New work in why action chunking is so important for robot control (it helps fight compounding error)
arxiv.org/abs/2507.09061

@djfoster.bsky.social
Principal Researcher in AI/ML/RL Theory @ Microsoft Research NE/NYC. Previously @ MIT, Cornell. http://dylanfoster.net RL Theory Lecture Notes: https://arxiv.org/abs/2312.16730
New work in why action chunking is so important for robot control (it helps fight compounding error)
arxiv.org/abs/2507.09061

Building Olmo 3 Think
Foundations of Reasoning in Language Models @ NeurIPS 2025
Today 13:45 - 14:30

At #NeurIPS2025? Join us for a Social on Wednesday at 7 PM, featuring a fireside chat with Jon Kleinberg and mentoring tables.
Ft. mentors @djfoster.bsky.social @surbhigoel.bsky.social @aifi.bsky.social @gautamkamath.com and more!
(12/12) Paper link: www.arxiv.org/abs/2510.15020
Many interesting questions: What are the minimal conditions for RL success (maybe a more semantic notion of coverage)? Do other algos/interventions secretly have coverage-based interpretations?


(12/12) Another algo example: We give some tournament-style methods for selecting checkpoints (motivated by coverage) that can beat cross-entropy based selection. See figure, where coverage-based selection finds model w/ best BoN performance.
25.10.2025 16:21 — 👍 1 🔁 0 💬 1 📌 0
(10/12) Perhaps the coolest part: the coverage perspective seems to have non-trivial algo design consequences:
1. Vanilla SGD can have poor coverage; gradient normalization (a-la Adam) fixes this
2. Test-time training (SGD on tokens during generation) provably improves coverage
(9/12) We show this through two lenses:
1. New generalization analysis for next-token prediction/maximum likelihood for general function classes, in the vein of stat. learning.
2. SGD in the one-pass regime for overparameterized autoregressive linear models

(8/12) Our analysis is based on a phenomenon we call the coverage principle, where next-token prediction implicitly optimizes toward a model with good coverage.
Neat consequence: Coverage generalizes faster as we go further into tail (corresponding to more test-time compute)
(7/12) Example (see figure):
- Cross-entropy decreases throughout training.
- Coverage improves to a point, but begins to drop as the model learns a spurious shortcut.
- BoN performance follows trend of coverage, not CE (increasing initially, dropping as shortcut is learned).

(6/12) Our main result:
1) Next-token prediction (more generally, MLE) provably learns a model w/ good coverage, inheriting the training corpus’ coverage over tasks of interest.
2) Coverage generalizes *faster* than cross-entropy itself, and consequently can be more predictive.
(5/12) Example: For tasks that are well-represented in pre-training distribution, low Cov_N is necessary and sufficient for Best-of-N to succeed.
Empirically, some notion of coverage also seems necessary for current RL methods (eg arxiv.org/abs/2504.13837)
(4/12) Intuition: Cross-entropy (KL) tracks the mean of the log density ratio, while coverage profile tracks the *tail* or CDF via N.
N controls how far into tail we go, and roughly corresponds to test-time compute/RL effort. For downstream performance, the tail is what matters.

(3/12) Our answer is a quantity we call the *coverage profile*, which captures the extent to which the pre-trained model "covers" the pre-training distribution:
Cov_N = P_{π}[π(y|x)/\hat{π}(y|x) ≥ N],
(π is pre-training dist, \hat{π} is pre-trained model, N is a param)
(2/12) We wanted to take a first step toward developing some theoretical understanding of the relationship btw next-token prediction and downstream perf (particularly w/ test-time scaling).
Concretely, what metrics of the pre-trained model can we link to downstream success?

(1/12) Many have observed starting that from a better next‑token predictor (low cross-entropy) does not always give better downstream post-training/test-time perf. In some cases, CE can even be anti‑correlated with BoN success (see fig or arxiv.org/abs/2502.07154). Why is this?
25.10.2025 16:20 — 👍 0 🔁 0 💬 1 📌 0
Led by my amazing intern Fan Chen, with awesome team Audrey Huang (@ahahaudrey.bsky.social), Noah Golowich, Sadhika Malladi (@sadhika.bsky.social), Adam Block, Jordan Ash, and Akshay Krishnamurthy.
Paper: www.arxiv.org/abs/2510.15020
Thread below.

The coverage principle: How pre-training enables post-training
New preprint where we look at the mechanisms through which next-token prediction produces models that succeed at downstream tasks.
The answer involves a metric we call the "coverage profile", not cross-entropy.
(10/12) Perhaps the coolest part: the coverage perspective seems to have non-trivial algo design consequences:
1. Vanilla SGD can have poor coverage; gradient normalization (a-la Adam) fixes this
2. Test-time training (SGD on tokens during generation) provably improves coverage
Sorry about that! There was an issue where the application briefly closed early. Today is the deadline and it should be open again now.
22.10.2025 19:39 — 👍 1 🔁 0 💬 0 📌 0The new call for Motwani postdocs application is now open!
academicjobsonline.org/ajo/jobs/30865
BTW-
Not quite ready for a postdoc? We updated the TCS Masters programs spreadsheet:
www.cs.princeton.edu/~smattw/mast...
Any career stage and in the (SF) Bay Area?
Save the date for TOCA-SV on 11/7!
Lots of interesting directions here! We think there is a lot more to do building on the connection to the discrete sampling/TCS literature and algos from this space, as well as moving beyond autoregressive generation.
12.10.2025 16:25 — 👍 0 🔁 0 💬 0 📌 0
Empirically, we have only tried this w/ small-ish scale so far, but find consistently that VGB outperforms textbook algos on either (1) accuracy; or (2) diversity when compute-normalized. Ex: for Dyck language, VGB escapes the accuracy-diversity frontier for baselines algos.
12.10.2025 16:25 — 👍 0 🔁 0 💬 1 📌 0
Main guarantee:
- As long as you have exact/verifiable outcome rewards, always converges to optimal distribution.
- Runtime depends on process verifier quality, gracefully degrading as quality gets worse.

VGB generalizes the Sinclair–Jerrum '89 random walk (people.eecs.berkeley.edu/~sinclair/ap...)
from TCS (used to prove equivalence of apx. counting & sampling for self-reducible problems), linking test-time RL/alignment with discrete sampling theory. We are super excited about this connection.
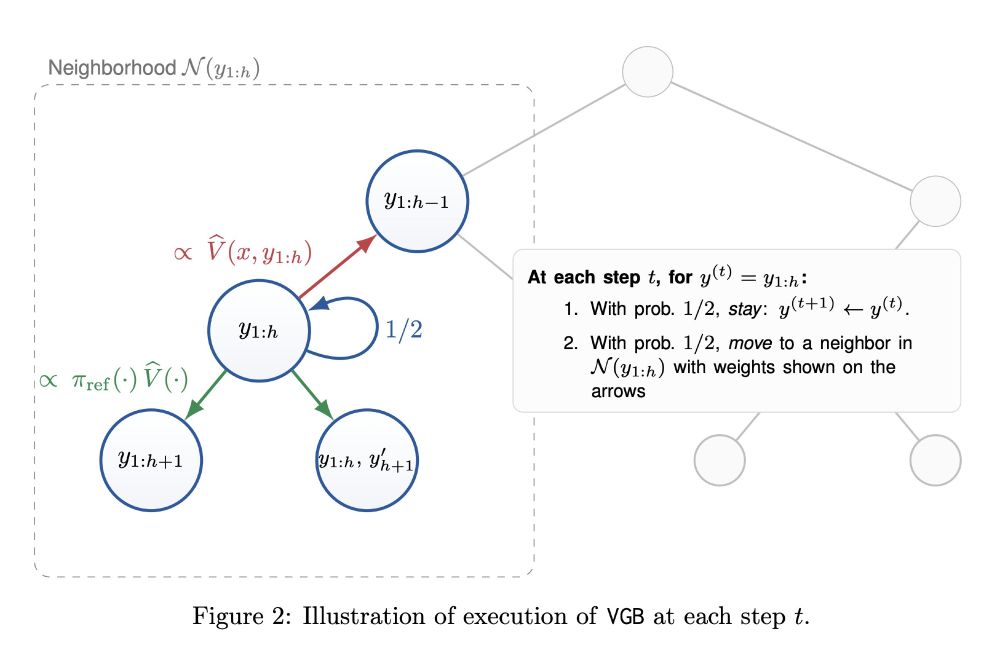

We give a new algo, Value-Guided Backtracking (VGB), where the idea is to view autoregressive generation as a random walk on the tree of partial outputs, and add a *stochastic backtracking* step—occasionally erasing tokens in a principled way—to counter error amplification.
12.10.2025 16:25 — 👍 0 🔁 0 💬 1 📌 0Test-time guidance with learned process verifiers has untapped potential to enhance language model reasoning, but one of the issues with getting this to actually work is that small verifier mistakes are amplified by textbook algos (e.g., block-wise BoN), w/ errors compounding as length increases.
12.10.2025 16:25 — 👍 0 🔁 0 💬 1 📌 0With amazing team: Dhruv Rohatgi, Abhishek Shetty, Donya Saless, Yuchen Li, Ankur Moitra, and Andrej Risteski (andrejristeski.bsky.social).
Short thread below.


Taming Imperfect Process Verifiers: A Sampling Perspective on Backtracking.
A totally new framework based on ~backtracking~ for using process verifiers to guide inference, w/ connections to approximate counting/sampling in theoretical CS.
Paper: www.arxiv.org/abs/2510.03149

MSR NYC is hiring spring and summer interns in AI/ML/RL!
Apply here: jobs.careers.microsoft.com/global/en/jo...

🚨Microsoft Research NYC is hiring🚨
We're hiring postdocs and senior researchers in AI/ML broadly, and in specific areas like test-time scaling and science of DL. Postdoc applications due Oct 22, 2025. Senior researcher applications considered on a rolling basis.
Links to apply: aka.ms/msrnyc-jobs