Almost 5 years in the making... "Hyperparameter Optimization in Machine Learning" is finally out! 📘
We designed this monograph to be self-contained, covering: Grid, Random & Quasi-random search, Bayesian & Multi-fidelity optimization, Gradient-based methods, Meta-learning.
arxiv.org/abs/2410.22854
17.12.2025 09:54 — 👍 13 🔁 8 💬 0 📌 0

🚨 New preprint: How well do universal ML potentials perform in biomolecular simulations under realistic conditions?
There's growing excitement around ML potentials trained on large datasets.
But do they deliver in simulations of biomolecular systems?
It’s not so clear. 🧵
1/
15.08.2025 08:29 — 👍 5 🔁 1 💬 1 📌 0
Demokratische Kontrolle von KI und Abschätzung von Nutzen und Gefahren ist extrem wichtig. Eine Politisierung von Technologien und eine damit verbundene Technologiefeindlichkeit ist eine extrem schlechte Idee.
29.05.2025 07:27 — 👍 0 🔁 0 💬 1 📌 0
Statt steiler Thesen über „faschistoide KI“ und Eugenik braucht es empirische Forschung: Was denken KI-Forschende und Unternehmen wirklich? Wie lässt sich Missbrauch wirksam begrenzen? Einzelmeinungen wie die von Musk zum Mainstream zu erklären, schafft nur ideologische Zerrbilder.
29.05.2025 07:09 — 👍 1 🔁 0 💬 1 📌 0
Anji is an amazing mentor and colleague. If I could go for another PhD in CS I would apply!
17.05.2025 17:31 — 👍 8 🔁 1 💬 0 📌 0
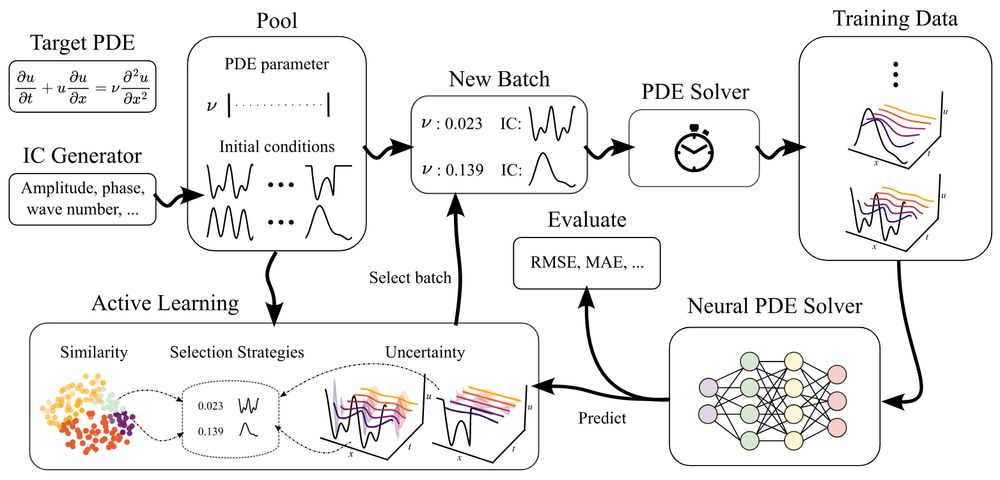
🚨ICLR poster in 1.5 hours, presented by @danielmusekamp.bsky.social :
Can active learning help to generate better datasets for neural PDE solvers?
We introduce a new benchmark to find out!
Featuring 6 PDEs, 6 AL methods, 3 architectures and many ablations - transferability, speed, etc.!
24.04.2025 00:38 — 👍 11 🔁 2 💬 1 📌 0
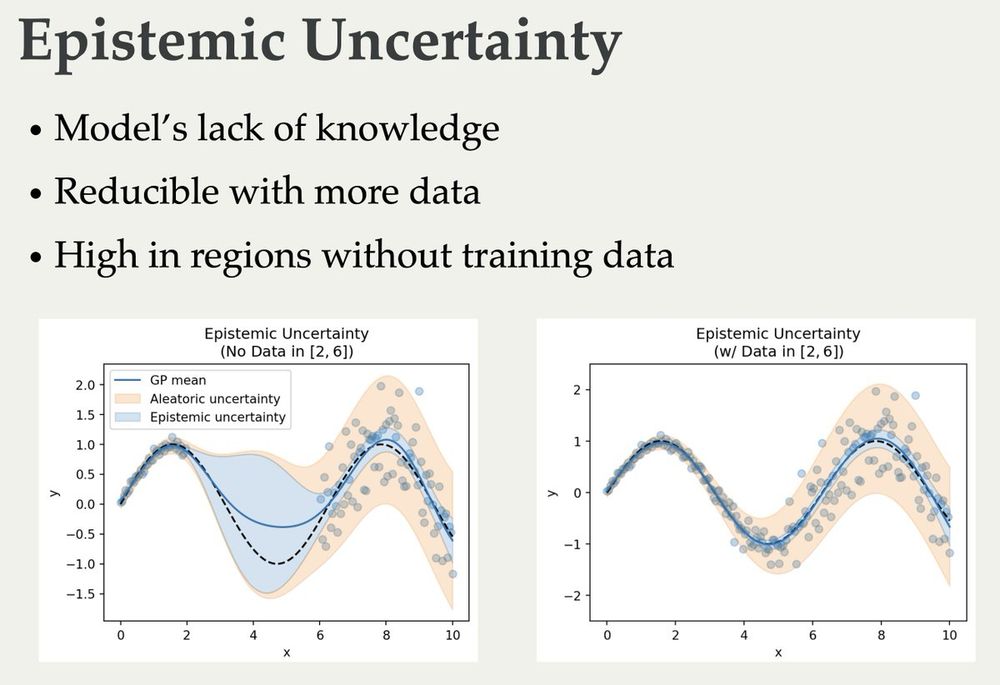
The slides for my lectures on (Bayesian) Active Learning, Information Theory, and Uncertainty are online now 🥳 They cover quite a bit from basic information theory to some recent papers:
blackhc.github.io/balitu/
and I'll try to add proper course notes over time 🤗
17.12.2024 06:50 — 👍 177 🔁 28 💬 3 📌 0
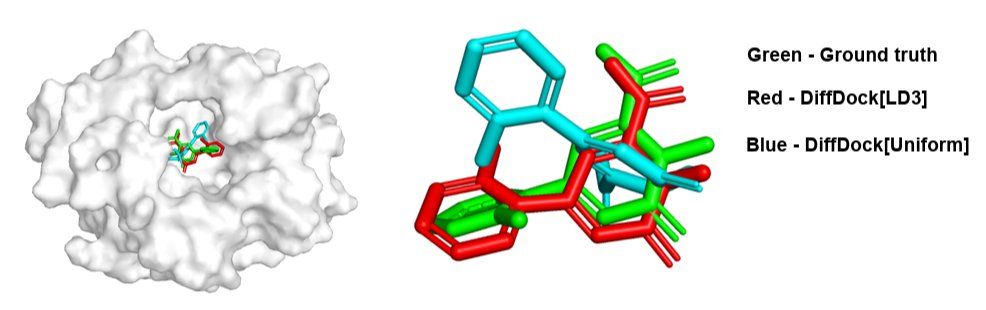
[9/n] Beyond Image Generation
LD3 can be applied to diffusion models in other domains, such as molecular docking.
13.02.2025 08:30 — 👍 0 🔁 1 💬 1 📌 0
Want to turn your state-of-the-art diffusion models into ultra-fast few-step generators? 🚀
Learn how to optimize your time discretization strategy—in just ~10 minutes! ⏳✨
Check out how it's done in our Oral paper at ICLR 2025 👇
13.02.2025 08:44 — 👍 15 🔁 4 💬 0 📌 0
Home - ComBayNS 2025 Workshop @ IJCNN 2025
Welcome to our Bluesky account! 🦋
We're excited to announce ComBayNS workshop: Combining Bayesian & Neural Approaches for Structured Data 🌐
Submit your paper and join us in Rome for #IJCNN2025! 🇮🇹
📅 Papers Due: March 20th, 2025 📜
Webpage: combayns2025.github.io
13.02.2025 09:18 — 👍 9 🔁 4 💬 0 📌 1

🚀 Exciting news! Our paper "Learning to Discretize Diffusion ODEs" has been accepted as an Oral at #ICLR2025! 🎉
[1/n]
We propose LD3, a lightweight framework that learns the optimal time discretization for sampling from pre-trained Diffusion Probabilistic Models (DPMs).
13.02.2025 08:30 — 👍 12 🔁 1 💬 1 📌 1
Very excited to announce the Neurosymbolic Generative Models special track at NeSy 2025! Looking forward to all your submissions!
20.12.2024 20:43 — 👍 20 🔁 3 💬 0 📌 0

Catch my poster tomorrow at the NeurIPS MLSB Workshop! We present a simple (yet effective 😁) multimodal Transformer for molecules, supporting multiple 3D conformations & showing promise for transfer learning.
Interested in molecular representation learning? Let’s chat 👋!
15.12.2024 00:31 — 👍 10 🔁 2 💬 0 📌 0
We will run out of data for pretraining and see diminishing returns. In many application domains such as in the sciences we also have to be very careful on what data we pretrain to be effective. It is important to adaptively generate new data from physical simulators. Excited about the work below
14.12.2024 13:02 — 👍 9 🔁 1 💬 0 📌 0
I'll present our paper in the afternoon poster session at 4:30pm - 7:30 pm in East Exhibit Hall A-C, poster 3304!
12.12.2024 18:54 — 👍 3 🔁 2 💬 0 📌 0
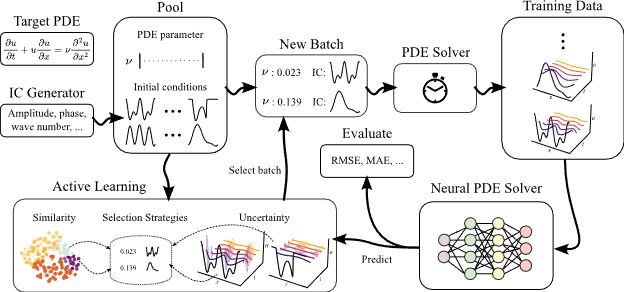
Neural surrogates can accelerate PDE solving but need expensive ground-truth training data. Can we reduce the training data size with active learning (AL)? In our NeurIPS D3S3 poster, we introduce AL4PDE, an extensible AL benchmark for autoregressive neural PDE solvers. 🧵
11.12.2024 18:22 — 👍 12 🔁 3 💬 1 📌 2
Join us today at #NeurIPS2024 for our poster presentation:
Higher-Rank Irreducible Cartesian Tensors for Equivariant Message Passing
🗓️ When: Wed, Dec 11, 11 a.m. – 2 p.m. PST
📍 Where: East Exhibit Hall A-C, Poster #4107
#MachineLearning #InteratomicPotentials #Equivariance #GraphNeuralNetworks
11.12.2024 15:38 — 👍 5 🔁 1 💬 0 📌 0

Transferability of atom-based neural networks - IOPscienceSearch
Transferability of atom-based neural networks, Frederik Ø Kjeldal, Janus J Eriksen
"Transferability of atom-based neural networks" authored by @januseriksen.bsky.social (thanks for publishing with us, amazing work!) is now out as part of the #QuantumChemistry and #ArtificialIntelligence focus collection #MachineLearningScienceandTechnology. Link: iopscience.iop.org/article/10.1...
10.12.2024 20:06 — 👍 6 🔁 2 💬 0 📌 0
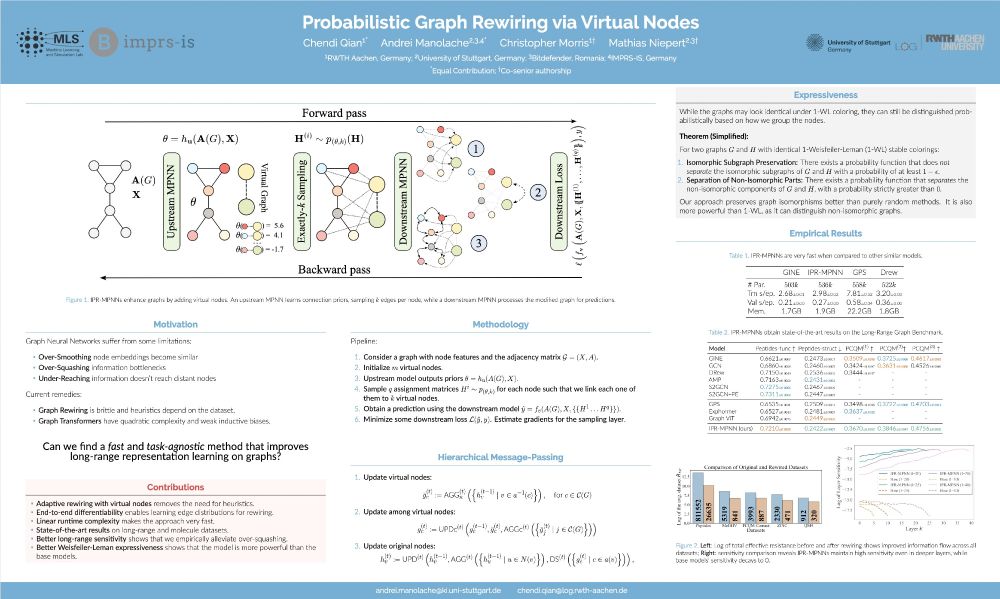
1/6 We're excited to share our #NeurIPS2024 paper: Probabilistic Graph Rewiring via Virtual Nodes! It addresses key challenges in GNNs, such as over-squashing and under-reaching, while reducing reliance on heuristic rewiring. w/ Chendi Qian, @christophermorris.bsky.social @mniepert.bsky.social 🧵
07.12.2024 17:50 — 👍 30 🔁 7 💬 1 📌 0

Transferability of atom-based neural networks - IOPscienceSearch
Transferability of atom-based neural networks, Frederik Ø Kjeldal, Janus J Eriksen
New #compchem paper out in MLST. We study the transferability of both invariant and equivariant neural networks when training these either exclusively on total molecular energies or in combination with data from different atomic partitioning schemes:
iopscience.iop.org/article/10.1...
07.12.2024 08:49 — 👍 24 🔁 5 💬 0 📌 0
You should take a look at this if you want to know how to use Cartesian (instead of spherical) tensors for building equivariant MLIPs.
06.12.2024 14:57 — 👍 11 🔁 2 💬 0 📌 0

📣 Can we go beyond state-of-the-art message-passing models based on spherical tensors such as #MACE and #NequIP?
Our #NeurIPS2024 paper explores higher-rank irreducible Cartesian tensors to design equivariant #MLIPs.
Paper: arxiv.org/abs/2405.14253
Code: github.com/nec-research...
06.12.2024 14:45 — 👍 13 🔁 2 💬 2 📌 2
Efficient Learning of Discrete-Continuous Computation Graphs
We analyzed the behavior of Gumbel softmax in complex stochastic computation graphs. It’s a combination of vanishing gradients and a tendency to fall into poor local minima, underutilizing available categories. We also have some ideas for improvements. proceedings.neurips.cc/paper/2021/h...
30.11.2024 10:51 — 👍 21 🔁 2 💬 0 📌 0
@ropeharz.bsky.social forced me to do this starter pack on #tractable #probabilistic modeling and #reasoning in #AI and #ML
please write below if you want to be added (and sorry if I did not find you from the beginning).
go.bsky.app/DhVNyz5
29.11.2024 13:11 — 👍 51 🔁 15 💬 11 📌 0
BilateralAI – Bilateral AI – Cluster of Excellence
Amazing opportunity for #Neurosymbolic folks! 🚨🚨🚨
We are looking for a Tenure Track Prof for the 🇦🇹 #FWF Cluster of Excellence Bilateral AI (think #NeSy ++) www.bilateral-ai.net A nice starting pack for fully funded PhDs is included.
jobs.tugraz.at/en/jobs/226f...
28.11.2024 10:42 — 👍 15 🔁 11 💬 3 📌 2
🙋♂️
27.11.2024 07:02 — 👍 1 🔁 0 💬 0 📌 0
I haven’t read it carefully, but +1 to works like the one below. It mentions learning artifacts from discreetness. We saw some things like that in this paper, where bad integration of the true Hamiltonian did worse than a learned model (that absorbed artifacts).
arxiv.org/abs/1909.12790
26.11.2024 13:17 — 👍 27 🔁 2 💬 0 📌 0
🙋♂️
24.11.2024 18:39 — 👍 1 🔁 0 💬 1 📌 0
Research Scientist at Google DeepMind interested in science.
Views here are my own.
https://www.nowozin.net/sebastian/
Associate professor (Reader) at Edinburgh, Informatics. Networking, security & systems research. Ex-NetApp. Foodie. Dad. 🏴🇬🇧←🇩🇪←🇯🇵
https://micchie.net
Associate Prof at EURECOM and 3IA Côte d'Azur Chair of Artificial Intelligence. ELLIS member.
Data management and NLP/LLMs for information quality.
https://www.eurecom.fr/~papotti/
The European Association for Artificial Intelligence (EurAI, formerly ECCAI) is the representative body for the European AI research community.
eurai.org
Assistant prof at Columbia IEOR developing AI for decision-making in planetary health.
https://lily-x.github.io
Assistant Prof @ImperialCollege. Applied Bayesian inference, spatial stats and deep generative models for epidemiology. Passionate about probabilistic programming: check out my evolving #Numpyro course: https://elizavetasemenova.github.io/prob-epi 🚀
Researching planning, reasoning, and RL in LLMs @ Reflection AI. Previously: Google DeepMind, UC Berkeley, MIT. I post about: AI 🤖, flowers 🌷, parenting 👶, public transit 🚆. She/her.
http://www.jesshamrick.com
Science Management, DEI, and Communication at University of Stuttgart | PhD in Astronomy | He/Him
Machine Learning Researcher | Trying to unbox black-boxes.
Combining Bayesian and Neural approaches for Structured Data.
ComBayNS workshop @ IJCNN 2025 Conference, Rome, June 30-July 2 2025.
Postdoc @harvard.edu @kempnerinstitute.bsky.social
Homepage: http://satpreetsingh.github.io
Twitter: https://x.com/tweetsatpreet
Professor, University of Tübingen @unituebingen.bsky.social.
Head of Department of Computer Science 🎓.
Faculty, Tübingen AI Center 🇩🇪 @tuebingen-ai.bsky.social.
ELLIS Fellow, Founding Board Member 🇪🇺 @ellis.eu.
CV 📷, ML 🧠, Self-Driving 🚗, NLP 🖺
Reader in Computer Vision and Machine Learning @ School of Informatics, University of Edinburgh.
https://homepages.inf.ed.ac.uk/omacaod
Google Chief Scientist, Gemini Lead. Opinions stated here are my own, not those of Google. Gemini, TensorFlow, MapReduce, Bigtable, Spanner, ML things, ...
RS at Nvidia focussing on autonomous vehicles, simulation and RL. Opinions my own and do not represent those of my employer, Nvidia.
Sr. ML Eng. @ PayPal's GFP ML R&D.
Formerly Assistant Research Professor, Computational Research Accelerator, a supercomputing-adjacent unit @ Arizona State University. PhD Applied Math. on stratified fluid flows.
math.la.asu.edu/~yalim
Views my own
Scientist and engineer in ai/ml
Http://feisha.org
phd student @geneva, ML+physics
https://balintmate.github.io