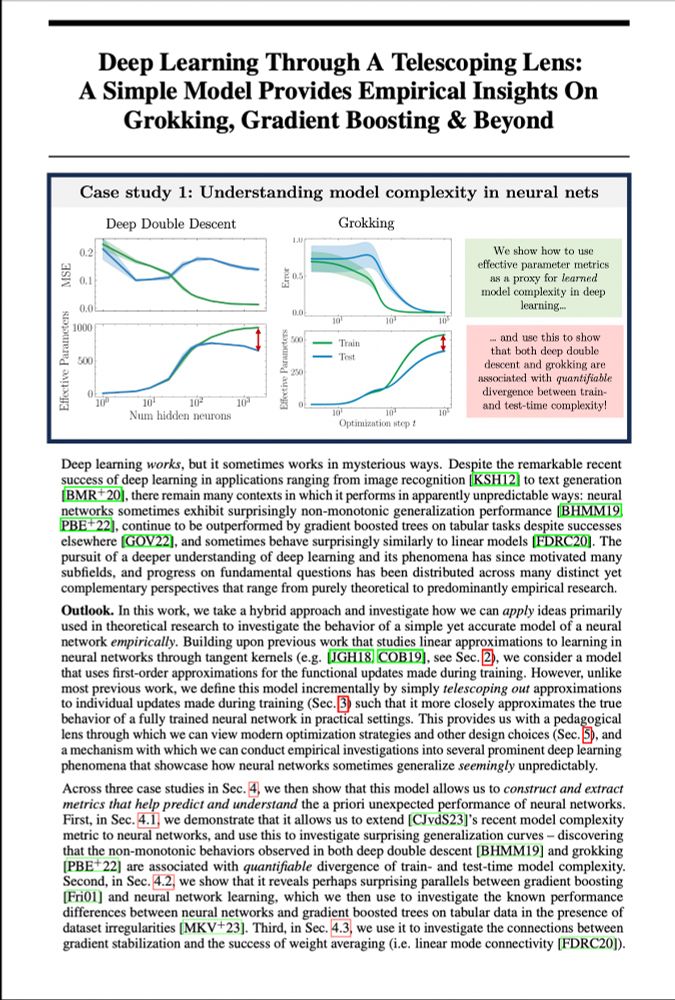
From double descent to grokking, deep learning sometimes works in unpredictable ways.. or does it?
For NeurIPS(my final PhD paper!), @alanjeffares.bsky.social & I explored if&how smart linearisation can help us better understand&predict numerous odd deep learning phenomena — and learned a lot..🧵1/n
18.11.2024 19:25 — 👍 174 🔁 35 💬 7 📌 7
Robotics PhD student at CMU | Humanoid Control, Perception, and Behavior.
zhengyiluo.com
Postdoc Salk Institute http://talmolab.org / PhD Cog Sci UCSD #Neuroscience #Behavior #BodyHorror #MachineLearning #Embodiment #Dynamics ericleonardis.github.io
Associate Professor in EECS at MIT. Neural nets, generative models, representation learning, computer vision, robotics, cog sci, AI.
https://web.mit.edu/phillipi/
A business analyst at heart who enjoys delving into AI, ML, data engineering, data science, data analytics, and modeling. My views are my own.
You can also find me at threads: @sung.kim.mw
Exploring the foundations of trust.
Neurophysiologist working on motor control and neural population dynamics. Assistant Prof. at the Case Western Reserve University School of Medicine.
https://sauerbreilab.org/
Father, son, husband, brother, friend. Also runs a lab.
Neuroscience PhD student at McGill
Co-supervised by Adrien Peyrache & Blake Richards
Ph.D. Student @mila-quebec.bsky.social and @umontreal.ca, AI Researcher
PI @ Salk Institute → talmolab.org | PhD @Princeton | BS @ UMBC
Quantifying biological motion with sleap.ai
Graduate student, Clinical Psychology & Neuropsychology @ York University
Professor @ Université de Montreal & Canada Research Chair in Comp Neuroscience & Cog Neuroimaging. Director of the Quebec Neuro-AI research center (UNIQUE Centre) | Biological & Artificial Cognition | Consciousness | Creativity | 🧠🤖 he/him
https://mcgill-nlp.github.io/people/
AI Scientist at Xaira Therapeutics & PhD student at Mila
graduate researcher at McGill/MILA, unlearning and privacy
PhD candidate at Mila, formerly Google eng, Brown University. Making LLMs explorative, adaptive, and goal-oriented
CS Faculty at Mila and McGill, interested in Graphs and Complex Data, AI/ML, Misinformation, Computational Social Science and Online Safety
#RL Postdoc at Mila - Quebec AI Institute and Université de Montréal