This blog post is a nice complementary, behind-the-scenes extra on our recent work about on-policy pathwise gradient algorithms. @cvoelcker.bsky.social went the extra mile, and wrote this piece to provide some more context on the design decisions behind REPPO!
03.10.2025 22:52 — 👍 2 🔁 0 💬 0 📌 0

a close up of a sad cat with the words pleeeaasse written below it
ALT: a close up of a sad cat with the words pleeeaasse written below it
cvoelcker.de/blog/2025/re...
I finally gave in and made a nice blog post about my most recent paper. This was a surprising amount of work, so please be nice and go read it!
02.10.2025 21:34 — 👍 29 🔁 7 💬 0 📌 3
Congrats igor! well deserved!! 🤗
01.10.2025 22:37 — 👍 1 🔁 0 💬 0 📌 0
Big if true 🤫: #REPPO works on Atari as well 😱 👾 🚀
Some tuning is still needed, but we are seeing results roughly on par with #PQN.
If you want to test out #REPPO (atari is not integrated due to issues with envpool and jax version), check out github.com/cvoelcker/re...
#reinforcementlearning
16.09.2025 13:29 — 👍 7 🔁 1 💬 1 📌 0
My wedding gift for you 😅
16.09.2025 20:51 — 👍 0 🔁 0 💬 0 📌 0
Super stoked for the New York RL workshop tomorrow. Will be presenting 2 orals:
* Replicable Reinforcement Learning with Linear Function Approximation
* Relative Entropy Pathwise Policy Optimization
We already posted about the 2nd one (below), I'll get to talking about the first one in a bit here.
11.09.2025 14:28 — 👍 5 🔁 2 💬 0 📌 0
I’ve been hearing about this paper from Claas for a while now, the fact that they aren’t tuning per benchmark is a killer sign. Also, check out the wall clock plots!
18.07.2025 20:15 — 👍 20 🔁 1 💬 1 📌 0
My PhD journey started with me fine-tuning hparams of PPO which ultimately led to my research on stability. With REPPO, we've made a huge step in the right direction. Stable learning, no tuning on a new benchmark, amazing performance. REPPO has the potential to be the PPO killer we all waited for.
17.07.2025 19:41 — 👍 7 🔁 2 💬 0 📌 0
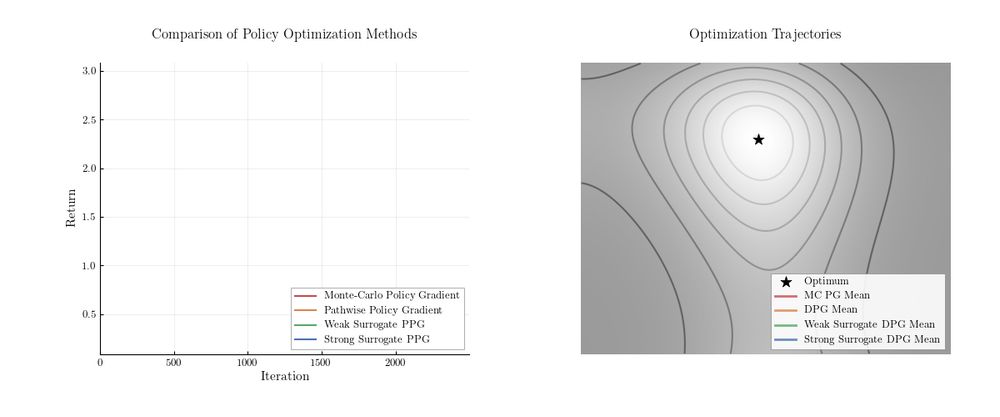
GIF showing two plots that symbolize the REPPO algorithm. On the left side, four curves track the return of an optimization function, and on the right side, the optimization paths over the objective function are visualized. The GIF shows that monte-carlo gradient estimators have a high variance and fail to converge, while surrogate function estimators converge smoothly, but might find suboptimal solutions if the surrogate function is imprecise.
🔥 Presenting Relative Entropy Pathwise Policy Optimization #REPPO 🔥
Off-policy #RL (eg #TD3) trains by differentiating a critic, while on-policy #RL (eg #PPO) uses Monte-Carlo gradients. But is that necessary? Turns out: No! We show how to get critic gradients on-policy. arxiv.org/abs/2507.11019
17.07.2025 19:11 — 👍 26 🔁 7 💬 2 📌 6
Awesome work!
06.02.2025 18:49 — 👍 2 🔁 0 💬 0 📌 0
My bet is on legacy.
05.12.2024 22:56 — 👍 0 🔁 0 💬 0 📌 0
PhD student at NYU | Building human-like agents | https://www.daphne-cornelisse.com/
The Vector Institute is dedicated to AI, excelling in machine & deep learning research. AI-generated content will be disclosed. FR: @institutvecteur.bsky.social
The Department of Computer Science at the University of Toronto.
Musician, math lover, cook, dancer, 🏳️🌈, and an ass prof of Computer Science at New York University
Chefredakteur @dietagespresse.com
Live-Programm https://dietagespresse.com/live/
Principal Scientist at Naver Labs Europe, Lead of Spatial AI team. AI for Robotics, Computer Vision, Machine Learning. Austrian in France. https://chriswolfvision.github.io/www/
PhD student at @dfki | @ias-tudarmstadt.bsky.social, working on RL 🤖 Previously master student at MVA @ENS_ParisSaclay | ENPC 🎓
Associate Prof @informatics.tuwien.ac.at, Music IR, RecSys, @unesco.org Chair on Digital Humanism, former Visiting Assistant Prof @ GATech
Assistant Professor TU Wien, previously Uni of Oxford | Research in #databasetheory, #AI & #GNNs
Unter dem Motto "Technik für Menschen" wird an der Technischen Universität Wien seit mehr als 200 Jahren geforscht, gelehrt und gelernt.
https://www.tuwien.at
Faculty of Informatics at TU Wien in Vienna, Austria
Principal Researcher in AI/ML/RL Theory @ Microsoft Research NE/NYC. Previously @ MIT, Cornell. http://dylanfoster.net
RL Theory Lecture Notes: https://arxiv.org/abs/2312.16730
Researching multi-agent RL, emergent communication, and evolutionary computation.
Postdoc at FLAIR Oxford. PhD from Safe and Trusted AI CDT @ KCL/Imperial. Previously visiting researcher at CHAI U.C. Berkeley.
dylancope.com
he/him
London 🇬🇧
Member of technical staff @periodiclabs
Open-source/open science advocate
Maintainer of torchrl / tensordict / leanrl
Former MD - Neuroscience PhD
https://github.com/vmoens
Ph.D. Student studying AI & decision making at Mila / McGill University. Currently at FAIR @ Meta. Previously Google DeepMind & Google Brain.
https://brosa.ca
PhDing @UCSanDiego @NVIDIA @hillbot_ai on scalable robot learning and embodied AI. Co-founded @LuxAIChallenge to build AI competitions. @NSF GRFP fellow
http://stoneztao.com
Group Leader in Tübingen, Germany
I’m 🇫🇷 and I work on RL and lifelong learning. Mostly posting on ML related topics.
PhD candidate @polimi | Reinforcement Learning @rl3polimi | I do stuff, I see stuff. Some with purpose, most by chance.
https://ricczamboni.github.io
CS prof at University of Waterloo and Research Scientist at Google DeepMind.























