[10/10] Wrap-up 🎯
🔹 Unified supervised + unsupervised hashing
🔹 Flexible: works via probing or LoRA
🔹 SOTA hashing in minutes on a single GPU
📄 Paper: arxiv.org/abs/2510.27584
💻 Code: github.com/ilyassmoumma...
Shoutout to my wonderful co-authors Kawtar, Hervé, and Alexis.
03.11.2025 14:31 — 👍 2 🔁 0 💬 0 📌 0
[9/10] Strong generalization 🌍
CroVCA produces compact codes that transfer efficiently:
✅ Single HashCoder trained on ImageNet-1k works on downstream datasets without retraining (More experiments and ablations in the paper)
03.11.2025 14:31 — 👍 0 🔁 0 💬 1 📌 0

[8/10] Semantically consistent retrieval 🔍
CroVCA retrieves correct classes even for fine-grained or ambiguous queries (e.g., indigo bird, grey langur).
✅ Outperforms Hashing-Baseline
✅ Works with only 16 bits and without supervision
03.11.2025 14:31 — 👍 0 🔁 0 💬 1 📌 0

[7/10] Compact yet meaningful codes 💾
Even with just 16 bits, CroVCA preserves class structure.
t-SNE on CIFAR-10 shows clear, separable clusters — almost identical to the original 768-dim embeddings.
03.11.2025 14:31 — 👍 0 🔁 0 💬 1 📌 0

[6/10] Strong performance across encoders 💪
Tested on multiple vision encoders (SimDINOv2, DINOv2, DFN…), CroVCA achieves SOTA unsupervised hashing:
03.11.2025 14:30 — 👍 0 🔁 0 💬 1 📌 0
[5/10] Fast convergence 🚀
CroVCA trains in just ~5 epochs:
✅ COCO (unsupervised) <2 min
✅ ImageNet100 (supervised) ~3 min
✅ Single GPU
Despite simplicity, it achieves state-of-the-art retrieval performance.
03.11.2025 14:30 — 👍 1 🔁 0 💬 1 📌 0

[4/10] HashCoder 🛠️
A lightweight MLP with final BatchNorm for balanced bits (inspired by OrthoHash). Can be used as:
🔹 Probe on frozen features
🔹 LoRA-based fine-tuning for efficient encoder adaptation
03.11.2025 14:30 — 👍 1 🔁 0 💬 1 📌 0

[3/10] Unifying hashing 🔄
Can supervised + unsupervised hashing be done in one framework?
CroVCA aligns binary codes across semantically consistent views:
Augmentations → unsupervised
Class-consistent samples → supervised
🧩 One BCE loss + coding-rate regularizer
03.11.2025 14:29 — 👍 1 🔁 1 💬 1 📌 0
[2/10] The challenge ⚡
Foundation models (DINOv3, DFN, SWAG…) produce rich embeddings, but similarity search in high-dimensional spaces is expensive.
Hashing provides fast Hamming-distance search, yet most deep hashing methods are complex, slow, and tied to a single paradigm.
03.11.2025 14:29 — 👍 1 🔁 0 💬 1 📌 0
[1/10] Introducing CroVCA ✨
A simple, unified framework for supervised and unsupervised hashing that converts foundation model embeddings into compact binary codes.
✅ Preserves semantic structure
✅ Trains in just a few iterations
03.11.2025 14:29 — 👍 3 🔁 0 💬 1 📌 0
I heard that the Linux client is buggy, I use it on the browser and it's working ok.
09.09.2025 07:03 — 👍 1 🔁 0 💬 1 📌 0
for the curious, the code, slides and the article are on Github: github.com/BastienPasde...
29.08.2025 11:44 — 👍 4 🔁 1 💬 0 📌 0
love it haha wish I were there to hear Prostitute Disfigurement in an amphitheater
29.08.2025 11:40 — 👍 1 🔁 0 💬 2 📌 0

NAVIGU: a powerful image collection explorer.
NAVIGU lets you dive into the ocean of images. Drag the image sphere or double-click on an image you like to browse large collections.
A website to visually browse and explore the ImageNet-1k dataset (there are other supported datasets: IN-12M, WikiMedia, ETH Images, Pixabay, Fashion) navigu.net#imagenet
(Maybe this is already known, but I was happy to discover it this morning)
27.08.2025 07:39 — 👍 0 🔁 0 💬 0 📌 0
Im interested in the quantum and footnotesize, how much params should they have 😂
23.08.2025 06:31 — 👍 0 🔁 0 💬 0 📌 0
Learning Deep Representations of Data Distributions
Landing page for the book Learning Deep Representations of Data Distributions.
Learning Deep Representations of Data Distributions
Sam Buchanan · Druv Pai · Peng Wang · Yi Ma
ma-lab-berkeley.github.io/deep-represe...
The best Deep Learning book is out, I've been waiting for its release for more than a year. Let's learn how to build intelligent systems via compression.
23.08.2025 06:27 — 👍 4 🔁 0 💬 0 📌 0
It feels like we can now fit more noise with more model capacity 🤔 (Figure 6), maybe we need newer architectures and/or newer training losses.
19.08.2025 21:36 — 👍 0 🔁 0 💬 0 📌 0
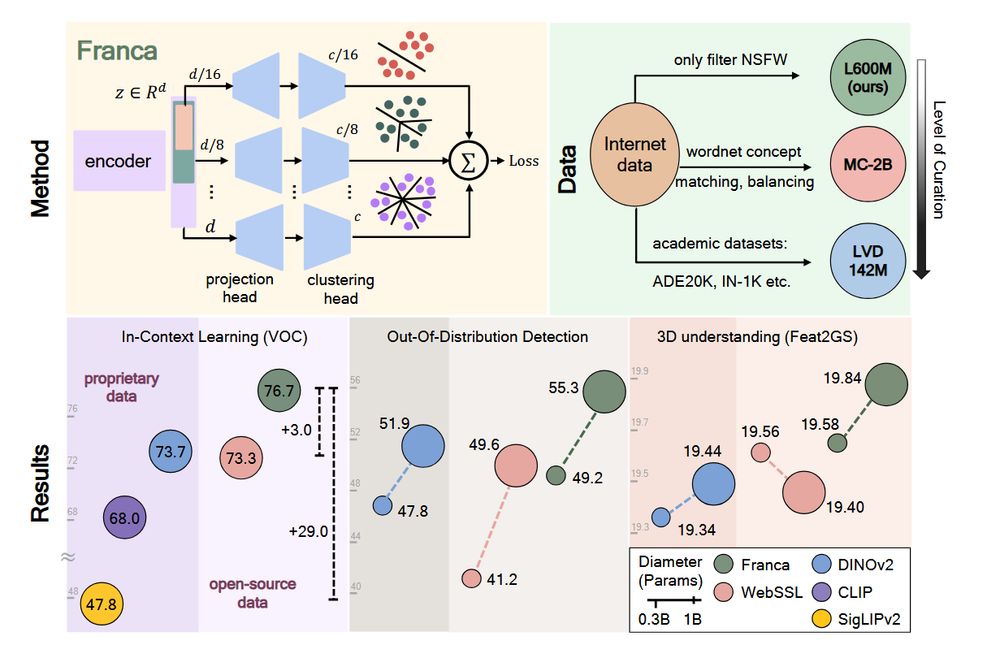
1/ Can open-data models beat DINOv2? Today we release Franca, a fully open-sourced vision foundation model. Franca with ViT-G backbone matches (and often beats) proprietary models like SigLIPv2, CLIP, DINOv2 on various benchmarks setting a new standard for open-source research.
21.07.2025 14:47 — 👍 85 🔁 21 💬 2 📌 3
👋 I worked on bioacoustics during my PhD, but I post mostly about AI
18.07.2025 20:56 — 👍 0 🔁 0 💬 0 📌 0
Congratz! 👏
03.07.2025 10:19 — 👍 0 🔁 0 💬 0 📌 0
YouTube video by Ne Obliviscaris - Topic
Of Petrichor Weaves Black Noise
my new addiction today: youtu.be/dSyJqwN36ow
I can't wait to see them this summer in Motocultor Festival
19.06.2025 09:54 — 👍 0 🔁 0 💬 0 📌 0
the best discovery I've had in recent years, I'm addicted to it now as well 😁
19.06.2025 07:12 — 👍 1 🔁 0 💬 1 📌 0
Thank you for making this accessible to everyone! I've read some sections, it is very instructive.
16.06.2025 10:08 — 👍 0 🔁 0 💬 0 📌 0

Foundations of Computer Vision
The print version was published by
Our computer vision textbook is now available for free online here:
visionbook.mit.edu
We are working on adding some interactive components like search and (beta) integration with LLMs.
Hope this is useful and feel free to submit Github issues to help us improve the text!
15.06.2025 15:45 — 👍 115 🔁 32 💬 3 📌 1

⚠️❗Open PhD and Postdoc positions in Prague with Lukas Neumann! ❗⚠️
We rank #5 in computer vision in Europe and Lukas is a great supervisor, so this is a great opportunity!
If you are interested, contact him, he will also be at CVPR with his group :)
09.06.2025 12:17 — 👍 14 🔁 5 💬 1 📌 0

We will be presenting the 🍄 FungiTastic 🍄, a multimodal, highly challenging dataset and benchmark covering many ML problems at @fgvcworkshop.bsky.social CVPR-W on Wednesday!
⏱️ 16:15
📍104 E, Level 1
📸 www.kaggle.com/datasets/pic...
📃 arxiv.org/abs/2408.13632
@cvprconference.bsky.social
06.06.2025 16:44 — 👍 18 🔁 6 💬 3 📌 0
One of the best conferences that I have been to, happy to have met old friends and having made new ones, hopefully future collaborations as well. Many thanks for organizing this 🙏
07.06.2025 00:37 — 👍 3 🔁 0 💬 1 📌 0

Want stronger Vision Transformers? Use octic-equivariant layers (arxiv.org/abs/2505.15441).
TLDR; We extend @bokmangeorg.bsky.social's reflection-equivariant ViTs to the (octic) group of 90-degree rotations and reflections and... it just works... (DINOv2+DeiT)
Code: github.com/davnords/octic-vits
23.05.2025 07:38 — 👍 29 🔁 4 💬 2 📌 3
The super friendly conference at the interface between statistics and ecology - happening in Mérida, México, on 8-15 January, 2027
https://statisticalecology.org
Header: Chichen Itza by User:Dronepicr is licensed under CC BY 3.0.
PhD student in computer vision at Imagine, ENPC
Postdoctoral researcher in ecology at FRB-Cesab @frbiodiv.bsky.social (she/her) | Data analysis 📊 | Dragonflies enthusiast | African ecology 🐘🦒🦓 | #camtrap 📸 | #SciComm 🌌
https://lisanicvert.github.io/
Powering R&I and bridging science, policy, & practice for the EU's 2030 Biodiversity Strategy | 83 partners from 41 countries | Protection & Restoration, Transnational monitoring, Nature-based Solutions, Transformative change
🔗 www.biodiversa.eu
Data analysis/signal & image processing #datascience #machinelearning #wavelet history of science. Terrible puns #radio #music #anagram. Opinions are nine
Canadian scientist living in Norway. Associate professor at the Norwegian University of Life Sciences, all 🐟 but especially salmonids, evolutionary ecology, aquatic ecology, Arctic, fisheries, eDNA, life-history, food-web, intraspecific variation.
European Research Council, set up by the EU, funds top researchers of any nationality, helping them pursue great ideas at the frontiers of knowledge. #HorizonEU
PhD at Charles University studying bioacoustics of Yellowhammers🎶
🚀Postdoc in Politecnico di Milano and EIEE/CMCC
🔍 I do research on AI for Vision, Graphics, Economics & Climate Change.
💻 https://carlosrodriguezpardo.es
Madrid ↔️ Milano
PhD Student at Carleton University (Ottawa, Canada)
https://antofuller.github.io/
Diffusion d'information pour l'association GRETSI : Groupe de Recherche et d’Études de Traitement du Signal et des Images (et disciples connexes)
PhD student @prfju.bsky.social @bioacousticai | Bioacoustics & bird conservation | Currently stalking Yellowhammers for science 🐤🔨🎶
PhD Student at MIT CSAIL Research AI for Scientific Discovery in Oceans
Prof bioacoustics, University of Saint-Etienne, Ecole Pratique des Hautes Etudes, Institut universitaire de France
Academia Europaea
Director ENES Bioacoustics Research Lab (http://eneslab.com)
Book @princetonupress.bsky.social: http://tinyurl.com/yuetutum
Postdoc at Kyutai
https://juliettemarrie.github.io
We work on planetary problems. Currently: counting climate change-related deaths; pandemic risk assessment in a changing biosphere; data, science, and vaccine access during public health emergencies. 👉 carlsonlab.bio
Lecturer and Researcher at La Salle Campus Barcelona - Ramon Llull University.
PhD in Acoustic Event Detection & Classification. I have worked on Bioacoustics. Now interested in the soundscapes of monasteries!
Researcher in machine learning, optimization, computer vision, image and signal processing





















